зЊдиЧызЂУїГіДІЃЁ
дЮФСДНгЃКhttp://blog.csdn.net/zgyulongfei/article/details/7909006
гаЪБКђгЩгкжжжждвђЃЌЮвУЧашвЊВЩМЏФГИіЭјеОЕФЪ§ОнЃЌЕЋгЩгкВЛЭЌЭјеОЖдЪ§ОнЕФЯдЪОЗНЪНТдгаВЛЭЌЃЁ
БОЮФОЭгУJavaИјДѓМвбнЪОШчКЮзЅШЁЭјеОЕФЪ§ОнЃКЃЈ1ЃЉзЅШЁдЭјвГЪ§ОнЃЛЃЈ2ЃЉзЅШЁЭјвГJavascriptЗЕЛиЕФЪ§ОнЁЃ
вЛЁЂзЅШЁдЭјвГЁЃ
етИіР§згЮвУЧзМБИДгhttp://ip.chinaz.comЩЯзЅШЁipВщбЏЕФНсЙћЃК
ЕквЛВНЃКДђПЊетИіЭјвГЃЌШЛКѓЪфШыIPЃК111.142.55.73ЃЌЕуЛїВщбЏАДХЅЃЌОЭПЩвдПДЕНЭјвГЯдЪОЕФНсЙћЃК

ЕкЖўВНЃКВщПДЭјвГдДТыЃЌЮвУЧПДЕНдДТыжагаетУДвЛЖЮЃК

ДгетРяПЩвдПДГіЃЌВщбЏЕФНсЙћЃЌЪЧжиаТЧыЧѓвЛИіЭјвГжЎКѓЯдЪОЕФЁЃ
дйПДПДВщбЏжЎКѓЕФЭјвГЕижЗЃК
вВОЭЪЧЫЕЃЌЮвУЧжЛвЊЗУЮЪаЮШчетбљЕФЭјжЗЃЌОЭПЩвдЕУЕНipВщбЏЕФНсЙћЃЌНгЯТРДПДДњТыЃК
public void captureHtml(String ip) throws Exception {
String strURL = "http://ip.chinaz.com/?IP=" + ip;
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
String buf = contentBuf.toString();
int beginIx = buf.indexOf("ВщбЏНсЙћ[");
int endIx = buf.indexOf("ЩЯУцЫФЯювРДЮЯдЪОЕФЪЧ");
String result = buf.substring(beginIx, endIx);
System.out.println("captureHtml()ЕФНсЙћЃК\n" + result);
}ЪЙгУHttpURLConnectionСЌНгЭјеОЃЌгУbufReaderБЃДцЭјвГЗЕЛиЕФЪ§ОнЃЌШЛКѓЭЈЙ§здЖЈвхЕФвЛИіНтЮіЗНЪННЋНсЙћЯдЪОГіРДЁЃ
етРяЮвжЛЪЧЫцБуЕФНтЮіСЫвЛЯТЃЌвЊНтЮіЕФЗЧГЃзМШЗЕФЛАздМКашдйДІРэЁЃ
НтЮіНсЙћШчЯТЃК
captureHtml()ЕФНсЙћЃК
ВщбЏНсЙћ[1]: 111.142.55.73 ==>> 1871591241 ==>> ИЃНЈЪЁеФжнЪа вЦЖЏ</strong><br />
ЖўЁЂзЅШЁЭјвГJavaScriptЗЕЛиЕФНсЙћЁЃ
гаЪБКђЭјеОЮЊСЫБЃЛЄздМКЕФЪ§ОнЃЌВЂУЛгаАбЪ§ОнжБНгЗХдкЭјвГдДТыжаЗЕЛиЃЌЖјЪЧВЩгУвьВНЕФЗНЪНЃЌгУJSЗЕЛиЪ§ОнЃЌетбљПЩвдБмУтЫбЫїв§ЧцЕШЙЄОпЖдЭјеОЪ§ОнЕФзЅШЁЁЃ
