ѧ����ôЩ��Ļ���֪ʶ�����Լ����Ǹ����⺹���ѹ��Լ�һֱ��IJ���ô�����������Ķ�֪����û���ã��Dz��ǹ���ʱ����Щ֪ʶ�������أ���Щ֪ʶƽʱ�Ĺ����������������õģ�Ҳ������ƽʱһ��û�й�ע����Щ����֪ʶ��ֻ��������Ҳ�����ˡ�����д�ʼ�Ҳ�Ǹ���ϰ�ߣ��⿴һ���������ס������д�����Ǿͺ����࣬�Ժ������Ҳ����һЩ��
ΪʲôҪ��Hash Table��
����뵽����ǰ������������һ�����顣����ǰ�һ���дdelphi������������������������������㣬��������Ҫ��ȡ���ڴ��У�Ȼ�������ݼ��ϼ���б������ҶԱȣ������Ļ�������һ��ͻ�dz����������Ҿ����������ڴ����һֱҲ�Ҳ���ԭ������һλ����ḻ���ϳ���Ա���룬���������ʹ��hashtable�����������⡣
�������Թ�Ȼ����ȵ���������ܣ����¾��������£�
���ǵ����ݶ�����ͨ���Ա������ֶν��ж�λ�ģ�������ֶ���string���ͣ�����Ϊ40��Ҫ��һ�����ݼ�������һ�����ݾ�Ҫȥ������Ȼ��Ա������Ƿ���ͬ��������������⣺
1���ַ������ַ������бȽ�����������ⲻ�������������Ļ����Ǹ��ܴ�����⣬�Ͼ�ÿ�ζ���40���ֽ���40�ֽڳ��ȶԱ�ѽ
2�����������Ǵ����ڴ������еģ���Ҫ��λһ�����ݾ�Ҫ�������ң����ο��Ǵ�����ѭ������
Ҫ�������������ֱ�Ҫ��ʲô��
1�����������ֶζԱ�ʱ��ʱ�䣬��������������ͣ�������ֻ��4���ֽ�
2���Ż��㷨��������ݲ���Ч�ʣ�����������ݶ�λ��Ч��
���Dz��õ�hashtable�ܷ�����ЩҪ��Hashtable�Ĵ洢�ṹʹ�õ��ǣ�����+�����ķ�ʽ��
���ȣ������ݴ��������У����������Ѱַ�������ͺܿ���
��Σ���Key����hash���㣬�����Ϳ���ʹ��Int���ͣ����ֽ�����ַ����Ƚϵ�����
�����˺ô������˼���ѧϰ��ȥ�Ķ����ˣ�һ�������ɡ�
ʲô��Hash Table
����Hash table����Ӧ�ò�İ�����ȿ��������
ɢ�б���Hash table��Ҳ�й�ϣ�������Ǹ��ݹؼ��֣�Key value����ֱ�ӷ������ڴ�洢λ�õ����ݽṹ��Ҳ����˵����ͨ���Ѽ�ֵͨ��һ�������ļ��㣬ӳ�䵽����һ��λ�������ʼ�¼����ӿ��˲����ٶȡ����ӳ�亯������ɢ�к�������ż�¼���������ɢ�б���
Ҫ����ľ���һ�㣬��Ҫ��ɢ�����������˽�һЩ�����Ǽ�����ά���ٿưɣ�һ��������⣺
- ���ؼ���Ϊ
������ֵ�����
�Ĵ洢λ���ϡ��ɴˣ�����Ƚϱ��ֱ��ȡ�������¼���������Ӧ��ϵ
Ϊɢ�к����������˼�뽨���ı�Ϊɢ�б���
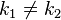 ����
����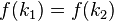 �����������Ϊ��ײ��
�����������Ϊ��ײ��
����˵�˼����Ƚ���Ҫ�ĸ���ؼ��֡�ɢ�к�������ײ��Ӧ��˵�Ѿ�˵�ĺ������ˣ�ûɶ��������ġ�
ɢ�к�����������ʵ�ַ���������Ҳ��һ�°ɣ�
ɢ�к�����ʹ��һ���������еķ��ʹ��̸���Ѹ����Ч��ͨ��ɢ�к���������Ԫ�ؽ������춨λ��
- ֱ�Ӷ�ַ����ȡ�ؼ��ֻ�ؼ��ֵ�ij�����Ժ���ֵΪɢ�е�ַ����
��
������
Ϊ����������ɢ�к�����������������
- ���ַ�����������ؼ�������rΪ�����������ҹ�ϣ���п��ܳ��ֵĹؼ��ֶ�������֪���ģ����ȡ�ؼ��ֵ�������λ��ɹ�ϣ��ַ��
- ƽ��ȡ�з���ȡ�ؼ���ƽ������м伸λΪ��ϣ��ַ��ͨ����ѡ����ϣ����ʱ��һ����֪���ؼ��ֵ�ȫ�������ȡ���е��ļ�λҲ��һ�����ʣ���һ����ƽ������м伸λ��������ÿһλ����أ��ɴ�ʹ����ֲ��Ĺؼ��ֵõ��Ĺ�ϣ��ַҲ������ġ�ȡ��λ���ɱ���������
- �۵��������ؼ��ַָ��λ����ͬ�ļ����֣����һ���ֵ�λ�����Բ�ͬ����Ȼ��ȡ�⼸���ֵĵ��Ӻͣ���ȥ��λ����Ϊ��ϣ��ַ��
- ������������ؼ��ַָ��λ����ͬ�ļ����֣����һ����λ�����Բ�ͬ��Ȼ��ȡ�⼸���ֵĵ��Ӻͣ�ȥ����λ����Ϊɢ�е�ַ����λ���ӿ�������λ���Ӻͼ��������ַ�������λ�����ǽ��ָ���ÿһ���ֵ����λ���룬Ȼ����ӣ��������Ǵ�һ������һ���طָ�������۵���Ȼ�������ӡ�
- ������������ȡ�ؼ��ֱ�ij��������ɢ�б�����m����p�������õ�����Ϊɢ�е�ַ����
,
���������ԶԹؼ���ֱ��ȡģ��Ҳ�����۵�����ƽ��ȡ�з�������֮��ȡģ����p��ѡ�����Ҫ��һ��ȡ������m����pѡ�ã����ײ�����ײ��
�е��������Ǿ���ֱ����ij�����ֻ���ͨ������õ�һ��������Ϊ������±꣬���Ǵ洢��λ�õ�ַ����������ȡ������ֱ�Ӷ�λ�ˣ���Ч����������һ�ַ�������һ����ͬ�����⣬����hash������������ͬ��Ҳ������ײ���⡣��ô�͵��а취ȥ��������⣬���˿������м��ַ�����
- ���Ŷ�ַ�������������ͻ�ͼ�������һ���յ�ɢ�е�ַ
- ���������������ڷ�����ͻ��λ��ֱ��ʹ�����������ͻ������
- ��ɢ���������ϴ�ɢ�м��㷢����ײʱ������һ��ɢ�к��������µ�ɢ�к�����ַ��ֱ����ײ���ٷ���
- ������������������������������������ͻ�ľͷŵ������
