select count(1) as Counts from kjbg_ysdata t where ( contains(TITLE , 'the')>0 ) AND ( contains(SEARCHORG,'NASA (Unspecified Center)')>0 )
title,searchorg 都是建的全文索引 .
下面是时间和计划 。
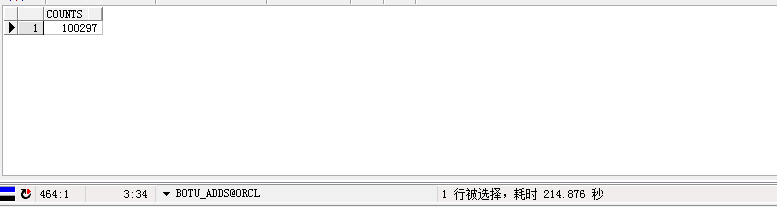 .
.
------解决思路----------------------
select count(1) as Counts from kjbg_ysdata t where ( contains(SEARCHORG,'NASA (Unspecified Center)')>0;
能跑多少秒?
顺便试一下:
exec ctx_ddl.sync_index('全文索引名');--同步索引,将新的数据同步到索引
exec ctx_ddl.optimize_index('全文索引名','FULL');--优化索引,清楚已删除的数据
------解决思路----------------------
表结构 和 索引 列下
感兴趣
------解决思路----------------------
两百多秒快到两秒只是快了一点点么?这已经快了两个数量级了啊。。
楼主不用count(1) count 一下你建的索引列试试。
------解决思路----------------------
你试一下把你title列的全文索引重建一下.刚测试了一下,两个索引应该都会用上的,索引通过位图转换取交集的.