°°°°PriorityQueue «“ª÷÷ ≤√¥—˘µƒ»›∆˜ƒÿ£øø¥π˝«∞√ʵƒº∏∏ˆjdk»›∆˜∑÷Œˆµƒª∞£¨ø¥µΩQueue’‚∏ˆµ•¥ ƒ„“ª∂®ª·£¨≈∂~’‚ «“ª÷÷∂”¡–°£ «µƒ£¨PriorityQueue «“ª÷÷∂”¡–£¨µ´ «À¸”÷ «“ª÷÷ ≤√¥—˘µƒ∂”¡–ƒÿ£øÀ¸æfl”–◊≈ ≤√¥—˘µƒÃÿµ„ƒÿ£øÀ¸µƒµ◊≤„ µœ÷∑Ω Ω”÷ «‘ı√¥—˘µƒƒÿ£øŒ“√«“ª∆¿¥ø¥“ªœ¬°£
PriorityQueue∆‰ µ «“ª∏ˆ”≈œ»∂”¡–£¨ ≤√¥ «”≈œ»∂”¡–ƒÿ£ø’‚∫ÕŒ“√««∞√ÊΩ≤µƒœ»Ω¯œ»≥ˆ£®First In First Out £©µƒ∂”¡–µƒ«¯±‘⁄”⁄£¨”≈œ»∂”¡–√ø¥Œ≥ˆ∂”µƒ‘™Àÿ∂º «”≈œ»º∂◊Ó∏flµƒ‘™Àÿ°£ƒ«√¥‘ı√¥»∑∂®ƒƒ“ª∏ˆ‘™Àÿµƒ”≈œ»º∂◊Ó∏flƒÿ£¨jdk÷– π”√∂—’‚√¥“ª÷÷ ˝æ›Ω·ππ£¨Õ®π˝∂— πµ√√ø¥Œ≥ˆ∂”µƒ‘™Àÿ◊‹ «∂”¡–¿Ô√Ê◊Ó–°µƒ£¨∂¯‘™Àÿµƒ¥Û–°±»Ωœ∑Ω∑®ø…“‘”…”√ªß÷∏∂®£¨’‚¿ÔæÕœ‡µ±”⁄÷∏∂®”≈œ»º∂‡∂°£
1.∂˛≤Ê∂—ΩÈ…‹
ƒ«√¥∂—”÷ « ≤√¥“ª÷÷ ˝æ›Ω·ππƒÿ°¢À¸”– ≤√¥—˘µƒÃÿµ„ƒÿ£ø£®“‘œ¬º˚”⁄∞Ÿ∂»∞Ÿø∆£©
(1)∂—÷–ƒ≥∏ˆΩ⁄µ„µƒ÷µ◊‹ «≤ª¥Û”⁄ªÚ≤ª–°”⁄∆‰∏∏Ω⁄µ„µƒ÷µ£ª
(2)∂—◊‹ «“ªø√ÕÍ»´ ˜°£
(2)∂—◊‹ «“ªø√ÕÍ»´ ˜°£
≥£º˚µƒ∂—”–∂˛≤Ê∂—°¢Ï≥≤®ƒ«∆ı∂—µ»°£∂¯PriorityQueue π”√µƒ±„ «∂˛≤Ê∂—£¨’‚¿ÔŒ“√«÷˜“™¿¥∑÷Œˆ∫Õ—ßœ∞∂˛≤Ê∂—°£
∂˛≤Ê∂— «“ª÷÷Ãÿ ‚µƒ∂—£¨∂˛≤Ê∂— «ÕÍ»´∂˛≤Ê ˜ªÚ’fl «Ω¸À∆ÕÍ»´∂˛≤Ê ˜°£∂˛≤Ê∂—”–¡Ω÷÷£∫◊Ó¥Û∂—∫Õ◊Ó–°∂—°£◊Ó¥Û∂—£∫∏∏Ω·µ„µƒº¸÷µ◊‹ «¥Û”⁄ªÚµ»”⁄»Œ∫Œ“ª∏ˆ◊”Ω⁄µ„µƒº¸÷µ£ª◊Ó–°∂—£∫∏∏Ω·µ„µƒº¸÷µ◊‹ «–°”⁄ªÚµ»”⁄»Œ∫Œ“ª∏ˆ◊”Ω⁄µ„µƒº¸÷µ°£
