БЦұюОДEvankakaФӯҙҙЧчЖ·ЎЈЧӘФШЗлЧўГчіцҙҰhttp://blog.csdn.net/evankaka
ІйСҜКэҫЭЦёҙУКэҫЭҝвЦР»сИЎЛщРиТӘөДКэҫЭЎЈІйСҜКэҫЭКЗКэҫЭҝвІЩЧчЦРЧоіЈУГЈ¬ТІКЗЧоЦШТӘөДІЩЧчЎЈУГ»§ҝЙТФёщҫЭЧФјә¶ФКэҫЭөДРиЗуЈ¬К№УГІ»Н¬өДІйСҜ·ҪКҪЎЈНЁ№эІ»Н¬өДІйСҜ·ҪКҪЈ¬ҝЙТФ»сөГІ»Н¬өДКэҫЭЎЈMySQLЦРКЗК№УГSELECTУпҫдАҙІйСҜКэҫЭөДЎЈФЪХвТ»ХВЦРҪ«ҪІҪвөДДЪИЭ°ьАЁЎЈ
1ЎўІйСҜУпҫдөД»щұҫУп·Ё
2ЎўФЪөҘұнЙПІйСҜКэҫЭ
3ЎўК№УГҫЫәПәҜКэІйСҜКэҫЭ
4Ўў¶аұнЙПБӘәПІйСҜ
5ЎўЧУІйСҜ
6ЎўәПІўІйСҜҪб№ы
7ЎўОӘұнәНЧЦ¶ОИЎұрГы
8ЎўК№УГХэФтұнҙпКҪІйСҜ
КІГҙКЗІйСҜЈҝ
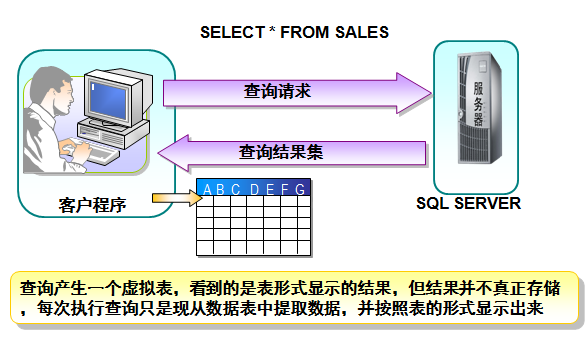
ФхГҙІйөДЈҝ
КэҫЭөДЧјұёИзПВЈә
create table STUDENT(STU_ID int primary KEY,STU_NAME char(10) not null,STU_AGE smallint unsigned not null,STU_SEX char(2) not null);insert into STUDENT values(2001,'РЎНх',13,'ДР');insert into STUDENT values(2002,'ГчГч',12,'ДР');insert into STUDENT values(2003,'әмәм',14,'Е®');insert into STUDENT values(2004,'РЎ»Ё',13,'Е®');insert into STUDENT values(2005,'Мм¶щ',15,'ДР');insert into STUDENT values(2006,'°ўБФ',13,'Е®');insert into STUDENT values(2007,'°ўГЁ',16,'ДР');insert into STUDENT values(2008,'°ў№·',17,'ДР');insert into STUDENT values(2009,'әЪЧУ',14,'ДР');insert into STUDENT values(2010,'РЎУс',13,'Е®');insert into STUDENT values(2011,'Н·Н·',13,'Е®');insert into STUDENT values(2012,'ұщұщ',14,'Е®');insert into STUDENT values(2013,'ГААц',13,'Е®');insert into STUDENT values(2014,'ЙсАЦ',12,'ДР');insert into STUDENT values(2015,'МмОе',13,'ДР');insert into STUDENT values(2016,'РЎИэ',11,'ДР');insert into STUDENT values(2017,'°ўХЕ',13,'ДР');insert into STUDENT values(2018,'°ўҪЬ',13,'ДР');insert into STUDENT values(2019,'°ўұҰ',13,'Е®');insert into STUDENT values(2020,'ҙуНх',14,'ДР');
И»әуХвКЗС§ЙъіЙјЁұнЈ¬ЖдЦР¶ЁТеБЛНвјьФјКш
create table GRADE(STU_ID INT NOT NULL,STU_SCORE INT,foreign key(STU_ID) references STUDENT(STU_ID));insert into GRADE values(2001,90);insert into GRADE values(2002,89);insert into GRADE values(2003,67);insert into GRADE values(2004,78);insert into GRADE values(2005,89);insert into GRADE values(2006,78);insert into GRADE values(2007,99);insert into GRADE