ФЪЎ¶»щУЪFlumeөДГАНЕИХЦҫКХјҜПөНі(Т»)јЬ№№әНЙијЖЎ·ЦРЈ¬ОТГЗПкКцБЛ»щУЪFlumeөДГАНЕИХЦҫКХјҜПөНіөДјЬ№№ЙијЖЈ¬ТФј°ОӘКІГҙЧцХвСщөДЙијЖЎЈФЪұҫҪЪЦРЈ¬ОТГЗҪ«»бҪІКцФЪКөјКІҝКрәНК№УГ№эіМЦРУцөҪөДОКМвЈ¬¶ФFlumeөД№ҰДЬёДҪшәН¶ФПөНіЧцөДУЕ»ҜЎЈ
1 FlumeөДОКМвЧЬҪб
ФЪFlumeөДК№УГ№эіМЦРЈ¬УцөҪөДЦчТӘОКМвИзПВЈә
a. Channel“Л®НБІ»·ю”ЈәК№УГ№М¶ЁҙуРЎөДMemoryChannelФЪИХЦҫёЯ·еКұіЈұЁ¶УБРҙуРЎІ»№»өДТміЈЈ»К№УГFileChannelУЦөјЦВIO·ұГҰөДОКМвЈ»
b. HdfsSinkөДРФДЬОКМвЈәК№УГHdfsSinkПтHdfsРҙИХЦҫЈ¬ФЪёЯ·еКұјдЛЩ¶ИҪПВэЈ»
c. ПөНіөД№ЬАнОКМвЈәЕдЦГЙэј¶Ј¬ДЈҝйЦШЖфөИЈ»
2 FlumeөД№ҰДЬёДҪшәНУЕ»Ҝөг
ҙУЙПГжөДОКМвЦРҝЙТФҝҙөҪЈ¬УРТ»Р©РиЗуКЗФӯЙъFlumeОЮ·ЁВъЧгөДЈ¬ТтҙЛЈ¬»щУЪҝӘФҙөДFlumeОТГЗФцјУБЛРн¶а№ҰДЬЈ¬РЮёДБЛТ»Р©BugЈ¬ІўЗТҪшРРТ»Р©өчУЕЎЈПВГжҪ«¶ФТ»Р©ЦчТӘөД·ҪГжЧцТ»Р©ЛөГчЎЈ
2.1 ФцјУZabbix monitor·юОс
Т»·ҪГжЈ¬FlumeұҫЙнМṩБЛhttp, gangliaөДјаҝШ·юОсЈ¬¶шОТГЗДҝЗ°ЦчТӘК№УГzabbixЧцјаҝШЎЈТтҙЛЈ¬ОТГЗОӘFlumeМнјУБЛzabbixјаҝШДЈҝйЈ¬әНsaөДјаҝШ·юОсОЮ·мИЪәПЎЈ
БнТ»·ҪГжЈ¬ҫ»»ҜFlumeөДmetricsЎЈЦ»Ҫ«ОТГЗРиТӘөДmetrics·ўЛНёшzabbixЈ¬ұЬГв zabbix serverФміЙС№БҰЎЈДҝЗ°ОТГЗЧоОӘ№ШРДөДКЗFlumeДЬ·сј°Кұ°СУҰУГ¶Л·ўЛН№эАҙөДИХЦҫРҙөҪHdfsЙПЈ¬ ¶ФУҰ№ШЧўөДmetricsОӘЈә
- Source : ҪУКХөДeventКэәНҙҰАнөДeventКэ
- Channel : ChannelЦРУө¶ВөДeventКэ
- Sink : ТСҫӯҙҰАнөДeventКэ
2.2 ОӘHdfsSinkФцјУЧФ¶ҜҙҙҪЁindex№ҰДЬ
КЧПИЈ¬ОТГЗөДHdfsSinkРҙөҪhadoopөДОДјюІЙУГlzoС№ЛхҙжҙўЎЈ HdfsSinkҝЙТФ¶БИЎhadoopЕдЦГОДјюЦРМṩөДұаВлАаБРұнЈ¬И»әуНЁ№эЕдЦГөД·ҪКҪ»сИЎК№УГәОЦЦС№ЛхұаВлЈ¬ОТГЗДҝЗ°К№УГlzoС№ЛхКэҫЭЎЈІЙУГlzoС№Лх¶ш·Зbz2С№ЛхЈ¬КЗ»щУЪТФПВІвКФКэҫЭЈә
| eventҙуРЎ(Byte) | sink.batch-size | hdfs.batchSize | С№ЛхёсКҪ | ЧЬКэҫЭҙуРЎ(G) | әДКұ(s) | ЖҪҫщevents/s | С№ЛхәуҙуРЎ(G) |
|---|---|---|---|---|---|---|---|
| 544 | 300 | 10000 | bz2 | 9.1 | 2448 | 6833 | 1.36 |
| 544 | 300 | 10000 | lzo | 9.1 | 612 | 27333 | 3.49 |
