?网上看见了好多例子都基本上是一样的,没有过多的解释,对于一个初学MySQL来说有点难,我把部分转摘过来如下 原文:http://www.cnblogs.com/buro79xxd/archive/2012/08/29/2662489.html
要求目标:1.确定需求: 根据部门来分组,显示各员工在部门里按薪水排名名次.
创建表格:2.来创建实例数据:
drop table if exists heyf_t10;
(9,50,7500.00);
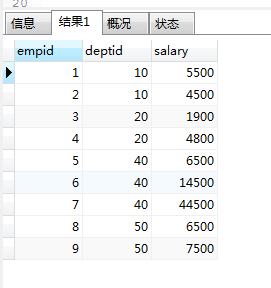
数据效果图:
实现?3. http://www.kaishixue.com/mysql/14.html 帖子中SQL的实现
SELECT
empid,
deptid,
salary,
rank
FROM
(
SELECT
heyf_tmp.empid,
heyf_tmp.deptid,
heyf_tmp.salary,
IF (
@pdept = heyf_tmp.deptid ,@rank :[email protected] + 1 ,@rank := 1
) AS rank,
@pdept := heyf_tmp.deptid
FROM
(
SELECT
empid,
deptid,
salary
FROM
heyf_t10
ORDER BY
deptid ASC,
salary DESC
) heyf_tmp,
(
SELECT
@pdept := NULL ,@rank := 0
) a
) result;
CREATE PROCEDURE testrank ()
BEGIN
SET @num = 0;
SET @pdept = NULL;
SELECT
result.empid,
result.deptid,
result.salary,
result.rank
FROM
(
SELECT
s.empid,
s.deptid,
s.salary,
IF (
@pdept = s.deptid ,@num :[email protected] + 1 ,@num := 1
) AS rank,
@pdept := s.deptid
FROM
heyf_t10 s
ORDER BY
s.deptid ASC,
s.salary DESC
) result;
END
执行 语句?call testrank();
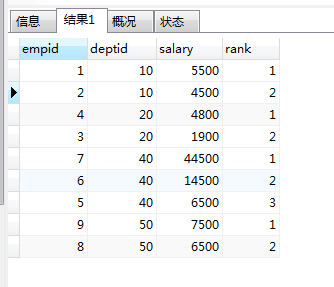
结果图:
SELECT
h.`empid`,
h.`deptid`,
h.`salary`,
count(*) AS rank
FROM
heyf_t10 AS h
LEFT OUTER JOIN heyf_t10 AS r ON h.deptid = r.deptid
AND h.`salary` <= r.`salary`
GROUP BY
h.`empid`,
h.`deptid`,
h.`salary`
ORDER BY
h.deptid,
h.salary DESC;
他们谁好谁差不清楚 反正多了一个思路。这样就是好的。