ÀµµΩ∂˛≤Ê ˜Œ“√«æÕ±»Ωœ Ïœ§¡À£¨“ÚŒ™Œ“√««∞√Ê∑÷Œˆ∫Õ—ßœ∞π˝¡À∂˛≤Ê≤È’“ ˜∫Õ∫Ï∫⁄ ˜£®TreeMap£©°£πfl¿˝£¨Œ“√«“‘◊Ó–°∂—Œ™¿˝£¨”√ÕºΩ‚¿¥√Ë ˆœ¬ ≤√¥ «∂˛≤Ê∂—°£
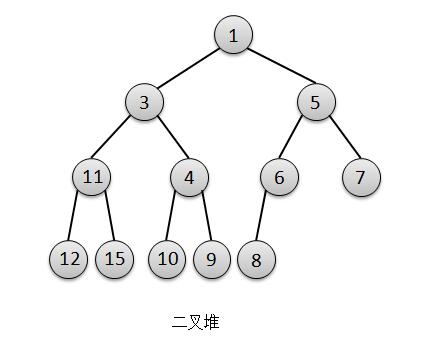
°°°°…œÕºæÕ «“ªø≈ÕÍ»´∂˛≤Ê ˜£®∂˛≤Ê∂—£©£¨Œ“√«ø…“‘ø¥≥ˆ ≤√¥Ãÿµ„¬£¨ƒ«æÕ «‘⁄µ⁄n≤„…Ó∂»±ªÃÓ¬˙÷Æ«∞£¨≤ªª·ø™ ºÃÓµ⁄n+1≤„…Ó∂»£¨∂¯«“‘™Àÿ≤»Π«¥”◊ÛÕ˘”“ÃÓ¬˙°£
°°°°ª˘”⁄’‚∏ˆÃÿµ„£¨∂˛≤Ê∂—”÷ø…“‘”√ ˝◊È¿¥±Ì æ∂¯≤ª «”√¡¥±Ì£¨Œ“√«¿¥ø¥“ªœ¬£∫
°°°°
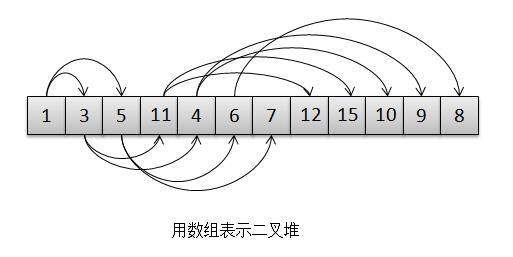
°°°°Õ®π˝"”√ ˝◊È±Ì æ∂˛≤Ê∂—"’‚’≈Õº£¨Œ“√«ø…“‘ø¥≥ˆ ≤√¥πʬ…¬£øƒ«æÕ «£¨ª˘”⁄ ˝◊È µœ÷µƒ∂˛≤Ê∂—£¨∂‘”⁄ ˝◊È÷–»Œ“‚Œª÷√µƒn…œ‘™Àÿ£¨∆‰◊Û∫¢◊”‘⁄[2n+1]Œª÷√…œ£¨”“∫¢◊”[2(n+1)]Œª÷√£¨À¸µƒ∏∏«◊‘Ú‘⁄[(n-1)/2]…œ£¨∂¯∏˘µƒŒª÷√‘Ú «[0]°£
∫√¡À°¢‘⁄¡ÀΩ‚¡À∂˛≤Ê∂—µƒª˘±æ∏≈ƒÓ∫Û£¨Œ“√«¿¥ø¥œ¬jdk÷–PriorityQueue «‘ı√¥ µœ÷µƒ°£
2.PriorityQueueµƒµ◊≤„ µœ÷
œ»¿¥ø¥œ¬PriorityQueueµƒ∂®“£∫
public class PriorityQueue<E> extends AbstractQueue<E> implements java.io.Serializable {
°°°°Œ“√«ø¥µΩPriorityQueueºÃ≥–¡ÀAbstractQueue≥Ȝۿ‡£¨≤¢ µœ÷¡ÀSerializableΩ”ø⁄£¨AbstractQueue≥Ȝۿ‡ µœ÷¡ÀQueueΩ”ø⁄£¨∂‘∆‰÷–∑Ω∑®Ω¯––¡À“ª–©Õ®”√µƒ∑‚◊∞£¨æflÃÂæÕ≤ª∂‡ø¥¡À°£
œ¬√Ê‘Ÿø¥œ¬PriorityQueueµƒµ◊≤„¥Ê¥¢œ‡πÿ∂®“£∫