values(2008,87);insert into GRADE values(2009,70);insert into GRADE values(2010,71);insert into GRADE values(2011,56);insert into GRADE values(2012,85);insert into GRADE values(2013,65);insert into GRADE values(2014,66);insert into GRADE values(2015,77);insert into GRADE values(2016,79);insert into GRADE values(2017,82);insert into GRADE values(2018,88);insert into GRADE values(2019,NULL);insert into GRADE values(2020,NULL);
Т»ЎўІйСҜУпҫдөД»щұҫУп·Ё
ІйСҜКэҫЭКЗЦёҙУКэҫЭҝвЦРөДКэҫЭұн»тКУНјЦР»сИЎЛщРиТӘөДКэҫЭЈ¬ФЪMySQLЦРЈ¬ҝЙТФК№УГSELECTУпҫдАҙІйСҜКэҫЭЎЈёщҫЭІйСҜМхјюөДІ»Н¬Ј¬КэҫЭҝвПөНі»бХТөҪІ»Н¬өДКэҫЭЎЈ
SELECTУпҫдөД»щұҫУп·ЁёсКҪИзПВЈә
SELECT КфРФБРұн FROM ұнГы»тКУНјБРұн [WHERE МхјюұнҙпКҪ1] [GROUP BY КфРФГы1 [HAVING МхјюұнҙпКҪ2]] [ORDER BY КфРФГы2 [ASC|DESC]]
- КфРФБРұнЈәұнКҫРиТӘІйСҜөДЧЦ¶ОГыЎЈ
- ұнГы»тКУНјБРұнЈәұнКҫјҙҪ«ҪшРРКэҫЭІйСҜөДКэҫЭұн»тХЯКУНјЈ¬ұн»тКУНјҝЙТФУР¶аёцЎЈ
- МхјюұнҙпКҪ1ЈәЙиЦГІйСҜөДМхјюЎЈ
- КфРФГы1ЈәұнКҫ°ҙёГЧЦ¶ОЦРөДКэҫЭҪшРР·ЦЧйЎЈ
- МхјюұнҙпКҪ2ЈәұнКҫВъЧгёГұнҙпКҪөДКэҫЭІЕДЬКдіцЎЈ
- КфРФ2ЈәұнКҫ°ҙёГЧЦ¶ОЦРөДКэҫЭҪшРРЕЕРтЈ¬ЕЕРт·ҪКҪУЙASC»тDESCІОКэЦё¶ЁЎЈ
- ASCЈәұнКҫ°ҙЙэРтөДЛіРтҪшРРЕЕРтЎЈјҙұнКҫЦө°ҙХХҙУРЎөҪҙуөДЛіРтЕЕБРЎЈХвКЗД¬ИПІОКэЎЈ
- DESCЈәұнКҫ°ҙҪөРтөДЛіРтҪшРРЕЕРтЎЈјҙұнКҫЦө°ҙХХҙУҙуөҪРЎөДЛіРтЕЕБРЎЈ
Из№ыУРWHEREЧУҫдЈ¬ҫН°ҙХХЎ°МхјюұнҙпКҪ1ЎұЦё¶ЁөДМхјюҪшРРІйСҜЈ»Из№ыГ»УРWHEREЧУҫдЈ¬ҫНІйСҜЛщУРјЗВјЎЈ
Из№ыУРGROUP BYЧУҫдЈ¬ҫН°ҙХХЎ°КфРФГы1ЎұЦё¶ЁөДЧЦ¶ОҪшРР·ЦЧйЈ»Из№ыGROUP BYЧУҫдәуГжҙшЧЕHAVING№ШјьЧЦЈ¬ДЗГҙЦ»УРВъЧгЎ°МхјюұнҙпКҪ2ЎұЦРЦё¶ЁөДМхјюөДјЗВјІЕДЬ№»КдіцЎЈGROUP BYЧУҫдНЁіЈәНCOUNT()ЎўSUM()өИҫЫәПәҜКэТ»ЖрК№УГЎЈ
Из№ыУРORDER BYЧУҫдЈ¬ҫН°ҙХХЎ°КфРФГы2ЎұЦё¶ЁөДЧЦ¶ОҪшРРЕЕРтЎЈЕЕРт·ҪКҪУЙASC»тDESCІОКэЦё¶ЁЎЈД¬ИПөДЕЕРт·ҪКҪОӘASCЎЈ
¶юЎўФЪөҘұнЙПІйСҜКэҫЭ
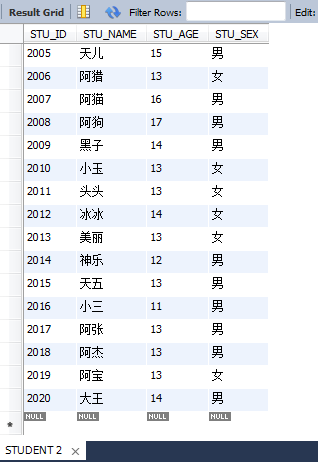
2.1ЎўІйСҜЛщУРЧЦ¶О
select * from STUDENT;
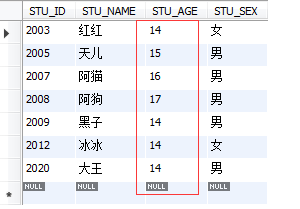
2.2Ўў°ҙМхјюІйСҜ

select * from STUDENT where STU_AGE>13;
IN№ШјьЧЦҝЙТФЕР¶ПДіёцЧЦ¶ОөДЦөКЗ·сФЪЦё¶ЁөДјҜәПЦРЎЈИз№ыЧЦ¶ОөДЦөФЪјҜәПЦРЈ¬ФтВъЧгІйСҜМхјюЈ¬ёГјНВјҪ«ұ»ІйСҜіцАҙЎЈИз№ыІ»ФЪјҜәПЦРЈ¬ФтІ»ВъЧгІйСҜМхјюЎЈЖдУп·Ё№жФтИзПВЈә[ NOT ] IN ( ФӘЛШ1, ФӘЛШ2, Ўӯ, ФӘЛШn )
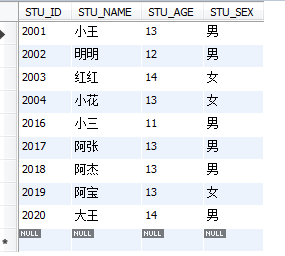