ЖдҙОЈ¬ОТГЗөДHdfsSinkФцјУБЛҙҙҪЁlzoОДјюәуЧФ¶ҜҙҙҪЁindex№ҰДЬЎЈHadoopМṩБЛ¶ФlzoҙҙҪЁЛчТэЈ¬К№өГС№ЛхОДјюКЗҝЙЗР·ЦөДЈ¬ХвСщHadoop JobҝЙТФІўРРҙҰАнКэҫЭОДјюЎЈHdfsSinkұҫЙнlzoС№ЛхЈ¬ө«РҙНкlzoОДјюІўІ»»бҪЁЛчТэЈ¬ОТГЗФЪcloseОДјюЦ®әуМнјУБЛҪЁЛчТэ№ҰДЬЎЈ
1 /** 2 * Rename bucketPath file from .tmp to permanent location. 3 */ 4 private void renameBucket() throws IOException, InterruptedException { 5 if(bucketPath.equals(targetPath)) { 6 return; 7 } 8 9 final Path srcPath = new Path(bucketPath);10 final Path dstPath = new Path(targetPath);11 12 callWithTimeout(new CallRunner<Object>() {13 @Override14 public Object call() throws Exception {15 if(fileSystem.exists(srcPath)) { // could block16 LOG.info("Renaming " + srcPath + " to " + dstPath);17 fileSystem.rename(srcPath, dstPath); // could block18 19 //index the dstPath lzo file20 if (codeC != null && ".lzo".equals(codeC.getDefaultExtension()) ) {21 LzoIndexer lzoIndexer = new LzoIndexer(new Configuration());22 lzoIndexer.index(dstPath);23 }24 }25 return null;26 }27 });28 }
2.3 ФцјУHdfsSinkөДҝӘ№Ш
ОТГЗФЪHdfsSinkәНDualChannelЦРФцјУҝӘ№ШЈ¬өұҝӘ№ШҙтҝӘөДЗйҝцПВЈ¬HdfsSinkІ»ФЩНщHdfsЙПРҙКэҫЭЈ¬ІўЗТКэҫЭЦ»РҙПтDualChannelЦРөДFileChannelЎЈТФҙЛІЯВФАҙ·АЦ№HdfsөДХэіЈНЈ»ъО¬»ӨЎЈ
2.4 ФцјУDualChannel
FlumeұҫЙнМṩБЛMemoryChannelәНFileChannelЎЈMemoryChannelҙҰАнЛЩ¶ИҝмЈ¬ө«»әҙжҙуРЎУРПЮЈ¬ЗТГ»УРіЦҫГ»ҜЈ»FileChannelФтёХәГПа·ҙЎЈОТГЗПЈНыАыУГБҪХЯөДУЕКЖЈ¬ФЪSinkҙҰАнЛЩ¶И№»ҝмЈ¬ChannelГ»УР»әҙж№э¶аИХЦҫөДКұәтЈ¬ҫНК№УГMemoryChannelЈ¬өұSinkҙҰАнЛЩ¶ИёъІ»ЙПЈ¬УЦРиТӘChannelДЬ№»»әҙжПВУҰУГ¶Л·ўЛН№эАҙөДИХЦҫКұЈ¬ҫНК№УГFileChannelЈ¬УЙҙЛОТГЗҝӘ·ўБЛDualChannelЈ¬ДЬ№»ЦЗДЬөДФЪБҪёцChannelЦ®јдЗР»»ЎЈ
ЖдҫЯМеөДВЯјӯИзПВЈә
