首先说下这个是单表查询,1000万数据量,检索的是20万数据量,只有一个where条件,并且这个where条件是建了索引的。
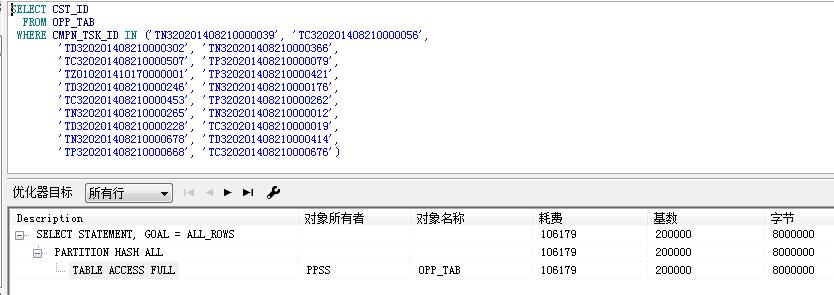
直接查看执行计划是走的全表扫描、20万/1000万=2%。这么少的数据量为啥也走全表扫描,是没有建对索引,还是其他情况?
1、
2、
3、

4、
5、

6、
------解决思路----------------------
是个好问题,推荐一下,大家一起看看
从1和2的比较中,table access full以cost更低的优势胜出
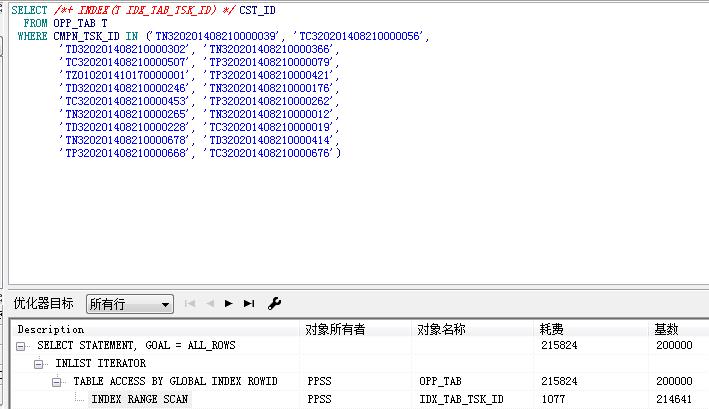
之所以使用索引会有这么大的cost,是因为根据in后面的参数,出现多次的跳转
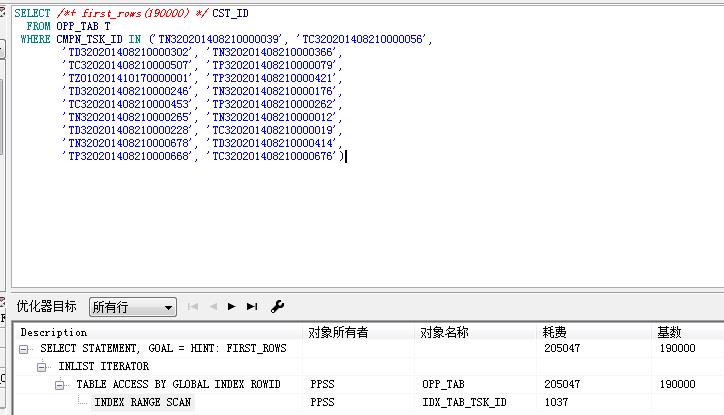
到3的时候,指定first rows(100), 执行计划中的基数变成了101. 此时,in里面的参数可能只要找到其中一个就能满足条件,走索引的成本就变得很低
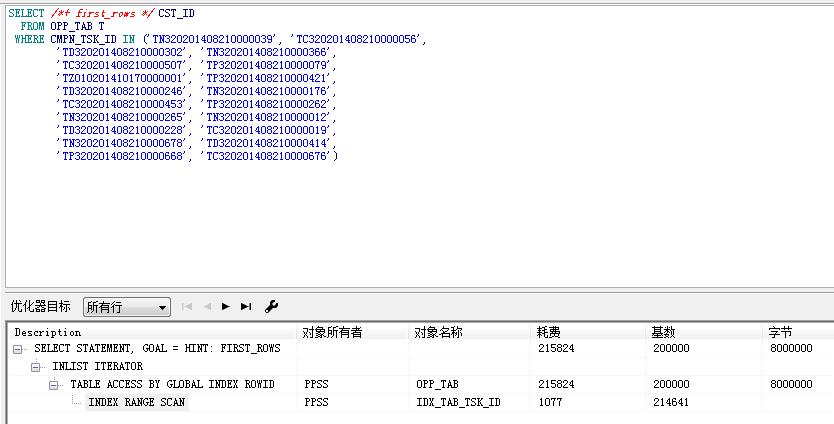
到190000的时候,接近全表扫描和走索引的临界点。到了200000,和all_rows已经没有区别