select * from STUDENT where STU_AGE in(11,12);
BETWEEN AND№ШјьЧЦҝЙТФЕР¶БДіёцЧЦ¶ОөДЦөКЗ·сФЪЦё¶ЁөД·¶О§ДЪЎЈИз№ыЧЦ¶ОөДЦөФЪЦё¶Ё·¶О§ДЪЈ¬ФтВъЧгІйСҜМхјюЈ¬ёГјНВјҪ«ұ»ІйСҜіцАҙЎЈИз№ыІ»ФЪЦё¶Ё·¶О§ДЪЈ¬ФтІ»ВъЧгІйСҜМхјюЎЈЖдУп·Ё№жФтИзПВЈә
[ NOT ] BETWEEN ИЎЦө1 AND ИЎЦө2
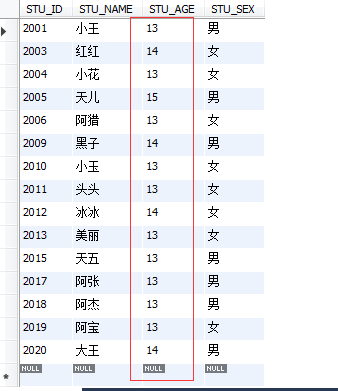
select * from STUDENT where STU_AGE between 13 and 15;
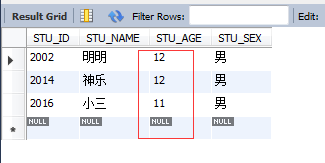
select * from STUDENT where STU_AGE NOT IN(13,14,16);
OR№ШјьЧЦТІҝЙТФУГАҙБӘәП¶аёцМхјюҪшРРІйСҜЈ¬ө«КЗУлAND№ШјьЧЦІ»Н¬ЎЈК№УГOR№ШјьЧЦКұЈ¬Ц»ТӘВъЧгХвјёёцІйСҜМхјюөДЖдЦРТ»ёцЈ¬ХвСщөДјЗВјҪ«»бұ»ІйСҜіцАҙЎЈИз№ыІ»ВъЧгХвР©ІйСҜМхјюЦРөДИОәОТ»ёцЈ¬ХвСщөДјЗВјҪ«ұ»ЕЕіэөфЎЈOR№ШјьЧЦөДУп·Ё№жФтИзПВЈә
МхјюұнҙпКҪ1 OR МхјюұнҙпКҪ2 [ ЎӯOR МхјюұнҙпКҪn ]
ЖдЦРЈ¬ORҝЙТФУГАҙБ¬ҪУБҪёцМхјюұнҙпКҪЎЈ¶шЗТЈ¬ҝЙТФН¬КұК№УГ¶аёцOR№ШјьЧЦЈ¬ХвСщҝЙТФБ¬ҪУёь¶аөДМхјюұнҙпКҪЎЈ
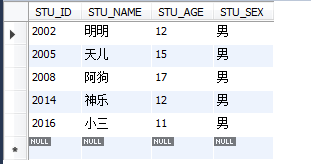
select * from STUDENT where STU_ID<2005 OR STU_ID>2015;
AND№ШјьЧЦҝЙТФУГАҙБӘәП¶аёцМхјюҪшРРІйСҜЎЈК№УГAND№ШјьЧЦКұЈ¬Ц»УРН¬КұВъЧгЛщУРІйСҜМхјюөДјЗВј»бұ»ІйСҜіцАҙЎЈИз№ыІ»ВъЧгХвР©ІйСҜМхјюөДЖдЦРТ»ёцЈ¬ХвСщөДјЗВјҪ«ұ»ЕЕіэөфЎЈAND№ШјьЧЦөДУп·Ё№жФтИзПВЈә
МхјюұнҙпКҪ1 AND МхјюұнҙпКҪ2 [ Ўӯ AND МхјюұнҙпКҪn ]
ЖдЦРЈ¬ANDҝЙТФБ¬ҪУБҪёцМхјюұнҙпКҪЎЈ¶шЗТЈ¬ҝЙТФН¬КұК№УГ¶аёцAND№ШјьЧЦЈ¬ХвСщҝЙТФБ¬ҪУёь¶аөДМхјюұнҙпКҪЎЈ
LIKE№ШјьЧЦҝЙТФЖҘЕдЧЦ·ыҙ®КЗ·сПаөИЎЈИз№ыЧЦ¶ОөДЦөУлЦё¶ЁөДЧЦ·ыҙ®ПаЖҘЕдЈ¬ФтВъЧгІйСҜМхјюЈ¬ёГјНВјҪ«ұ»ІйСҜіцАҙЎЈИз№ыУлЦё¶ЁөДЧЦ·ыҙ®І»ЖҘЕдЈ¬ФтІ»ВъЧгІйСҜМхјюЎЈЖдУп·Ё№жФтИзПВЈә[ NOT ] LIKE 'ЧЦ·ыҙ®'
Ў°NOTЎұҝЙСЎІОКэЈ¬јУЙП NOTұнКҫУлЦё¶ЁөДЧЦ·ыҙ®І»ЖҘЕдКұВъЧгМхјюЈ»Ў°ЧЦ·ыҙ®ЎұұнКҫЦё¶ЁУГАҙЖҘЕдөДЧЦ·ыҙ®Ј¬ёГЧЦ·ыҙ®ұШРлјУөҘТэәЕ»тЛ«ТэәЕЎЈ
select * from STUDENT where STU_NAME LIKE '%Нх';ұнКҫЖҘЕдИОәОТФНхҪбОІөД
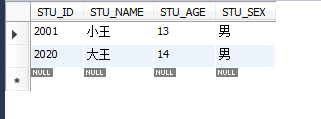
select * from STUDENT where STU_NAME LIKE '°ў%';ұнКҫЖҘЕдИОәОТФ°ўҝӘН·өД

insert into STUDENT values(2021,'МмПВОЮҫө',14,'ДР');
И»әу
select * from STUDENT where STU_NAME LIKE '_ПВ_';ІйСҜөДҪб№ыОӘҝХ

ө«КЗИз№ыПВәуГжјУБҪёц_·ыәЕ
select * from STUDENT where STU_NAME LIKE '_ПВ__';ІйСҜҪб№ыІ»ОӘҝХ
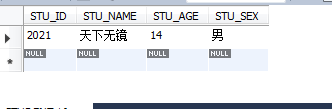
