1,垂直拆分
相对于水平拆分来说,垂直拆分比较容易实现一些,垂直拆分的意思是把数据库中不同的业务数据拆分到不同的数据库中。垂直拆分能很好的起到分散数据库压力的作用。业务模块不明晰,耦合(表关联)度比较高的系统不适合使用这种拆分方式。
有得用户查询积分快,有的用户查询自己的订单很快,但是查询自己的用户信息很慢,为什么?
2,垂直切分的优点
◆ 数据库的拆分简单明了,拆分规则明确;
◆ 应用程序模块清晰明确,整合容易;
◆ 数据维护方便易行,容易定位;
<版权所有,文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!>
原博客地址: http://blog.csdn.net/mchdba/article/details/46278687
原作者:黄杉 (mchdba)
3,垂直切分的缺点
◆ 部分表关联无法在数据库级别完成,需要在程序中完成;
◆ 对于访问极其频繁且数据量超大的表仍然存在性能平静,不一定能满足要求;
◆ 事务处理相对更为复杂;
◆ 切分达到一定程度之后,扩展性会遇到限制;
◆ 过读切分可能会带来系统过渡复杂而难以维护。
针对于垂直切分可能遇到数据切分及事务问题,在数据库层面实在是很难找到一个较好的处理方案。实际应用案例中,数据库的垂直切分大多是与应用系统的模块相对应,同一个模块的数据源存放于同一个数据库中,可以解决模块内部的数据关联问题。而模块与模块之间,则通过应用程序以服务接口方式来相互提供所需要的数据。虽然这样做在数据库的总体操作次数方面确实会有所增加,但是在系统整体扩展性以及架构模块化方面,都是有益的。
可能在某些操作的单次响应时间会稍有增加,但是系统的整体性能很可能反而会有一定的提升。而扩展瓶颈问题。
4,拆分规则
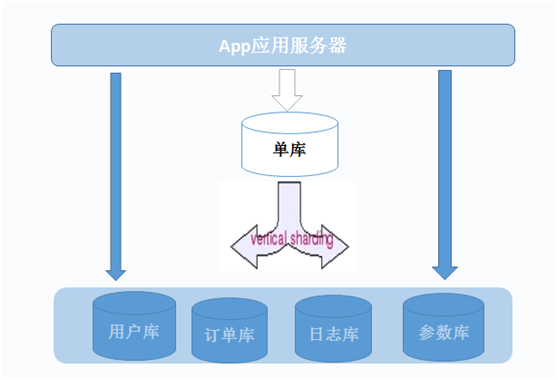
根据模块拆分,比如用户模块、订单模块、日志模块,系统参数模块
用户模块的表:uc_user表;uc_user_info表;uc_action表;uc_profile表
订单模块表:order_action表;order_list表;shop表;order表;
日志模块:order_log表;uc_log表;plocc_log表;
系统参数模块:plocc_parameter表;
模块模块之间都一看都是有联系的,这些都是用到用户的,那么都和用户模块有关联
如下图所示:
5,垂直拆分演示
5.1准备mysql环境
创建多实例参考:http://blog.csdn.net/mchdba/article/details/45798139
建库sql语句:
--1 用户模块 3307端口数据库 create database user_db; CREATE TABLE user_db.`uc_user` ( `user_id` bigint(20) NOT NULL, `uc_name` varchar(200) DEFAULT NULL, `created_time` datetime DEFAULT NULL, PRIMARY KEY (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; grant insert,update,delete,select on user_db.* to tim@'192.168.%' identified by 'timgood2013';-- 查询 mysql --socket=/usr/local/mysql3307/mysql.sock -e "select * from user_db.uc_user;";--2 订单模块 3308端口数据库 create database order_db; CREATE TABLE order_db.`order` ( `order_id` bigint(20) NOT NULL, `shop_id` varchar(200) DEFAULT NULL, `created_time` datetime DEFAULT NULL, `user_id` bigint(20) not null, PRIMARY KEY (`order_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; grant insert,update,delete,select on order_db.* to tim@'192.168.%' identified by 'timgood2013';-- 查询 mysql --socket=/usr/local/mysql3308/mysql.sock -e "select * from order_db.order;";--3 日志模块 3309端口数据库 create database log_db; CREATE TABLE log_db.`order_log` ( `orlog_id` bigint(20) NOT NULL, `order_id` varchar(200) DEFAULT NULL, `created_time` datetime DEFAULT NULL, `user_id` bigint(20) not null, `action` varchar(2000) not null, PRIMARY KEY (`orlog_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; grant insert,update,delete,select on log_db.