1 // ƒ¨»œ≥ı ºªØ¥Û–° 2 privatestaticfinalintDEFAULT_INITIAL_CAPACITY = 11; 3 4 // ”√ ˝◊È µœ÷µƒ∂˛≤Ê∂—£¨œ¬√ʵƒ”¢Œƒ◊¢ Õ»∑»œ¡ÀŒ“√««∞√ʵƒÀµ∑®°£ 5 /** 6 * Priority queue represented as a balanced binary heap: the two 7 * children of queue[n] are queue[2*n+1] and queue[2*(n+1)]. The 8 * priority queue is ordered by comparator, or by the elements' 9 * natural ordering, if comparator is null: For each node n in the10 * heap and each descendant d of n, n <= d. The element with the11 * lowest value is in queue[0], assuming the queue is nonempty.12 */13 private transient Object[] queue ;14 15 // ∂”¡–µƒ‘™Àÿ ˝¡ø16 private int size = 0;17 18 // ±»Ωœ∆˜19 private final Comparator<? super E> comparator;20 21 // –fi∏ƒ∞ʱæ22 private transient int modCount = 0;
°°°°Œ“√«ø¥µΩjdk÷–µƒPriorityQueueµƒ“≤ «ª˘”⁄ ˝◊È¿¥ µœ÷“ª∏ˆ∂˛≤Ê∂—£¨≤¢«“◊¢ Õ÷–Ω‚ Õ¡ÀŒ“√««∞√ʵƒÀµ∑®°£∂¯Comparator’‚∏ˆ±»Ωœ∆˜Œ“√«“—æ≠∫‹ Ïœ§¡À£¨Œ“√«ÀµPriorityQueue «“ª∏ˆ”–œfi∂”¡–£¨À˚ø…“‘”…”√ªß÷∏∂®”≈œ»º∂£¨æÕ «øø’‚∏ˆ±»Ωœ∆˜‡∂°£
3.PriorityQueueµƒππ‘Ï∑Ω∑®
°°°°
1 /** 2 * ƒ¨»œππ‘Ï∑Ω∑®£¨ π”√ƒ¨»œµƒ≥ı º¥Û–°¿¥ππ‘Ï“ª∏ˆ”≈œ»∂”¡–£¨±»Ωœ∆˜comparatorŒ™ø’£¨’‚¿Ô“™«Û»Î∂”µƒ‘™Àÿ±ÿ–Î µœ÷ComparatorΩ”ø⁄ 3 */ 4 public PriorityQueue() { 5 this(DEFAULT_INITIAL_CAPACITY, null); 6 } 7 8 /** 9 * π”√÷∏∂®µƒ≥ı º¥Û–°¿¥ππ‘Ï“ª∏ˆ”≈œ»∂”¡–£¨±»Ωœ∆˜comparatorŒ™ø’£¨’‚¿Ô“™«Û»Î∂”µƒ‘™Àÿ±ÿ–Î