Ў°ЧЦ·ыҙ®ЎұІОКэөДЦөҝЙТФКЗТ»ёцНкХыөДЧЦ·ыҙ®Ј¬ТІҝЙТФКЗ°ьә¬°Щ·ЦәЕ(%)»тХЯПВ»®ПЯ(_)өДНЁЕдЧЦ·ыЎЈ¶юХЯУРәЬҙуЗшұр
Ў°%ЎұҝЙТФҙъұнИОТвіӨ¶ИөДЧЦ·ыҙ®Ј¬іӨ¶ИҝЙТФОӘ0;
Ў°_ЎұЦ»ДЬұнКҫөҘёцЧЦ·ыЎЈ
Из№ыТӘЖҘЕдРХХЕЗТГыЧЦЦ»УРБҪёцЧЦөДИЛөДјЗВјЈ¬Ў°ХЕЎұЧЦәуГжұШРлТӘУРБҪёцЎ°_Ўұ·ыәЕЎЈТтОӘТ»ёцәәЧЦКЗБҪёцЧЦ·ыЈ¬¶шТ»ёцЎ°_Ўұ·ыәЕЦ»ДЬҙъұнТ»ёцЧЦ·ыЎЈ
ЈЁ4Ј©ҝХЦөІйСҜ
IS NULL№ШјьЧЦҝЙТФУГАҙЕР¶ПЧЦ¶ОөДЦөКЗ·сОӘҝХЦөЈЁNULLЈ©ЎЈИз№ыЧЦ¶ОөДЦөКЗҝХЦөЈ¬ФтВъЧгІйСҜМхјюЈ¬ёГјЗВјҪ«ұ»ІйСҜіцАҙЎЈИз№ыЧЦ¶ОөДЦөІ»КЗҝХЦөЈ¬ФтІ»ВъЧгІйСҜМхјюЎЈЖдУп·Ё№жФтИзПВЈә
IS [ NOT ] NULL
ЖдЦРЈ¬Ў°NOTЎұКЗҝЙСЎІОКэЈ¬јУЙПNOTұнКҫЧЦ¶ОІ»КЗҝХЦөКұВъЧгМхјюЎЈ
IS NULLКЗТ»ёцХыМеЈ¬І»ДЬҪ«IS»»іЙЎұ=Ўұ.
ИэЎўК№УГҫЫәПәҜКэІйСҜКэҫЭ
3.1Ўўgroup by ·ЦЧй
ИзПВЈә
select * from STUDENT group by STU_SEX;І»јУМхјюЈ¬ДЗГҙҫНЦ»ИЎГҝёц·ЦЧйөДөЪТ»МхЎЈ
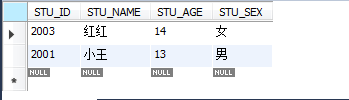
Из№ыПлҝҙ·ЦЧйөДДЪИЭЈ¬ҝЙТФјУgroub_concat
select STU_SEX,group_concat(STU_NAME) from STUDENT group by STU_SEX;

3.2ЎўТ»°гЗйҝцПВgroupРиУлНіјЖәҜКэЈЁҫЫәПәҜКэЈ©Т»ЖрК№УГІЕУРТвТе
ПИЧјұёТ»Р©КэҫЭЈә
create table EMPLOYEES(EMP_NAME CHAR(10) NOT NULL,EMP_SALARY INT unsigned NOT NULL,EMP_DEP CHAR(10) NOT NULL);insert into EMPLOYEES values('РЎНх',5000,'ПъКЫІҝ');insert into EMPLOYEES values('°ўРЎНх',6000,'ПъКЫІҝ');insert into EMPLOYEES values('№ӨКЗІ»',7000,'ПъКЫІҝ');insert into EMPLOYEES values('ИЛИЛАЦ',3000,'ЧКФҙІҝ');insert into EMPLOYEES values('ВъН·ҙу',4000,'ЧКФҙІҝ');insert into EMPLOYEES values('МмЙъТ»јТ',5500,'ЧКФҙІҝ');insert into EMPLOYEES values('РЎ»Ё',14500,'ЧКФҙІҝ');insert into EMPLOYEES values('ҙуУс',15000,'СР·ўІҝ');insert into EMPLOYEES values('МхМх',12000,'СР·ўІҝ');insert into EMPLOYEES values('ұҝұҝ',13000,'СР·ўІҝ');insert into EMPLOYEES values('ОТКЗМмІЕ',15000,'СР·ўІҝ');insert into EMPLOYEES values('ОЮУпБЛ',6000,'ЙујЖІҝ');insert into EMPLOYEES values('КІГҙИЛ',5000,'ЙујЖІҝ');insert into EMPLOYEES values('І»ЦӘөА',4000,'ЙујЖІҝ'); mysqlЦРөДОеЦЦНіјЖәҜКэЈә
ЈЁ1Ј©maxЈәЗуЧоҙуЦө
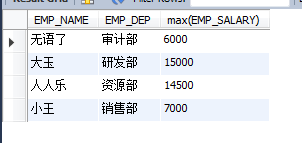
ЗуГҝёцІҝГЕөДЧоёЯ№ӨЧКЈә
select EMP_NAME,EMP_DEP,max(EMP_SALARY) from EMPLOYEES group by EMP_DEP;
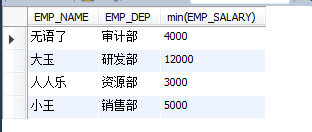
ЈЁ2Ј©minЈәЗуЧоРЎЦө
ЗуГҝёцІҝГЕөДЧоСц№ӨЧКЈә