* to tim@'192.168.%' identified by 'timgood2013';-- 查询 mysql --socket=/usr/local/mysql3309/mysql.sock -e "select * from log_db.order_log;";--4 参数模块 33310端口数据库 create database plocc_db; CREATE TABLE plocc_db.`plocc_parameter` ( `plocc_id` bigint(20) NOT NULL, `pname` varchar(200) DEFAULT NULL, `created_time` datetime DEFAULT NULL, `status` bigint(20) not null, `creator` bigint not null, PRIMARY KEY (`plocc_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; grant insert,update,delete,select on plocc_db.* to tim@'192.168.%' identified by 'timgood2013';--5.2 演示java代码
package mysql;import java.math.BigInteger;import java.sql.Connection;import java.sql.DriverManager;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.sql.SQLException;import java.sql.Statement;import java.text.SimpleDateFormat;import java.util.Calendar;import java.util.Date;public class MySQLTest2 { public static long user_id; public static void main(String[] args) { MySQLTest2 mt=new MySQLTest2(); /* 录入用户数据 BigInteger user_id0 = new BigInteger("10001"); Connection conn=mt.getConn("user_db"); mt.insertUser(conn, bi, "tim--"+user_id0.longValue()); */ /* 录入日志数据 Connection conn2=mt.getConn("log_db"); BigInteger user_id = new BigInteger("10001"); BigInteger order_id = new BigInteger("20150531001"); BigInteger orlog_id = new BigInteger("20150531001"); mt.insertLog(conn2, user_id,order_id , orlog_id, "create a order for tim"); */ //录入订单数据 Connection conn3=mt.getConn("order_db"); BigInteger user_id2 = new BigInteger("10001"); BigInteger order_id2 = new BigInteger("20150531001"); BigInteger shop_id2 = new BigInteger("20150531001"); mt.insertOrder(conn3,order_id2 , shop_id2, user_id2); } // 获取数据库的连接,如果扩展的话,可以单独做一个接口提供给程序员来调用它 // String type:连接的数据类型 public Connection getConn(String type ) { String port="3307"; if (type=="user_db" ){ port="3307"; }else if(type=="order_db"){ port="3308"; }else if(type=="log_db"){ port="3309"; }else if(type=="plocc_db") { port="3310"; }else{ port="3311"; } Connection conn = null; try { Class.forName("com.mysql.jdbc.Driver"); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } String url = "jdbc:mysql://192.168.52.130:"+port+"/"+type; try { conn = DriverManager.getConnection(url, "tim", "timgood2013"); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } System.out.println("the current db is :"+url); return conn; } // 获取日期字符串 public String getTimeByCalendar(){ /* Calendar cal = Calendar.getInstance(); int year = cal.get(Calendar.YEAR);//获取年份 int month=cal.get(Calendar.MONTH);//获取月份 int day=cal.get(Calendar.DATE);//获取日 int hour=cal.get(Calendar.HOUR);//小时 int minute=cal.get(Calendar.MINUTE);//分 int second=cal.get(Calendar.SECOND);//秒 String strdate=year+"-"+month+"-"+day+" "+hour+":"+minute+":"+second; */ SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");//设置日期格式 System.out.println(df.format(new Date()));// new Date()为获取当前系统时间 return df.format(new Date()); } // 开始录入用户数据 public int insertUser(Connection cnn,BigInteger user_id,String name){ String sql="insert into user_db.uc_user(user_id,uc_name,created_time)values(?,?,?)"; int i=0; long uid = user_id.longValue(); Connection conn=cnn; try{ PreparedStatement preStmt =conn.prepareStatement(sql); preStmt.setLong(1, uid); preStmt.setString(2,name); preStmt.setString(3,getTimeByCalendar()); i=preStmt.executeUpdate(); } catch (SQLException e) { e.printStackTrace(); } return i;//返回影响的行数,1为执行成功 } // 开始录入日志数据 public int insertLog(Connection cnn,BigInteger user_id,BigInteger order_id,BigInteger orlog_id,String action){ String sql="insert into log_db.order_log(orlog_id,order_id,created_time,user_id,action)values(?,?,?,?,?)"; int i=0; Connection conn=cnn; try{ PreparedStatement preStmt =conn.prepareStatement(sql); preStmt.setLong(1, user_id.longValue()); preStmt.setLong(2, order_id.longValue()); preStmt.setString(3,getTimeByCalendar()); preStmt.setLong(4, orlog_id.longValue()); preStmt.setString(5,action); i=preStmt.executeUpdate(); } catch (SQLException e) { e.printStackTrace(); } return i;//返回影响的行数,1为执行成功 } // 开始录入订单数据 public int insertOrder(Connection cnn,BigInteger order_id,BigInteger shop_id,BigInteger user_id){ String sql="insert into order_db.order(order_id,shop_id,created_time,user_id)values(?,?,?,?)"; int i=0; Connection conn=cnn; try{ PreparedStatement preStmt =conn.prepareStatement(sql); preStmt.setLong(1, order_id.longValue()); preStmt.setLong(2, shop_id.longValue()); preStmt.setString(3,getTimeByCalendar()); preStmt.setLong(4, user_id.longValue()); i=preStmt.executeUpdate(); } catch (SQLException e) { e.printStackTrace(); } return i;//返回影响的行数,1为执行成功 } //开始录入参数数据 public int insertPlocc(){ int i=0; return i; }}6,水平拆分和垂直拆分的结合