1 /*** 2 * putToMemChannel indicate put event to memChannel or fileChannel 3 * takeFromMemChannel indicate take event from memChannel or fileChannel 4 * */ 5 private AtomicBoolean putToMemChannel = new AtomicBoolean(true); 6 private AtomicBoolean takeFromMemChannel = new AtomicBoolean(true); 7 8 void doPut(Event event) { 9 if (switchon && putToMemChannel.get()) {10 //НщmemChannelЦРРҙКэҫЭ11 memTransaction.put(event);12 13 if ( memChannel.isFull() || fileChannel.getQueueSize() > 100) {14 putToMemChannel.set(false);15 }16 } else {17 //НщfileChannelЦРРҙКэҫЭ18 fileTransaction.put(event);19 }20 }21 22 Event doTake() {23 Event event = null;24 if ( takeFromMemChannel.get() ) {25 //ҙУmemChannelЦРИЎКэҫЭ26 event = memTransaction.take();27 if (event == null) {28 takeFromMemChannel.set(false);29 } 30 } else {31 //ҙУfileChannelЦРИЎКэҫЭ32 event = fileTransaction.take();33 if (event == null) {34 takeFromMemChannel.set(true);35 36 putToMemChannel.set(true);37 } 38 }39 return event;40 }
2.5 ФцјУNullChannel
FlumeМṩБЛNullSinkЈ¬ҝЙТФ°СІ»РиТӘөДИХЦҫНЁ№эNullSinkЦұҪУ¶ӘЖъЈ¬І»ҪшРРҙжҙўЎЈИ»¶шЈ¬SourceРиТӘПИҪ«eventsҙж·ЕөҪChannelЦРЈ¬NullSinkФЩҪ«eventsИЎіцИУөфЎЈОӘБЛМбЙэРФДЬЈ¬ОТГЗ°СХвТ»ІҪТЖөҪБЛChannelАпГжЧцЈ¬ЛщТФҝӘ·ўБЛNullChannelЎЈ
2.6 ФцјУKafkaSink
ОӘЦ§іЦПтStormМṩКөКұКэҫЭБчЈ¬ОТГЗФцјУБЛKafkaSinkУГАҙПтKafkaРҙКөКұКэҫЭБчЎЈЖд»щұҫөДВЯјӯИзПВЈә
1 public class KafkaSink extends AbstractSink implements Configurable { 2 private String zkConnect; 3 private Integer zkTimeout; 4 private Integer batchSize; 5 private Integer queueSize; 6 private String serializerClass; 7 private String producerType; 8 private String topicPrefix; 9 10 private Producer<String, String> producer;11 12 public void configure(Context context) {13 //¶БИЎЕдЦГЈ¬ІўјмІйЕдЦГ14 }15 16 @Override17 public synchronized void start() {18 //іхКј»Ҝproducer19 }20 21 @Override22 public synchronized void stop() {23 //№ШұХproducer24 }25 26 @Override27 public Status process() throws