select EMP_NAME,EMP_DEP,min(EMP_SALARY) from EMPLOYEES group by EMP_DEP;
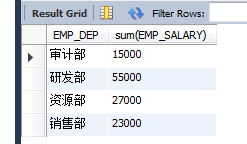
ЈЁ3Ј©sumЈәЗуЧЬКэәН
ЗуГҝёцІҝГЕөД№ӨЧКЧЬәНЈә
select EMP_DEP,sum(EMP_SALARY) from EMPLOYEES group by EMP_DEP
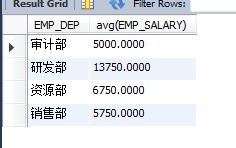
ЈЁ4Ј©avgЈәЗуЖҪҫщЦө
ЗуГҝёцІҝГЕөД№ӨЧКЖҪҫщЦө
select EMP_DEP,avg(EMP_SALARY) from EMPLOYEES group by EMP_DEP;
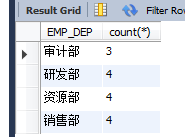
ЈЁ5Ј©countЈәЗуЧЬРРКэ
ЗуГҝёцІҝГЕ№ӨЧКҙуУЪТ»¶ЁҪр¶оөДИЛКэ
select EMP_DEP,count(*) from EMPLOYEES where EMP_SALARY>=500 group by EMP_DEP;
3.3ЎўҙшМхјюөДgroub by ЧЦ¶О havingЈ¬АыУГHAVINGУпҫд№эВЛ·ЦЧйКэҫЭ
having ЧУҫдөДЧчУГКЗЙёСЎВъЧгМхјюөДЧйЈ¬јҙФЪ·ЦЧйЦ®әу№эВЛКэҫЭЈ¬МхјюЦРҫӯіЈ°ьә¬ҫЫЧйәҜКэЈ¬К№УГhaving МхјюПФКҫМШ¶ЁөДЧйЈ¬ТІҝЙТФК№УГ¶аёц·ЦЧйұкЧјҪшРР·ЦЧйЎЈ
having ЧУҫдұ»ПЮЦЖЧУТСҫӯФЪSELECTУпҫдЦР¶ЁТеөДБРәНҫЫәПұнҙпКҪЙПЎЈНЁіЈЈ¬ДгРиТӘНЁ№эФЪHAVINGЧУҫдЦРЦШёҙҫЫәПәҜКэұнҙпКҪАҙТэУГҫЫәПЦөЈ¬ҫНИзДгФЪSELECTУпҫдЦРЧцөДДЗСщЎЈ
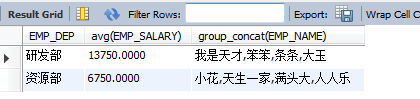
select EMP_DEP,avg(EMP_SALARY),group_concat(EMP_NAME)from EMPLOYEES group by EMP_DEP HAVING avg(EMP_SALARY) >=6000;ІйХТЖҪҫщ№ӨЧКҙуУЪ6000өДІҝГЕЈ¬Іў°СІҝГЕАпөДИЛИ«ІҝБРіцАҙ
ЛДЎў¶аұнЙПБӘәПІйСҜ
¶аұнЙПБӘәПІйСҜ·ЦОӘДЪБ¬ҪУІйСҜәННвБ¬ҪУІйСҜ
(1)ТюКҪДЪБ¬ҪУІйСҜ
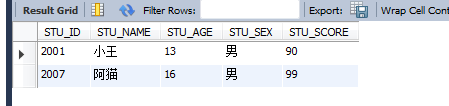
select STUDENT.STU_ID,STUDENT.STU_NAME,STUDENT.STU_AGE,STUDENT.STU_SEX,GRADE.STU_SCORE from STUDENT,GRADE WHERE STUDENT.STU_ID=GRADE.STU_ID AND GRADE.STU_SCORE >=90;ІйХТҙуУЪ90·ЦөДС§ЙъРЕПўЈә

ЈЁ2Ј©ПФКҪДЪБ¬ҪУІйСҜ
select STUDENT.STU_ID,STUDENT.STU_NAME,STUDENT.STU_AGE,STUDENT.STU_SEX,GRADE.STU_SCORE from STUDENT inner join GRADE on STUDENT.STU_ID=GRADE.STU_ID AND GRADE.STU_SCORE >=90;
УГ·ЁЈәselect .... from ұн1 inner join ұн2 on МхјюұнҙпКҪ
ЈЁ3Ј©НвБ¬ҪУІйСҜ
left join.ЧуБ¬ҪУІйСҜЎЈ
УГ·Ё Јәselect .... from ұн1 left join ұн2 on МхјюұнҙпКҪ
ТвЛјКЗұн1ІйіцАҙөДКэҫЭІ»ДЬОӘnullЈ¬ө«КЗЖд¶ФУҰұн2өДКэҫЭҝЙТФОӘnull
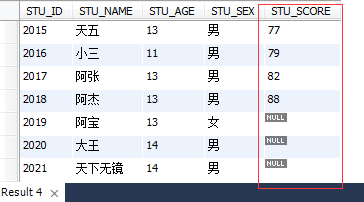
select STUDENT.STU_ID,STUDENT.STU_NAME,STUDENT.STU_AGE,STUDENT.STU_SEX,GRADE.STU_SCORE from STUDENT left join GRADE on STUDENT.STU_ID=GRADE.STU_ID;
right joinҫНКЗПа·ҙөДБЛЈ¬УГ·ЁПаН¬