µœ÷ComparatorΩ”ø⁄10 */11 public PriorityQueue( int initialCapacity) {12 this(initialCapacity, null);13 }14 15 /**16 * π”√÷∏∂®µƒ≥ı º¥Û–°∫Õ±»Ωœ∆˜¿¥ππ‘Ï“ª∏ˆ”≈œ»∂”¡–17 */18 public PriorityQueue( int initialCapacity,19 Comparator<? super E> comparator) {20 // Note: This restriction of at least one is not actually needed,21 // but continues for 1.5 compatibility22 // ≥ı º¥Û–°≤ª‘ –Ì–°”⁄123 if (initialCapacity < 1)24 throw new IllegalArgumentException();25 // π”√÷∏∂®≥ı º¥Û–°¥¥Ω® ˝◊È26 this.queue = new Object[initialCapacity];27 // ≥ı ºªØ±»Ωœ∆˜28 this.comparator = comparator;29 }30 31 /**32 * ππ‘Ï“ª∏ˆ÷∏∂®CollectionºØ∫œ≤Œ ˝µƒ”≈œ»∂”¡–33 */34 public PriorityQueue(Collection<? extends E> c) {35 // ¥”ºØ∫œc÷–≥ı ºªØ ˝æ›µΩ∂”¡–36 initFromCollection(c);37 // »Áπ˚ºØ∫œc «∞¸∫¨±»Ωœ∆˜Comparatorµƒ(SortedSet/PriorityQueue)£¨‘Ú π”√ºØ∫œcµƒ±»Ωœ∆˜¿¥≥ı ºªØ∂”¡–µƒComparator38 if (c instanceof SortedSet)39 comparator = (Comparator<? super E>)40 ((SortedSet<? extends E>)c).comparator();41 else if (c instanceof PriorityQueue)42 comparator = (Comparator<? super E>)43 ((PriorityQueue<? extends E>)c).comparator();44 // »Áπ˚ºØ∫œc√ª”–∞¸∫¨±»Ωœ∆˜£¨‘Úƒ¨»œ±»Ωœ∆˜ComparatorŒ™ø’45 