�ο����£�
http://zh.wikipedia.org/zh/%E5%93%88%E5%B8%8C%E8%A1%A8
http://c.biancheng.net/cpp/html/1031.html
��ѧϰ��Hash Table�Ļ���
�������Ҳ����˽���HashTable��������ô��������������˼���ѧϰHashTable�Ķ�����ǰ���ᵽ���Ǹ�Delphi��Hash Table��ʹ�õĴ洢�ṹ������+��������ʽ��Դ����Ҳ�Ҳ����ˣ��������Java��Hash Table����Ϊ������ѧϰ�ɡ�
�洢�ṹ
����Java SDK��Ĭ��ʵ�ֵ�HashTable��ʹ�õĴ洢�ṹ������+������������ǰ��ĸ���������ˣ����鼴�����ڴ洢���ݵ������ĵ�ַ�ռ䣬�����������������ײ����ġ������������������Ч��Ѱַ��������ͨ�������������ײ�Ĵ洢���⡣
�ȿ����飺
/*** The hash table data.*/private transient Entry[] table;
�ٿ���������
/** * Hashtable collision list. */ private static class Entry<K,V> implements Map.Entry<K,V> { int hash; K key; V value; Entry<K,V> next; protected Entry(int hash, K key, V value, Entry<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } protected Object clone() { return new Entry<K,V>(hash, key, value, (next==null ? null : (Entry<K,V>) next.clone())); } // Map.Entry Ops public K getKey() { return key; } public V getValue() { return value; } public V setValue(V value) { if (value == null) throw new NullPointerException(); V oldValue = this.value; this.value = value; return oldValue; } public boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; return (key==null ? e.getKey()==null : key.equals(e.getKey())) && (value==null ? e.getValue()==null : value.equals(e.getValue())); } public int hashCode() { return hash ^ (value==null ? 0 : value.hashCode()); } public String toString() { return key.toString()+"="+value.toString(); } }
��ʵ����ͦ�ģ�����һ��Entry���飬��Entry����һ����ֵ��ϵ����ͬʱ�ṩ�������Ĺ��ܡ�
���ݴ�ȡ
д����ô����룬��Hashtable�Ĵ��뷢��Ҳ������Щ�����ɣ��ؼ����Ǿ��Ǵ���ȡ��
�ȿ���һ�����ݵķ���put:
public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } // Makes sure the key is not already in the hashtable. Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { V old = e.value; e.value = value; return old; } } modCount++; if (count >= threshold) { // Rehash the table if the threshold is exceeded rehash(); tab = table; index = (hash & 0x7FFFFFFF) % tab.length; } // Creates the new entry. Entry<K,V> e = tab[index]; tab[index] = new Entry<K,V>(hash, key, value, e); count++; return null; }
- ��������߳�ͬ���ؼ��֣���Ϊ����hashtable�����߳�ͬ���ģ��������߳�����Ҳ��ľ�������
- ע��valua�Dz���Ϊnull�Ļ����쳣
- ��Ҫ���������key-value�ķ�ʽ�Ž�ȥ����ͨ��key����Hashֵ����������λ��
�����ؼ����룺
int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length;
�ȵõ�key��hashcode����ͨ�������������õ�������������Ч�͵õ��˴洢λ�á�
- Ȼ�����Ĵ��뿴����û����ͬ����Ŀ�������滻֮�����һ��Entry�������ݣ����������ײEntry���Զ�д�������н����ͻ��
������ݵķ�������get��
public synchronized V get(Object key) { Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return e.value; } } return null; }
���������±�ķ�����һ���ģ������Ķ�λ��ʽ�ر��Ч��ֻҪ����һ�ξͿ����ˣ���Ȼ����г�ͻ�Ļ���Ҫ���������Ա�hash��key��ȷ�����յ������
�ٿ���HashMap
��haspMap��ʵ�ֵ�˼����ʵ��hashtable������ͬ���洢�ṹҲ���ƣ�ֻ��һЩС����
- key��value֧��null��������������Ǵ��������еĵ�һ��Ԫ���У��о�����������������Ӧ��
- �����̰߳�ȫ�ģ���Ҫ�Լ����߳�ͬ��
- ����洢λ��ʱ��������hashcode���ٴ�hash+indexFor�ķ�����ʹ�õõ���ɢ��ֵ������