EventDeliveryException {28 29 Status status = Status.READY;30 31 Channel channel = getChannel();32 Transaction tx = channel.getTransaction();33 try {34 tx.begin();35 36 //Ҫ«ИХЦҫ°ҙcategory·Ц¶УБРҙж·Е37 Map<String, List<String>> topic2EventList = new HashMap<String, List<String>>();38 39 //ҙУchannelЦРИЎbatchSizeҙуРЎөДИХЦҫЈ¬ҙУheaderЦР»сИЎcategoryЈ¬ЙъіЙtopicЈ¬Іўҙж·ЕУЪЙПКцөДMapЦРЈ»40 41 //Ҫ«MapЦРөДКэҫЭНЁ№эproducer·ўЛНёшkafka 42 43 tx.commit();44 } catch (Exception e) {45 tx.rollback();46 throw new EventDeliveryException(e);47 } finally {48 tx.close();49 }50 return status;51 }52 }
2.7 РЮёҙәНscribeөДјжИЭОКМв
ScribedФЪНЁ№эScribeSource·ўЛНКэҫЭ°ьёшFlumeКұЈ¬ҙуУЪ4096ЧЦҪЪөД°ьЈ¬»бПИ·ўЛНТ»ёцDummy°ьјмІй·юОсЖчөД·ҙУҰЈ¬¶шFlumeөДScribeSource¶ФУЪlogentry.size()=0өД°ь·ө»ШTRY_LATERЈ¬ҙЛКұScribedҫНИПОӘіцҙнЈ¬¶ПҝӘБ¬ҪУЎЈХвСщСӯ»··ҙёҙіўКФЈ¬ОЮ·ЁХжХэ·ўЛНКэҫЭЎЈПЦФЪФЪScribeSourceөДThriftҪУҝЪЦРЈ¬¶ФsizeОӘ0өДЗйҝц·ө»ШOKЈ¬ұЈЦӨәуРшХэіЈ·ўЛНКэҫЭЎЈ
3. FlumeПөНіөчУЕҫӯСйЧЬҪб
3.1 »щҙЎІОКэөчУЕҫӯСй
- HdfsSinkЦРД¬ИПөДserializer»бГҝРҙТ»РРФЪРРОІМнјУТ»ёц»»РР·ыЈ¬ОТГЗИХЦҫұҫЙнҙшУР»»РР·ыЈ¬ХвСщ»бөјЦВГҝМхИХЦҫәуГж¶аТ»ёцҝХРРЈ¬РЮёДЕдЦГІ»ТӘЧФ¶ҜМнјУ»»РР·ыЈ»
lc.sinks.sink_hdfs.serializer.appendNewline = falseөчҙуMemoryChannelөДcapacityЈ¬ҫЎБҝАыУГMemoryChannelҝмЛЩөДҙҰАнДЬБҰЈ»
өчҙуHdfsSinkөДbatchSizeЈ¬ФцјУНМНВБҝЈ¬јхЙЩhdfsөДflushҙОКэЈ»
ККөұөчҙуHdfsSinkөДcallTimeoutЈ¬ұЬГвІ»ұШТӘөДі¬КұҙнОуЈ»
3.2 HdfsSink»сИЎFilenameөДУЕ»Ҝ
HdfsSinkөДpathІОКэЦёГчБЛИХЦҫұ»РҙөҪHdfsөДО»ЦГЈ¬ёГІОКэЦРҝЙТФТэУГёсКҪ»ҜөДІОКэЈ¬Ҫ«ИХЦҫРҙөҪТ»ёц¶ҜМ¬өДДҝВјЦРЎЈХв·ҪұгБЛИХЦҫөД№ЬАнЎЈАэИзОТГЗҝЙТФҪ«ИХЦҫРҙөҪcategory·ЦАаөДДҝВјЈ¬ІўЗТ°ҙМмәН°ҙРЎКұҙж·ЕЈә
lc.sinks.sink_hdfs.hdfs.path = /user/hive/work/orglog.db/%{category}/dt=%Y%m%d/hour=%HHdfsS inkЦРҙҰАнГҝМхeventКұЈ¬¶јТӘёщҫЭЕдЦГ»сИЎҙЛeventУҰёГРҙИлөДHdfs pathәНfilenameЈ¬Д¬ИПөД»сИЎ·Ҫ·ЁКЗНЁ№эХэФтұнҙпКҪМж»»ЕдЦГЦРөДұдБҝЈ¬»сИЎХжКөөДpathәНfilenameЎЈТтОӘҙЛ№эіМКЗГҝМхevent¶јТӘЧцөДІЩЧчЈ¬әДКұәЬіӨЎЈНЁ№эОТГЗөДІвКФЈ¬20НтМхИХЦҫЈ¬ХвёцІЩЧчТӘәДКұ6-8sЧуУТЎЈ
