初识HashMap
之前的List,讲了ArrayList、LinkedList,最后讲到了CopyOnWriteArrayList,就前两者而言,反映的是两种思想:
(1)ArrayList以数组形式实现,顺序插入、查找快,插入、删除较慢
(2)LinkedList以链表形式实现,顺序插入、查找较慢,插入、删除方便
那么是否有一种数据结构能够结合上面两种的优点呢?有,答案就是HashMap。
HashMap是一种非常常见、方便和有用的集合,是一种键值对(K-V)形式的存储结构,下面将还是用图示的方式解读HashMap的实现原理,
四个关注点在HashMap上的答案
| 关 注 点 | 结 论 |
| HashMap是否允许空 | Key和Value都允许为空 |
| HashMap是否允许重复数据 | Key重复会覆盖、Value允许重复 |
| HashMap是否有序 | 无序,特别说明这个无序指的是遍历HashMap的时候,得到的元素的顺序基本不可能是put的顺序 |
| HashMap是否线程安全 | 非线程安全 |
添加数据
首先看一下HashMap的一个存储单元Entry:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash; ...}
之前一篇写LinkedList的文章,里面写到LinkedList是一个双向链表,从HashMap的Entry看得出,Entry组成的是一个单向链表,因为里面只有Entry的后继Entry,而没有Entry的前驱Entry。用图表示应该是这么一个数据结构:
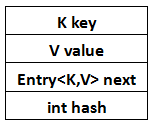
接下来,假设我有这么一段代码:
1 public static void main(String[] args)2 {3 Map<String, String> map = new HashMap<String, String>();4 map.put("111", "111");5 map.put("222", "222");6 }
看一下做了什么。首先从第3行开始,new了一个HashMap出来:
1 public HashMap() {2 this.loadFactor = DEFAULT_LOAD_FACTOR;3 threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);4 table = new Entry[DEFAULT_INITIAL_CAPACITY];5 init();6 }
注意一下第5行的init()是个空方法,它是HashMap的子类比如LinkedHashMap构造的时候使用的。DEFAULT_INITIAL_CAPACITY为16,也就是说,HashMap在new的时候构造出了一个大小为16的Entry数组,Entry内所有数据都取默认值,如图示为:

看到new出了一个大小为16的Entry数组来。接着第4行,put了一个Key和Value同为111的字符串,看一下put的时候底层做了什么:
1 public V put(K key, V value) { 2 if (key == null) 3 return putForNullKey(value); 4 int hash = hash(key.hashCode()); 5 int i = indexFor(hash, table.length); 6 for (Entry<K,V> e = table[i]; e != null; e = e.next) { 7 Object k; 8 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 9 V oldValue = e.value;10 e.value = value;11 e.recordAccess(this);12 return oldValue;13 }14 }15 16 modCount++;17 addEntry(hash, key, value, i);18 return null;19 }
1 static int hash(int h) {2 // This function ensures that hashCodes that differ only by3 // constant multiples at each bit position have a bounded4 // number of collisions (approximately 8 at default load factor).5 h ^= (h >>> 20) ^ (h >>> 12);6 return h ^ (h >>> 7) ^ (h >>> 4);7 }