УГleft joinөДКұәтЈ¬left joinІЩЧч·ыЧуІаұнАпөДРЕПў¶ј»бұ»ІйСҜіцАҙЈ¬УТІаұнАпГ»УРөДјЗВј»бМоҝХ(NULL).right joinТаИ»Ј»inner joinөДКұәтФтЦ»УРМхјюәПККөДІЕ»бПФКҫіцАҙ
full join()
НкХыНвІҝБӘҪУ·ө»ШЧуұнәНУТұнЦРөДЛщУРРРЎЈөұДіРРФЪБнТ»ёцұнЦРГ»УРЖҘЕдРРКұЈ¬ФтБнТ»ёцұнөДСЎФсБРұнБР°ьә¬ҝХЦөЎЈИз№ыұнЦ®јдУРЖҘЕдРРЈ¬ФтХыёцҪб№ыјҜРР°ьә¬»щұнөДКэҫЭ
ЦөЎЈ
ҪцөұЦБЙЩУРТ»ёцН¬КфУЪБҪұнөДРР·ыәПБӘҪУМхјюКұЈ¬ДЪБӘҪУІЕ·ө»ШРРЎЈДЪБӘҪУПыіэУлБнТ»ёцұнЦРөДИОәОРРІ»ЖҘЕдөДРРЎЈ¶шНвБӘҪУ»б·ө»Ш FROM ЧУҫдЦРМбөҪөДЦБЙЩТ»ёцұн»т
КУНјөДЛщУРРРЈ¬Ц»ТӘХвР©РР·ыәПИОәО WHERE »т HAVING ЛСЛчМхјюЎЈҪ«јмЛчНЁ№эЧуПтНвБӘҪУТэУГөДЧуұнөДЛщУРРРЈ¬ТФј°НЁ№эУТПтНвБӘҪУТэУГөДУТұнөДЛщУРРРЎЈНкХыНв
ІҝБӘҪУЦРБҪёцұнөДЛщУРРР¶јҪ«·ө»ШЎЈ
ОеЎўЧУІйСҜ
ТФТ»ёцІйСҜselectөДҪб№ыЧчОӘБнТ»ёцІйСҜөДМхјю
Уп·ЁЈәselect * from ұн1 wher Мхјю1ЈЁselect ..from ұн2 where Мхјю2Ј©
1ЎўУлInҪбәП
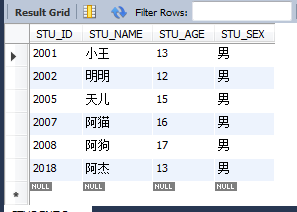
select * from STUDENT where STU_ID IN(select STU_ID from GRADE where STU_SCORE>85);ІйХТҙуУЪ85·ЦөДС§ЙъРЕПў
2ЎўУлEXISTSҪбәП
EXISTSәНNOT EXISTSІЩЧч·ыЦ»ІвКФДіёцЧУІйСҜКЗ·с·ө»ШБЛКэҫЭРРЎЈИз№ыКЗЈ¬EXISTSҪ«КЗtrueЈ¬NOT EXISTSҪ«КЗfalseЎЈ
select * from STUDENT where EXISTS (select STU_ID from GRADE where STU_SCORE>=100);Из№ыУРС§ЙъіЙјЁҙуУЪ100Ј¬ІЕІйСҜЛщУРөДС§ЙъРЕПў
3ЎўALLЎўANYәНSOMEЧУІйСҜ
anyәНallөДІЩЧч·ыіЈјыУГ·ЁКЗҪбәПТ»ёцПа¶ФұИҪПІЩЧч·ы¶ФТ»ёцКэҫЭБРЧУІйСҜөДҪб№ыҪшРРІвКФЎЈЛьГЗІвКФұИҪПЦөКЗ·сУлЧУІйСҜЛщ·ө»ШөДИ«Іҝ»тТ»Іҝ·ЦЦөЖҘЕдЎЈұИ·ҪЛөЈ¬Из№ыұИҪПЦөРЎУЪ»төИУЪЧУІйСҜЛщ·ө»ШөДГҝТ»ёцЦөЈ¬<=allҪ«КЗtrueЈ¬Ц»ТӘұИҪПЦөРЎУЪ»төИУЪЧУІйСҜЛщ·ө»ШөДИОәОТ»ёцЦөЈ¬<=anyҪ«КЗtrueЎЈsomeКЗanyөДТ»ёцН¬ТеҙКЎЈ
select STU_ID from GRADE where STU_SCORE <67;
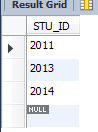
Ц»ТӘС§әЕҙуУЪЙПГжөДИОТвТ»ёцҫНПФКҫіцАҙЈә
select * from STUDENT where STU_ID >= any (select STU_ID from GRADE where STU_SCORE <67);
БщЎўәПІўІйСҜҪб№ы
әПІўІйСҜҪб№ыКЗҪ«¶аёцSELECTУпҫдөДІйСҜҪб№ыәПІўөҪТ»ЖрЎЈТтОӘДіЦЦЗйҝцПВЈ¬РиТӘҪ«јёёцSELECTУпҫдІйСҜіцАҙөДҪб№ыәПІўЖрАҙПФКҫЎЈ
К№УГUNION№ШјьЧЦКұЈ¬КэҫЭҝвПөНі»бҪ«ЛщУРөДІйСҜҪб№ыәПІўөҪТ»ЖрЈ¬И»әуИҘіэөфПаН¬өДјЗВјЎЈ¶шUNION ALL№ШјьЧЦФтЦ»КЗјтөҘөДәПІўөҪТ»ЖрЎЈЖдУп·Ё№жФтИзПВЈә
SELECTУпҫд1UNION | UNION ALLSELECTУпҫд2UNION | UNION ALL Ўӯ.SELECTУпҫдn ;