ЪзЯШПДвЛЯТетИіЭјвГЃК
гУЕквЛжжЗНЪНВщПДИУЭјвГЕФдДТыЃЌШДУЛгаЗЂЯжИУдЫЕЅЕФИњзйаХЯЂЃЌвђЮЊЫќЪЧЭЈЙ§JSЕФЗНЪНЛёШЁНсЙћЕФЁЃ
ЕЋгаЪБКђЮвУЧКмашвЊЛёШЁЕНJSЕФЪ§ОнЃЌетИіЪБКђвЊдѕУДАьФиЃП
етИіЪБКђЮвУЧашвЊгУЕНвЛИіЙЄОпЃКHTTP AnalyzerЃЌетИіЙЄОпПЩвдНиЛёHttpЕФНЛЛЅФкШнЃЌЮвУЧЭЈЙ§етИіЙЄОпРДДяЕНЮвУЧЕФФПЕФЁЃ
ЪзЯШЕуЛїStartАДХЅжЎКѓЃЌЫќОЭПЊЪММрЬ§ЭјвГЕФНЛЛЅааЮЊСЫЁЃ
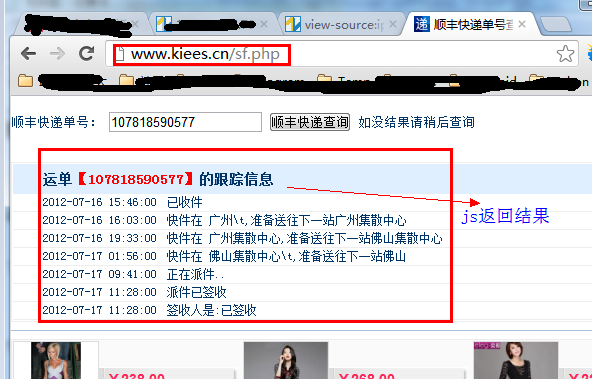
ЮвУЧДђПЊЭјвГЃКhttp://www.kiees.cn/sf.php ЃЌПЩвдПДЕНHTTP AnalyzerСаГіСЫЫљгаИУЭјвГЕФЧыЧѓЪ§ОнвдМАНсЙћЃК
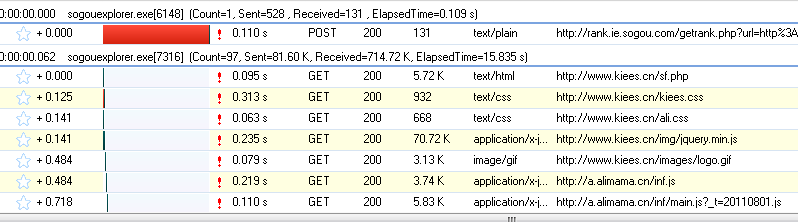
ЮЊСЫИќЗНБуЕФВщПДJSЕФНсЙћЃЌЮвУЧЯШЧхПеетаЉЪ§ОнЃЌШЛКѓдйЭјвГжаЪфШыПьЕнЕЅКХЃК107818590577ЃЌЕуЛїВщбЏАДХЅЃЌШЛКѓВщПДHTTP AnalyzerЕФНсЙћЃК

етИіОЭЪЧЕуЛїВщбЏАДХЅжЎКѓЃЌHTTP AnalyzerЕФНсЙћЃЌЮвУЧМЬајВщПДЃК
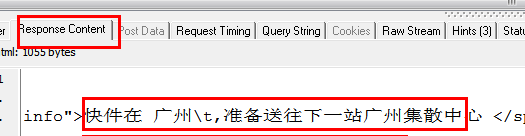
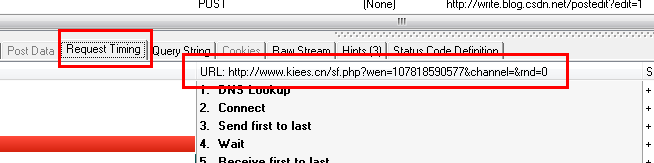
ДгЩЯУцСНЗљЭМжаПЩвдПДГіЃЌHTTP AnalyzerПЩвдНиЛёJSЗЕЛиЕФЪ§ОнЃЌВЂдкResponse ContentжаЯдЪОЃЌЭЌЪБПЩвдПДЕНJSЧыЧѓЕФЭјвГЕижЗЁЃ
МШШЛШчДЫЃЌЮвУЧжЛвЊЗжЮіHTTP AnalyzerЕФНсЙћЃЌШЛКѓФЃФтJSЕФааЮЊОЭПЩЛёШЁЕНЪ§ОнЃЌМДЮвУЧжЛвЊЗУЮЪJSЧыЧѓЕФЭјвГЕижЗРДЛёШЁЪ§ОнЃЌЕБШЛЧАЬсЪЧетаЉЪ§ОнЪЧУЛгаОЙ§МгУмЕФЃЌЮвУЧМЧЯТJSЧыЧѓЕФURLЃКhttp://www.kiees.cn/sf.php?wen=107818590577&channel=&rnd=0
ШЛКѓШУГЬађШЅЧыЧѓетИіЭјвГЕФНсЙћМДПЩЃЁ
ЯТУцЪЧДњТыЃК
public void captureJavascript(String postid) throws Exception {
String strURL = "http://www.kiees.cn/sf.php?wen=" + postid
+ "&channel=&rnd=0";
URL url = new URL(strURL);
HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();
InputStreamReader input = new InputStreamReader(httpConn
.getInputStream(), "utf-8");