1 static int indexFor(int h, int length) { 2 return h & (length-1); 3 }
看一下put方法的几个步骤:
1、第2行~第3行就是HashMap允许Key值为空的原因,空的Key会默认放在第0位的数组位置上
2、第4行拿到Key值的HashCode,由于HashCode是Object的方法,因此每个对象都有一个HashCode,对这个HashCode做一次hash计算。按照JDK源码注释的说法,这次hash的作用是根据给定的HashCode对它做一次打乱的操作,防止一些糟糕的Hash算法产生的糟糕的Hash值,至于为什么要防止糟糕的Hash值,HashMap添加元素的最后会讲到
3、第5行根据重新计算的HashCode,对Entry数组的大小取模得到一个Entry数组的位置。看到这里使用了&,移位加快一点代码运行效率。另外,这个取模操作的正确性依赖于length必须是2的N次幂,这个熟悉二进制的朋友一定理解,因此注意HashMap构造函数中,如果你指定HashMap初始数组的大小initialCapacity,如果initialCapacity不是2的N次幂,HashMap会算出大于initialCapacity的最小2的N次幂的值,作为Entry数组的初始化大小。这里为了讲解方便,我们假定字符串111和字符串222算出来的i都是1
4、第6行~第14行会先判断一下原数据结构中是否存在相同的Key值,存在则覆盖并返回,不执行后面的代码。注意一下recordAccess这个方法,它也是HashMap的子类比如LinkedHashMap用的,HashMap中这个方法为空。另外,注意一点,对比Key是否相同,是先比HashCode是否相同,HashCode相同再判断equals是否为true,这样大大增加了HashMap的效率,对HashCode不熟悉的朋友可以看一下我的这篇文章讲讲HashCode的作用
5、第16行的modeCount++是用于fail-fast机制的,每次修改HashMap数据结构的时候都会自增一次这个值
然后就到了关键的addEntry方法了:
void addEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<K,V>(hash, key, value, e); if (size++ >= threshold) resize(2 * table.length);}
Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h;}
假定原先table[1]位置的地址为0x00000000,new出来的Entry地址为0x00000001,那么,put("111", "111")用图表示应该是这样的:
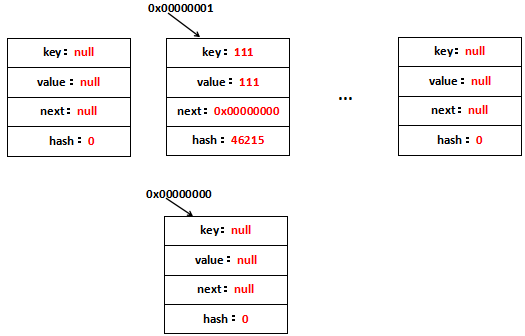
每一个新增的Entry都位于table[1]上,另外,里面的hash是rehash之后的hash而不是Key最原始的hash。看到table[1]上存放了111---->111这个键值对,它持有原table[1]的引用地址,因此可以寻址到原table[1],这就是单向链表。 再看一下put("222", "222")做了什么,一张图就可以理解了:
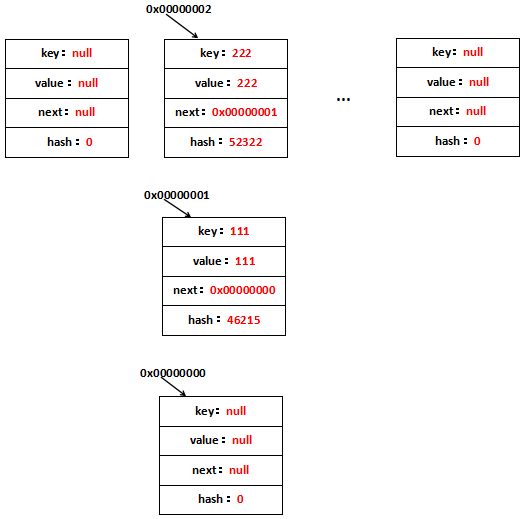
新的Entry再次占据table[1]的位置,并且持有原table[1],也就是111---->111这个键值对。
至此,HashMap进行put数据的过程就呈现清楚了。不过还有一个问题,就是HashMap如何进行扩容,再看一下addEntry方法:
1 void addEntry(int hash, K key, V value, int bucketIndex) { 2 Entry<K,V> e = table[bucketIndex]; 3 table[bucketIndex] = new Entry<K,V>(hash, key, value, e); 4 if (size++ >= threshold) 5 resize(2 * table.length); 6 }
看到第4行~第5行,也就是说在每次放置完Entry之后都会判断是否需要扩容。这里不讲扩容是因为HashMap扩容在不正确的使用场景下将会导致死循环,这是一个值得探讨的话题,也是我工作中实际遇到过的一个问题,因此下一篇文章将会详细说明为什么不正确地使用HashMap会导致死循环。
删除数据
有一段代码:
1 public static void main(String[] args)2 {3 Map<String, String> map = new HashMap<String, String>();4 map.put("111", "111");5 map.put("222", "222");6 map.remove("111");7 }