УЙУЪОТГЗДҝЗ°өДpathәНfilenameУР№М¶ЁөДДЈКҪЈ¬ҝЙТФНЁ№эЧЦ·ыҙ®ЖҙҪУ»сөГЎЈ¶шәуХЯұИХэФтЖҘЕдҝмјёК®ұ¶ЎЈЖҙҪУ¶Ё·ыҙ®өД·ҪКҪЈ¬20НтМхИХЦҫөДІЩЧчЦ»РиТӘјё°ЩәБГлЎЈ
3.3 HdfsSinkөДb/m/sУЕ»Ҝ
ФЪОТГЗіхКјөДЙијЖЦРЈ¬ЛщУРөДИХЦҫ¶јНЁ№эТ»ёцChannelәНТ»ёцHdfsSinkРҙөҪHdfsЙПЎЈОТГЗАҙҝҙТ»ҝҙХвСщЧцУРКІГҙОКМвЎЈ
КЧПИЈ¬ОТГЗАҙҝҙТ»ПВHdfsSinkФЪ·ўЛНКэҫЭөДВЯјӯЈә
1 //ҙУChannelЦРИЎbatchSizeҙуРЎөДevents 2 for (txnEventCount = 0; txnEventCount < batchSize; txnEventCount++) { 3 //¶ФГҝМхИХЦҫёщҫЭcategory appendөҪПаУҰөДbucketWriterЙПЈ» 4 bucketWriter.append(event); 5 Јэ 6 7 for (BucketWriter bucketWriter : writers) { 8 //И»әу¶ФГҝТ»ёцbucketWriterөчУГПаУҰөДflush·Ҫ·ЁҪ«КэҫЭflushөҪHdfsЙП 9 bucketWriter.flush();10 Јэ
јЩЙиОТГЗөДПөНіЦРУР100ёцcategoryЈ¬batchSizeҙуРЎЙиЦГОӘ20НтЎЈФтГҝ20НтМхКэҫЭЈ¬ҫНРиТӘ¶Ф100ёцОДјюҪшРРappend»тХЯflushІЩЧчЎЈ
ЖдҙОЈ¬¶ФУЪОТГЗөДИХЦҫАҙЛөЈ¬»щұҫ·ыәП80/20ФӯФтЎЈјҙ20%өДcategoryІъЙъБЛПөНі80%өДИХЦҫБҝЎЈХвСщ¶ФҙуІҝ·ЦИХЦҫАҙЛөЈ¬Гҝ20НтМхҝЙДЬЦ»°ьә¬јёМхИХЦҫЈ¬ТІРиТӘНщHdfsЙПflushТ»ҙОЎЈ
ЙПКцөДЗйҝц»бөјЦВHdfsSinkРҙHdfsөДР§ВКј«ІоЎЈПВНјКЗөҘChannelөДЗйҝцПВГҝРЎКұөД·ўЛНБҝәНРҙhdfsөДКұјдЗчКЖНјЎЈ
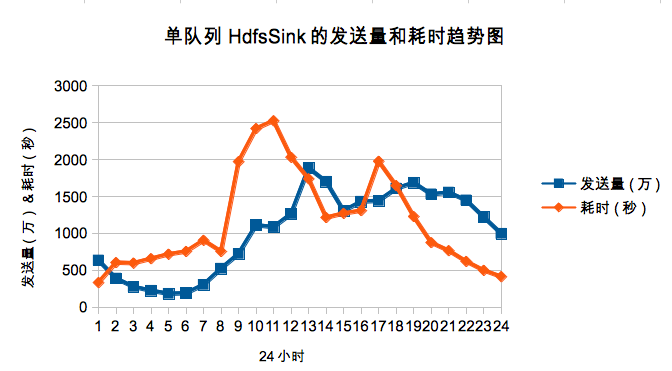
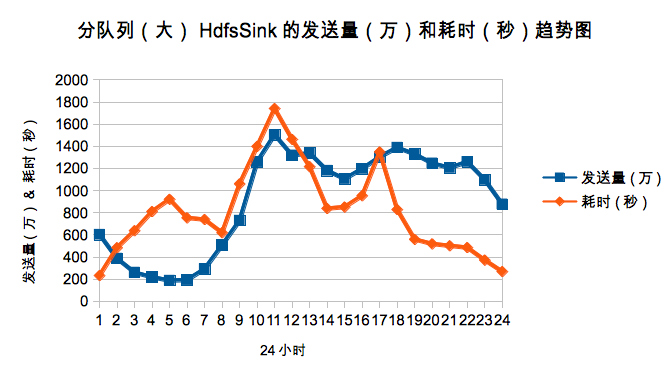
јшУЪХвЦЦКөјКУҰУГіЎҫ°Ј¬ОТГЗ°СИХЦҫҪшРРБЛҙуРЎ№йАаЈ¬·ЦОӘbig, middleәНsmallИэАаЈ¬ХвСщҝЙТФУРР§өДұЬГвРЎИХЦҫёъЧЕҙуИХЦҫТ»ЖрЖө·ұөДflushЈ¬МбЙэР§№ыГчПФЎЈПВНјКЗ·Ц¶УБРәуbig¶УБРөДГҝРЎКұөД·ўЛНБҝәНРҙhdfsөДКұјдЗчКЖНјЎЈ
4 ОҙАҙ·ўХ№
ДҝЗ°Ј¬FlumeИХЦҫКХјҜПөНіМṩБЛТ»ёцёЯҝЙУГЈ¬ёЯҝЙҝҝЈ¬ҝЙА©Х№өД·ЦІјКҪ·юОсЈ¬ТСҫӯУРР§өШЦ§іЦБЛГАНЕөДИХЦҫКэҫЭКХјҜ№ӨЧчЎЈ
әуРшЈ¬ОТГЗҪ«ФЪИзПВ·ҪГжјМРшСРҫҝЈә
ИХЦҫ№ЬАнПөНіЈәНјРО»ҜөДХ№КҫәНҝШЦЖИХЦҫКХјҜПөНіЈ»
ёъҪшЙзЗш·ўХ№ЈәёъҪшFlume 1.5өДҪшХ№Ј¬Н¬Кұ»ШАЎЙзЗшЈ»