BufferedReader bufReader = new BufferedReader(input);
String line = "";
StringBuilder contentBuf = new StringBuilder();
while ((line = bufReader.readLine()) != null) {
contentBuf.append(line);
}
System.out.println("captureJavascript()ЕФНсЙћЃК\n" + contentBuf.toString());
}ПДЕНСЫАЩЃЌзЅШЁJSЕФЗНЪНКЭЧАУцзЅШЁдЭјвГЕФДњТывЛФЃвЛбљЃЌЮвУЧжЛВЛЙ§зіСЫвЛИіЗжЮіJSЕФЙ§ГЬЁЃ
ЯТУцЪЧГЬађжДааЕФНсЙћЃК
captureJavascript()ЕФНсЙћЃК
<div class="results"><div id="ali-itu-wl-result" class="ali-itu-wl-result"><h2 class="logisTitle">дЫЕЅ<span class="mail-no">ЁО107818590577ЁП</span>ЕФИњзйаХЯЂ</h2><div class="trace_result"><ul><li><span class="time">2012-07-16 15:46:00</span><span class="info">вбЪеМў </span></li><li><span class="time">2012-07-16 16:03:00</span><span class="info">ПьМўдк Йужн\t,зМБИЫЭЭљЯТвЛеОЙужнМЏЩЂжааФ </span></li><li><span class="time">2012-07-16 19:33:00</span><span class="info">ПьМўдк ЙужнМЏЩЂжааФ,зМБИЫЭЭљЯТвЛеОЗ№ЩНМЏЩЂжааФ </span></li><li><span class="time">2012-07-17 01:56:00</span><span class="info">ПьМўдк З№ЩНМЏЩЂжааФ\t,зМБИЫЭЭљЯТвЛеОЗ№ЩН </span></li><li><span class="time">2012-07-17 09:41:00</span><span class="info">е§дкХЩМў.. </span></li><li><span class="time">2012-07-17 11:28:00</span><span class="info">ХЩМўвбЧЉЪе </span></li><li><span class="time">2012-07-17 11:28:00</span><span class="info">ЧЉЪеШЫЪЧ:вбЧЉЪе </span></li></ul><div></div></div></div> </div>
етаЉЪ§ОнОЭЪЧJSЗЕЛиЕФНсЙћСЫЃЌЮвУЧЕФФПЕФДяЕНСЫЃЁ
ЯЃЭћБОЮФФмЙЛЖдашвЊЕФХѓгбгавЛЕуАяжњЃЌашвЊГЬађдДТыЕФЃЌЧыЕуЛїетРяЯТдиЃЁ