第6行删除元素,看一下删除元素的时候做了什么,第4行~第5行添加了两个键值对就沿用上面的图,HashMap删除指定键值对的源代码是:
1 public V remove(Object key) { 2 Entry<K,V> e = removeEntryForKey(key); 3 return (e == null ? null : e.value); 4 }
1 final Entry<K,V> removeEntryForKey(Object key) { 2 int hash = (key == null) ? 0 : hash(key.hashCode()); 3 int i = indexFor(hash, table.length); 4 Entry<K,V> prev = table[i]; 5 Entry<K,V> e = prev; 6 7 while (e != null) { 8 Entry<K,V> next = e.next; 9 Object k;10 if (e.hash == hash &&11 ((k = e.key) == key || (key != null && key.equals(k)))) {12 modCount++;13 size--;14 if (prev == e)15 table[i] = next;16 else17 prev.next = next;18 e.recordRemoval(this);19 return e;20 }21 prev = e;22 e = next;23 }24 25 return e;26 }
分析一下remove元素的时候做了几步:
1、根据key的hash找到待删除的键值对位于table的哪个位置上
2、记录一个prev表示待删除的Entry的前一个位置Entry,e可以认为是当前位置
3、从table[i]开始遍历链表,假如找到了匹配的Entry,要做一个判断,这个Entry是不是table[i]:
(1)是的话,也就是第14行~第15行,table[i]就直接是table[i]的下一个节点,后面的都不需要动
(2)不是的话,也就是第16行~第17行,e的前一个Entry也就是prev,prev的next指向e的后一个节点,也就是next,这样,e所代表的Entry就被踢出了,e的前后Entry就连起来了
remove("111")用图表示就是:
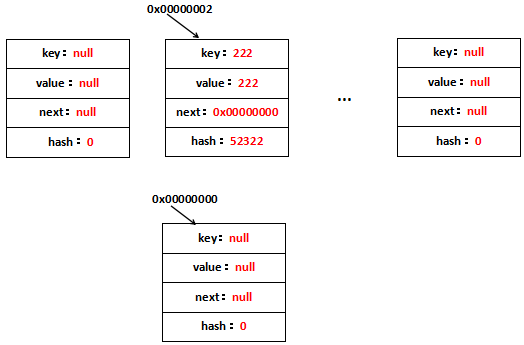
整个过程只需要修改一个节点的next的值即可,非常方便。
修改数据
修改元素也是put,看一下源代码:
1 public V put(K key, V value) { 2 if (key == null) 3 return putForNullKey(value); 4 int hash = hash(key.hashCode()); 5 int i = indexFor(hash, table.length); 6 for (Entry<K,V> e = table[i]; e != null; e = e.next) { 7 Object k; 8 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 9 V oldValue = e.value;10 e.value = value;11 e.recordAccess(this);12 return oldValue;13 }14 }15 modCount++;16 addEntry(hash, key, value, i);17 return null;18 }
这个其实前面已经提到过了,第6行~第14行就是修改元素的逻辑,如果某个Key已经在数据结构中存在的话,那么就会覆盖原value,也就是第10行的代码。
插入数据
所谓"插入元素",在我的理解里,一定是基于数据结构是有序的前提下的。像ArrayList、LinkedList,再远点说就是数据库,一条一条都是有序的。
而HashMap,它的顺序是基于HashCode,HashCode是一个随机性很强的数字,所以HashMap中的Entry完全是随机存放的。HashMap又不像LinkedHashMap这样维护了插入元素的顺序,所以对HashMap这个数据结构谈插入元素是没有意义的。
所以,HashMap并没有插入的概念。
再谈HashCode的重要性
前面讲到了,HashMap中对Key的HashCode要做一次rehash,防止一些糟糕的Hash算法生成的糟糕的HashCode,那么为什么要防止糟糕的HashCode?