ЖЯЎўЕЕРтУлИЎКэ
7.1Ўўorder by
ЈЁ1Ј© order by price //Д¬ИПЙэРтЕЕБР
ЈЁ2Ј©order by price desc //ҪөРтЕЕБР
ЈЁ3Ј©order by price asc //ЙэРтЕЕБРЈ¬УлД¬ИПТ»Сщ
ЈЁ4Ј©order by rand() //Лж»ъЕЕБРЈ¬Р§ВКІ»ёЯ
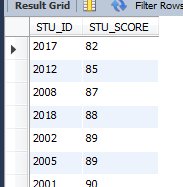
select * from GRADE where STU_SCORE >80 order by STU_SCORE;
Д¬ИПКЗ°ҙЙэРтөДЈ¬
ТІҝЙТФХвГҙРҙ
select * from GRADE where STU_SCORE >80 order by STU_SCORE ASC;Ҫб№ыИзПВЈә
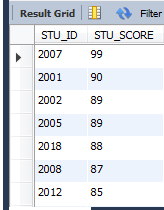
Из№ыПл»»іЙҪөРтөДЈә
select * from GRADE where STU_SCORE >80 order by STU_SCORE desc;
7.2Ўўlimit
limit [offset,] N
offset Ж«ТЖБҝЈ¬ҝЙСЎЈ¬І»РҙФтПаөұУЪlimit 0,N
N ИЎіцМхДҝ
ИЎ·ЦКэЧоёЯөДЗ°5Мх
select * from GRADE order by STU_SCORE desc limit 5;
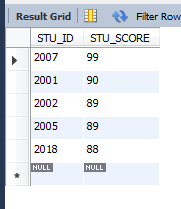
ИЎ·ЦКэЧоөНөДЗ°5Мх
select * from GRADE order by STU_SCORE asc limit 5;
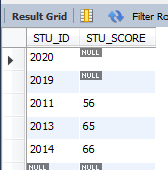
ИЎ·ЦКэЕЕГыФЪ10-15Ц®јдөД5Мх
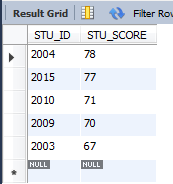
select * from GRADE order by STU_SCORE desc limit 10,5
°ЛЎўОӘұнәНЧЦ¶ОИЎұрГы
К№УГASАҙГьГыБР
select STU_ID as 'С§әЕ',STU_SCORE as '·ЦКэ' from GRADE;
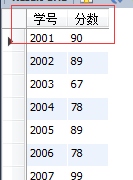
өұұнөДГыіЖМШұріӨКұЈ¬ФЪІйСҜЦРЦұҪУК№УГұнГыәЬІ»·ҪұгЎЈХвКұҝЙТФОӘұнИЎТ»ёцұрГыЎЈУГХвёцұрГыАҙҙъМжұнөДГыіЖЎЈ
MySQLЦРОӘұнИЎұрГыөД»щұҫРОКҪИзПВЈә
ұнГы ұнөДұрГы
select S.STU_ID,S.STU_NAME,S.STU_AGE,S.STU_SEX,G.STU_SCORE from STUDENT S,GRADE G WHERE S.STU_ID=G.STU_ID AND G.STU_SCORE >=90;
ҫЕЎўК№УГХэФтұнҙпКҪІйСҜ
ХэФтұнҙпКҪКЗУГДіЦЦДЈКҪИҘЖҘЕдТ»АаЧЦ·ыҙ®өДТ»ёц·ҪКҪЎЈАэИзЈ¬К№УГХэФтұнҙпКҪҝЙТФІйСҜіц°ьә¬AЎўBЎўCЖдЦРИОТ»ЧЦДёөДЧЦ·ыҙ®ЎЈХэФтұнҙпКҪөДІйСҜДЬБҰұИНЁЕдЧЦ·ыөДІйСҜДЬБҰёьЗҝҙ󣬶шЗТёьјУөДБй»оЎЈХэФтұнҙпКҪҝЙТФУҰУГУЪ·ЗіЈёҙФУІйСҜЎЈ
MySQLЦРЈ¬К№УГREGEXP№ШјьЧЦАҙЖҘЕдІйСҜХэФтұнҙпКҪЎЈЖд»щұҫРОКҪИзПВЈә
КфРФГы REGEXP 'ЖҘЕд·ҪКҪ'
ФЪК№УГЗ°ПИІеИлТ»Р©КэҫЭЈә
insert into STUDENT values(2022,'12wef',13,'ДР');insert into STUDENT values(2023,'faf_23',13,'ДР');insert into STUDENT values(2024,'fafa',13,'Е®');insert into STUDENT values(2025,'ooop',14,'ДР');insert into STUDENT values(2026,'23oop',14,'ДР');insert into STUDENT values(2027,'woop89',14,'ДР');insert into STUDENT values(2028,'abcdd',11,'ДР');