else {46 comparator = null;47 // µ˜”√heapify∑Ω∑®÷ÿ–¬Ω´ ˝æ›µ˜’˚Œ™“ª∏ˆ∂˛≤Ê∂—48 heapify();49 }50 }51 52 /**53 * ππ‘Ï“ª∏ˆ÷∏∂®PriorityQueue≤Œ ˝µƒ”≈œ»∂”¡–54 */55 public PriorityQueue(PriorityQueue<? extends E> c) {56 comparator = (Comparator<? super E>)c.comparator();57 initFromCollection(c);58 }59 60 /**61 * ππ‘Ï“ª∏ˆ÷∏∂®SortedSet≤Œ ˝µƒ”≈œ»∂”¡–62 */63 public PriorityQueue(SortedSet<? extends E> c) {64 comparator = (Comparator<? super E>)c.comparator();65 initFromCollection(c);66 }67 68 /**69 * ¥”ºØ∫œ÷–≥ı ºªØ ˝æ›µΩ∂”¡–70 */71 private void initFromCollection(Collection<? extends E> c) {72 // Ω´ºØ∫œCollection◊™ªªŒ™ ˝◊Èa73 Object[] a = c.toArray();74 // If c.toArray incorrectly doesn't return Object[], copy it.75 // »Áπ˚◊™ªª∫Ûµƒ ˝◊Èa¿‡–Õ≤ª «Object ˝◊È£¨‘Ú◊™ªªŒ™Object ˝◊È76 if (a.getClass() != Object[].class)77 a = Arrays. copyOf(a, a.length, Object[]. class);78 // Ω´ ˝◊Èa∏≥÷µ∏¯∂”¡–µƒµ◊≤„ ˝◊Èqueue79 queue = a;80 // Ω´∂”¡–µƒ‘™Àÿ∏ˆ ˝…Ë÷√Œ™ ˝◊Èaµƒ≥§∂»81 size = a.length ;82 }
°°°°
°°°°ππ‘Ï∑Ω∑®ªπ «±»Ωœ»›“◊¿ÌΩ‚µƒ£¨µ⁄Àƒ∏ˆππ‘Ï∑Ω∑®÷–£¨»Áπ˚ÃӻØ∫œc√ª”–∞¸∫¨±»Ωœ∆˜Comparator£¨‘Ú‘⁄µ˜”√initFromCollection≥ı ºªØ ˝æ›∫Û£¨‘⁄µ˜”√heapify∑Ω∑®∂‘ ˝◊ÈΩ¯––µ˜’˚£¨ πµ√À¸∑˚∫œ∂˛≤Ê∂—µƒπÊ∑∂ªÚ’flÃÿµ„£¨æflÃÂheapify «‘ı√¥ππ‘Ï∂˛≤Ê∂—µƒ£¨Œ“√«∫Û√Ê‘Ÿø¥°£