糟糕的HashCode意味着的是Hash冲突,即多个不同的Key可能得到的是同一个HashCode,糟糕的Hash算法意味着的就是Hash冲突的概率增大,这意味着HashMap的性能将下降,表现在两方面:
1、有10个Key,可能6个Key的HashCode都相同,另外四个Key所在的Entry均匀分布在table的位置上,而某一个位置上却连接了6个Entry。这就失去了HashMap的意义,HashMap这种数据结构性高性能的前提是,Entry均匀地分布在table位置上,但现在确是1 1 1 1 6的分布。所以,我们要求HashCode有很强的随机性,这样就尽可能地可以保证了Entry分布的随机性,提升了HashMap的效率。
2、HashMap在一个某个table位置上遍历链表的时候的代码:
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
看到,由于采用了"&&"运算符,因此先比较HashCode,HashCode都不相同就直接pass了,不会再进行equals比较了。HashCode因为是int值,比较速度非常快,而equals方法往往会对比一系列的内容,速度会慢一些。Hash冲突的概率大,意味着equals比较的次数势必增多,必然降低了HashMap的效率了。
HashMap的table为什么是transient的
一个非常细节的地方:
transient Entry[] table;
看到table用了transient修饰,也就是说table里面的内容全都不会被序列化,不知道大家有没有想过这么写的原因?
在我看来,这么写是非常必要的。因为HashMap是基于HashCode的,HashCode作为Object的方法,是native的:
public native int hashCode();
这意味着的是:HashCode和底层实现相关,不同的虚拟机可能有不同的HashCode算法。再进一步说得明白些就是,可能同一个Key在虚拟机A上的HashCode=1,在虚拟机B上的HashCode=2,在虚拟机C上的HashCode=3。
这就有问题了,Java自诞生以来,就以跨平台性作为最大卖点,好了,如果table不被transient修饰,在虚拟机A上可以用的程序到虚拟机B上可以用的程序就不能用了,失去了跨平台性,因为:
1、Key在虚拟机A上的HashCode=100,连在table[4]上
2、Key在虚拟机B上的HashCode=101,这样,就去table[5]上找Key,明显找不到
整个代码就出问题了。因此,为了避免这一点,Java采取了重写自己序列化table的方法,在writeObject选择将key和value追加到序列化的文件最后面:
private void writeObject(java.io.ObjectOutputStream s) throws IOException{Iterator<Map.Entry<K,V>> i = (size > 0) ? entrySet0().iterator() : null;// Write out the threshold, loadfactor, and any hidden stuffs.defaultWriteObject();// Write out number of bucketss.writeInt(table.length);// Write out size (number of Mappings)s.writeInt(size); // Write out keys and values (alternating)if (i != null) { while (i.hasNext()) { Map.Entry<K,V> e = i.next(); s.writeObject(e.getKey()); s.writeObject(e.getValue()); } }}
而在readObject的时候重构HashMap数据结构:
private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException{// Read in the threshold, loadfactor, and any hidden stuffs.defaultReadObject();// Read in number of buckets and allocate the bucket array;int numBuckets = s.readInt();table = new Entry[numBuckets]; init(); // Give subclass a chance to do its thing.// Read in size (number of Mappings)int size = s.readInt();// Read the keys and values, and put the mappings in the HashMapfor (int i=0; i<size; i++) { K key = (K) s.readObject(); V value = (V) s.readObject(); putForCreate(key, value);}}
一种麻烦的方式,但却保证了跨平台性。
这个例子也告诉了我们:尽管使用的虚拟机大多数情况下都是HotSpot,但是也不能对其它虚拟机不管不顾,有跨平台的思想是一件好事。
HashMap和Hashtable的区别
HashMap和Hashtable是一组相似的键值对集合,它们的区别也是面试常被问的问题之一,我这里简单总结一下HashMap和Hashtable的区别:
1、Hashtable是线程安全的,Hashtable所有对外提供的方法都使用了synchronized,也就是同步,而HashMap则是线程非安全的
2、Hashtable不允许空的value,空的value将导致空指针异常,而HashMap则无所谓,没有这方面的限制
3、上面两个缺点是最主要的区别,另外一个区别无关紧要,我只是提一下,就是两个的rehash算法不同,Hashtable的是:
private int hash(Object k) { // hashSeed will be zero if alternative hashing is disabled. return hashSeed ^ k.hashCode();}
这个hashSeed是使用sun.misc.Hashing类的randomHashSeed方法产生的。HashMap的rehash算法上面看过了,也就是:
static int hash(int h) { // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4);}