我们分别,了解了“垂直”和“水平”这两种切分方式的实现以及切分之后的架构信息,同时也分析了两种架构各自的优缺点。但是在实际的应用场景中,除了那些负载并不是太大,业务逻辑也相对较简单的系统可以通过上面两种切分方法之一来解决扩展性问题之外,恐怕其他大部分业务逻辑稍微复杂一点,系统负载大一些的系统,都无法通过上面任何一种数据的切分方法来实现较好的扩展性,而需要将上述两种切分方法结合使用,不同的场景使用不同的切分方法。
将结合垂直切分和水平切分各自的优缺点,进一步完善我们的整体架构,让系统的扩展性进一步提高。
一般来说,我们数据库中的所有表很难通过某一个(或少数几个)字段全部关联起来,所以很难简单的仅仅通过数据的水平切分来解决所有问题。而垂直切分也只能解决部分问题,对于那些负载非常高的系统,即使仅仅只是单个表都无法通过单台数据库主机来承担其负载。我们必须结合“垂直”和“水平”两种切分方式同时使用,充分利用两者的优点,避开其缺点。
每一个应用系统的负载都是一步一步增长上来的,在开始遇到性能瓶颈的时候,大多数架构师和DBA 都会选择先进行数据的垂直拆分,因为这样的成本最先,最符合这个时期所追求的最大投入产出比。然而,随着业务的不断扩张,系统负载的持续增长,在系统稳定一段时期之后,经过了垂直拆分之后的数据库集群可能又再一次不堪重负,遇到了性能瓶颈。
这时候我们该如何抉择?是再次进一步细分模块呢,还是寻求其他的办法来解决?如果我们再一次像最开始那样继续细分模块,进行数据的垂直切分,那我们可能在不久的将来,又会遇到现在所面对的同样的问题。而且随着模块的不断的细化,应用系统的架构也会越来越复杂,整个系统很可能会出现失控的局面。
这时候我们就必须要通过数据的水平切分的优势,来解决这里所遇到的问题。而且,我们完全不必要在使用数据水平切分的时候,推倒之前进行数据垂直切分的成果,而是在其基础上利用水平切分的优势来避开垂直切分的弊端,解决系统复杂性不断扩大的问题。而水平拆分的弊端(规则难以统一)也已经被之前的垂直切分解决掉了,让水平拆分可以进行的得心应手。
对于我们的示例数据库,假设在最开始,我们进行了数据的垂直切分,然而随着业务的不断增长,数据库系统遇到了瓶颈,我们选择重构数据库集群的架构。如何重构?考虑到之前已经做好了数据的垂直切分,而且模块结构清晰明确。而业务增长的势头越来越猛,即使现在进一步再次拆分模块,也坚持不了太久。我们选择了在垂直切分的基础上再进行水平拆分。
在经历过垂直拆分后的各个数据库集群中的每一个都只有一个功能模块,而每个功能模块中的所有表基本上都会与某个字段进行关联。如用户模块全部都可以通过用户ID 进行切分,群组讨论模块则都通过群组ID 来切分,相册模块则根据相册ID 来进切分,最后的事件通知信息表考虑到数据的时限性(仅仅只会访问最近某个事件段的信息),则考虑按时间来切分。
如下图所示:
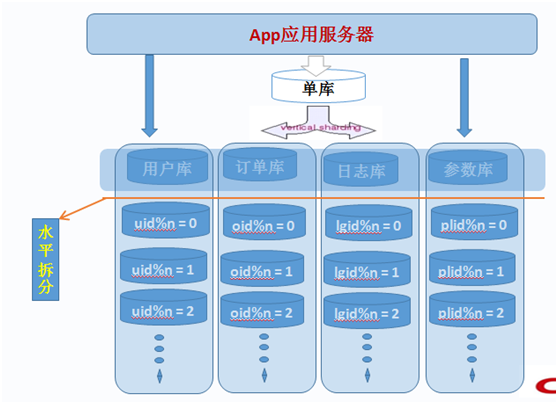
实际上,在很多大型的应用系统中,垂直切分和水平切这两种数据的切分方法基本上都是并存的,而且经常在不断的交替进行,以不断的增加系统的扩展能力。我们在应对不同的应用场景的时候,也需要充分考虑到这两种切分方法各自的局限,以及各自的优势,在不同的时期(负载压力)使用不同的结合方式。
联合切分的优点
◆ 可以充分利用垂直切分和水平切分各自的优势而避免各自的缺陷;
◆ 让系统扩展性得到最大化提升;
联合切分的缺点
◆ 数据库系统架构比较复杂,维护难度更大;
◆ 应用程序架构也相对更复杂;
7,数据切分整合方案
通过数据库的数据切分可以极大的提高系统的扩展性。但是,数据库中的数据在经过垂直和(或)水平切分被存放在不同的数据库主机之后,应用系统面临的最大问题就是如何来让这些数据源得到较好的整合,可能这也是很多读者朋友非常关心的一个问题。这一节我们主要针对的内容就是分析可以使用的各种可以帮助我们实现数据切分以及数据整合的整体解决方案。
数据的整合很难依靠数据库本身来达到这个效果,虽然MySQL 存在Federated 存储引擎,可以解决部分类似的问题,但是在实际应用场景中却很难较好的运用。那我们该如何来整合这些分散在各个MySQL 主机上面的数据源呢?
总的来说,存在两种解决思路:
1. 在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个数据库,在模块内完成数据的整合;
2. 通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明;可能90%以上的人在面对上面这两种解决思路的时候都会倾向于选择第二种,尤其是系统不断变得庞大复杂的时候。确实,这是一个非常正确的选择,虽然短期内需要付出的成本可能会相对更大一些,但是对整个系统的扩展性来说,是非常有帮助的。