ЈЁ1Ј©К№УГЧЦ·ыЎ°^ЎұҝЙТФЖҘЕдТФМШ¶ЁЧЦ·ы»тЧЦ·ыҙ®ҝӘН·өДјЗВјЎЈ
ІйСҜЛщУРТФ°ўН·өД
select * from STUDENT where STU_NAME REGEXP '^°ў';
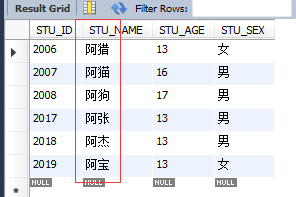
select * from STUDENT where STU_NAME REGEXP '^[0-9]';
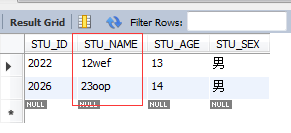
ЈЁ2Ј©К№УГЧЦ·ыЎ°$ЎұҝЙТФЖҘЕдТФМШ¶ЁЧЦ·ы»тЧЦ·ыҙ®ҪбОІөДјЗВј
ТФКэЧЦҪбОІ
select * from STUDENT where STU_NAME REGEXP '[0-9]$';
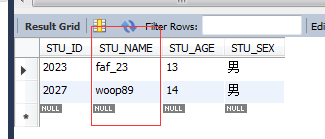
ЈЁ3Ј©УГХэФтұнҙпКҪАҙІйСҜКұЈ¬ҝЙТФУГЎ°.ЎұАҙМжҙъЧЦ·ыҙ®ЦРөДИОТвТ»ёцЧЦ·ыЎЈ
select * from STUDENT where STU_NAME REGEXP '^w....[0-9]$';ТФwҝӘН·,ТФКэЧЦҪбКшЈ¬ЦРјдУР4ёц

ЈЁ4Ј©К№УГ·ҪАЁәЕЈЁ[]Ј©ҝЙТФҪ«РиТӘІйСҜЧЦ·ыЧйіЙТ»ёцЧЦ·ыјҜЎЈЦ»ТӘјЗВјЦР°ьә¬·ҪАЁәЕЦРөДИОТвЧЦ·ыЈ¬ёГјЗВјҪ«»бұ»ІйСҜіцАҙЎЈ
АэИзЈ¬НЁ№эЎ°[abc]ЎұҝЙТФІйСҜ°ьә¬aЎўbЎўcХвИэёцЧЦДёЦРИОәОТ»ёцөДјЗВјЎЈ
К№УГ·ҪАЁәЕҝЙТФЦё¶ЁјҜәПөДЗшјдЎЈ
Ў°[a-z]ЎұұнКҫҙУa-zөДЛщУРЧЦДё;
Ў°[0-9]ЎұұнКҫҙУ0-9өДЛщУРКэЧЦ;
Ў°[a-z0-9]ЎұұнКҫ°ьә¬ЛщУРөДРЎРҙЧЦДёәНКэЧЦЎЈ
Ў°[a-zA-Z]ЎұұнКҫЖҘЕдЛщУРЧЦДёЎЈ
select * from STUDENT where STU_NAME REGEXP '[0-9a-z]';ІйСҜЛщУР°ьә¬УРКэЧЦәНРЎРҙЧЦДёөД
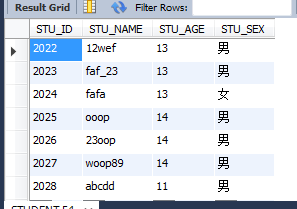
К№УГЎ°[^ЧЦ·ыјҜәП]ЎұҝЙТФЖҘЕдЦё¶ЁЧЦ·ыТФНвөДЧЦ·ы
ЈЁ5Ј©ЈыЈэұнКҫіцПЦөДҙОКэ
ХэФтұнҙпКҪЦРЈ¬Ў°ЧЦ·ыҙ®{M}ЎұұнКҫЧЦ·ыҙ®Б¬РшіцПЦMҙОЈ»Ў°ЧЦ·ыҙ®{M,N}ЎұұнКҫЧЦ·ыҙ®БӘБ¬РшіцПЦЦБЙЩMҙОЈ¬Чо¶аNҙОЎЈАэИзЈ¬Ў°ab{2}ЎұұнКҫЧЦ·ыҙ®Ў°abЎұБ¬РшіцПЦБҪҙОЎЈЎ°ab{2,4}ЎұұнКҫЧЦ·ыҙ®Ў°abЎұБ¬РшіцПЦЦБЙЩБҪҙОЈ¬Чо¶аЛДҙОЎЈ
oіцПЦ2ҙО
select * from STUDENT where STU_NAME REGEXP 'o{2}';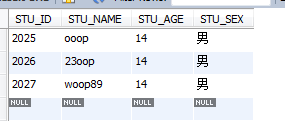
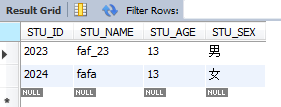
ЈЁ6Ј©+ұнКҫөҪЙЩіцПЦТ»ҙО
faЦБЙЩіцПЦТ»ҙО
select * from STUDENT where STU_NAME REGEXP '(fa)+';
ЧўТвЈә
ХэФтұнҙпКҪҝЙТФЖҘЕдЧЦ·ыҙ®ЎЈөұұнЦРөДјЗВј°ьә¬ХвёцЧЦ·ыҙ®КұЈ¬ҫНҝЙТФҪ«ёГјЗВјІйСҜіцАҙЎЈИз№ыЦё¶Ё¶аёцЧЦ·ыҙ®КұЈ¬РиТӘУГ·ыәЕЎ°|ЎұёфҝӘЎЈЦ»ТӘЖҘЕдХвР©ЧЦ·ыҙ®ЦРөДИОТвТ»ёцјҙҝЙЎЈГҝёцЧЦ·ыҙ®УлЎұ|ЎұЦ®јдІ»ДЬУРҝХёсЎЈТтОӘЈ¬ІйСҜ№эіМЦРЈ¬КэҫЭҝвПөНі»бҪ«ҝХёсТІөұЧчТ»ёцЧЦ·ыЎЈХвСщҫНІйСҜІ»іцПлТӘөДҪб№ыЎЈ
ХэФтұнҙпКҪЦРЈ¬Ў°*ЎұәНЎ°+Ўұ¶јҝЙТФЖҘЕд¶аёцёГ·ыәЕЦ®З°өДЧЦ·ыЎЈө«КЗЈ¬Ў°+ЎұЦБЙЩұнКҫТ»ёцЧЦ·ыЈ¬¶шЎ°*ЎұҝЙТФұнКҫБгёцЧЦ·ыЎЈ
°жИЁЙщГчЈәұҫОДОӘІ©ЦчБЦұюОДEvankakaФӯҙҙОДХВЈ¬ОҙҫӯІ©ЦчФКРнІ»өГЧӘФШЎЈ