可能90%以上的人在面对上面这两种解决思路的时候都会倾向于选择第二种,尤其是系统不断变得庞大复杂的时候。确实,这是一个非常正确的选择,虽然短期内需要付出的成本可能会相对更大一些,但是对整个系统的扩展性来说,是非常有帮助的。所以,对于第一种解决思路我这里就不准备过多的分析,下面我重点分析一下在第二种解决思路中的一些解决方案。
7.1 自行开发中间代理层
在决定选择通过数据库的中间代理层来解决数据源整合的架构方向之后,有不少公司(或者企业)选择了通过自行开发符合自身应用特定场景的代理层应用程序。通过自行开发中间代理层可以最大程度的应对自身应用的特定,最大化的定制很多个性化需求,在面对变化的时候也可以灵活的应对。这应该说是自行开发代理层最大的优势了。
当然,选择自行开发,享受让个性化定制最大化的乐趣的同时,自然也需要投入更多的成本来进行前期研发以及后期的持续升级改进工作,而且本身的技术门槛可能也比简单的Web 应用要更高一些。所以,在决定选择自行开发之前,还是需要进行比较全面的评估为好。由于自行开发更多时候考虑的是如何更好的适应自身应用系统,应对自身的业务场景,所以这里也不好分析太多。后面我们主要分析一下当前比较流行的几种数据源整合解决方案。
7.2利用MySQL Proxy 实现数据切分及整合
MySQL Proxy 是MySQL 官方提供的一个数据库代理层产品,和MySQL Server 一样,同样是一个基于GPL 开源协议的开源产品。可用来监视、分析或者传输他们之间的通讯信息。他的灵活性允许你最大限度的使用它,目前具备的功能主要有连接路由,Query 分析,Query 过滤和修改,负载均衡,以及基本的HA 机制等。
实际上,MySQL Proxy 本身并不具有上述所有的这些功能,而是提供了实现上述功能的基础。要实现这些功能,还需要通过我们自行编写LUA 脚本来实现。MySQL Proxy 实际上是在客户端请求与MySQL Server 之间建立了一个连接池。所有客户端请求都是发向MySQL Proxy,然后经由MySQL Proxy 进行相应的分析,判断出是读操作还是写操作,分发至对应的MySQL Server 上。对于多节点Slave 集群,也可以起做到负载均衡的效果。
7.3利用Amoeba 实现数据切分及整合
Amoeba 是一个基于Java 开发的,专注于解决分布式数据库数据源整合Proxy 程序的开源框架,基于GPL3 开源协议。目前,Amoeba 已经具有Query 路由,Query 过滤,读写分离,负载均衡以及HA 机制等相关内容。Amoeba 主要解决的以下几个问题:
1. 数据切分后复杂数据源整合;
2. 提供数据切分规则并降低数据切分规则给数据库带来的影响;
3. 降低数据库与客户端的连接数;
4. 读写分离路由;
我们可以看出,Amoeba 所做的事情,正好就是我们通过数据切分来提升数据库的扩展性所需要的。
7.4 利用HiveDB 实现数据切分及整合
和前面的MySQL Proxy 以及Amoeba 一样,HiveDB 同样是一个基于Java 针对MySQL数据库的提供数据切分及整合的开源框架,只是目前的HiveDB 仅仅支持数据的水平切分。主要解决大数据量下数据库的扩展性及数据的高性能访问问题,同时支持数据的冗余及基本的HA 机制。
HiveDB 的实现机制与MySQL Proxy 和Amoeba 有一定的差异,他并不是借助MySQL的Replication 功能来实现数据的冗余,而是自行实现了数据冗余机制,而其底层主要是基于Hibernate Shards 来实现的数据切分工作。
在HiveDB 中,通过用户自定义的各种Partition k e y s(其实就是制定数据切分规则),将数据分散到多个MySQL Server 中。在访问的时候,在运行Query 请求的时候,会自动分析过滤条件,并行从多个MySQL Server 中读取数据,并合并结果集返回给客户端应用程序。
单纯从功能方面来讲,HiveDB 可能并不如MySQL Proxy 和Amoeba 那样强大,但是其数据切分的思路与前面二者并无本质差异。此外,HiveDB 并不仅仅只是一个开源爱好者所共享的内容,而是存在商业公司支持的开源项目。
7.5 其他实现数据切分及整合的解决方案
除了上面介绍的几个数据切分及整合的整体解决方案之外,还存在很多其他同样提供了数据切分与整合的解决方案。如基于MySQL Proxy 的基础上做了进一步扩展的HSCALE,通过Rails 构建的Spock Proxy,以及基于Pathon 的Pyshards 等等。不管大家选择使用哪一种解决方案,总体设计思路基本上都不应该会有任何变化,那就是通过数据的垂直和水平切分,增强数据库的整体服务能力,让应用系统的整体扩展能力尽可能的提升,扩展方式尽可能的便捷。
只要我们通过中间层Proxy 应用程序较好的解决了数据切分和数据源整合问题,那么数据库的线性扩展能力将很容易做到像我们的应用程序一样方便,只需要通过添加廉价的PC Server 服务器,即可线性增加数据库集群的整体服务能力,让数据库不再轻易成为应用系统的性能瓶颈。
- 1楼zhanghongjie03029小时前
- 很不错的方案!