ƒ«√¥‘ı√¥—˘µ˜’˚≤≈ƒ‹ 𓪖©‘”¬“Œfi’¬µƒ ˝æ›±‰≥…“ª∏ˆ∑˚∫œ∂˛≤Ê∂—µƒπÊ∑∂µƒ ˝æ›ƒÿ£ø
4.∂˛≤Ê∂—µƒÃ̺”‘≠¿Ìº∞PriorityQueueµƒ»Î∂” µœ÷
Œ“√«ªÿ“‰“ªœ¬£¨Œ“√«‘⁄Àµ∫Ï∫⁄ ˜TreeMapµƒ ±∫ÚÀµ£¨∫Ï∫⁄ ˜Œ™¡ÀŒ¨ª§∆‰∫Ï∫⁄∆Ω∫‚£¨÷˜“™”–»˝∏ˆ∂Ø◊˜£∫◊Û–˝°¢”“–˝°¢◊≈…´°£ƒ«√¥∂˛≤Ê∂—Œ™¡ÀŒ¨ª§À˚µƒÃÿµ„”÷–Ë“™Ω¯–– ≤√¥—˘µƒ≤Ÿ◊˜ƒÿ°£
Œ“√«‘Ÿ¿¥ø¥œ¬∂˛≤Ê∂—£®◊Ó–°∂—Œ™¿˝£©µƒÃÿµ„£∫
(1)∏∏Ω·µ„µƒº¸÷µ◊‹ «–°”⁄ªÚµ»”⁄»Œ∫Œ“ª∏ˆ◊”Ω⁄µ„µƒº¸÷µ°£
(2)ª˘”⁄ ˝◊È µœ÷µƒ∂˛≤Ê∂—£¨∂‘”⁄ ˝◊È÷–»Œ“‚Œª÷√µƒn…œ‘™Àÿ£¨∆‰◊Û∫¢◊”‘⁄[2n+1]Œª÷√…œ£¨”“∫¢◊”[2(n+1)]Œª÷√£¨À¸µƒ∏∏«◊‘Ú‘⁄[n-1/2]…œ£¨∂¯∏˘µƒŒª÷√‘Ú «[0]°£
Œ™¡ÀŒ¨ª§’‚∏ˆÃÿµ„£¨∂˛≤Ê∂—‘⁄Ã̺”‘™Àÿµƒ ±∫Ú£¨–Ë“™“ª∏ˆ"…œ“∆"µƒ∂Ø◊˜£¨ ≤√¥ «"…œ“∆"ƒÿ£¨Œ“√«ºÃ–¯”√Õº¿¥Àµ√˜°£
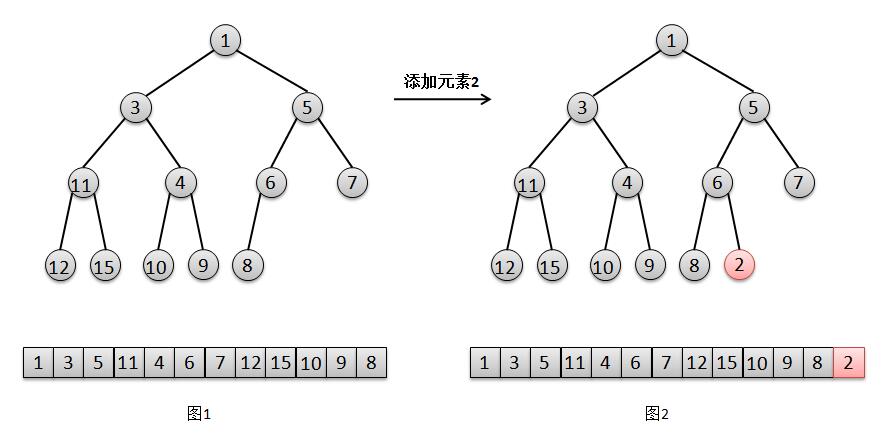
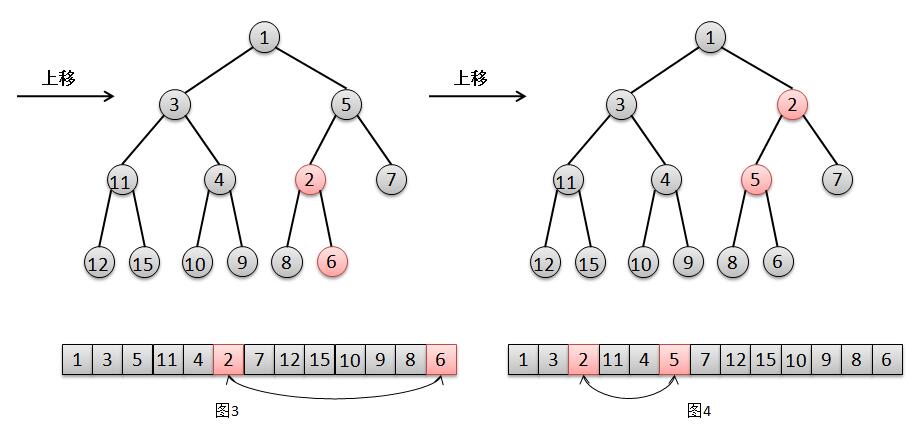
°°°°Ω·∫œ…œ√ʵƒÕºΩ‚£¨Œ“√«¿¥Àµ√˜“ªœ¬∂˛≤Ê∂—µƒÃ̺”‘™Àÿπ˝≥ã∫
1. Ω´‘™Àÿ2Ã̺”‘⁄◊Ó∫Û“ª∏ˆŒª÷√£®∂”Œ≤£©£®Õº2£©°£
2. ”…”⁄2±»∆‰∏∏«◊6“™–°£¨À˘“‘Ω´‘™Àÿ2…œ“∆£¨Ωªªª2∫Õ6µƒŒª÷√£®Õº3£©£ª
3. »ª∫Û”…”⁄2±»5–°£¨ºÃ–¯Ω´2…œ“∆£¨Ωªªª2∫Õ5µƒŒª÷√£®Õº4£©£¨¥À ±2¥Û”⁄∆‰∏∏«◊£®∏˘Ω⁄µ„£©1£¨Ω· ¯°£
◊¢£∫’‚¿ÔµƒΩ⁄µ„—’…´ «Œ™¡ÀÕπœ‘£¨”¶±„”⁄¿ÌΩ‚£¨∏˙∫Ï∫⁄ ˜µƒ÷–µƒ—’…´Œfiπÿ£¨≤ª“™≈™ªÏ°£°£°£
ø¥ÕÍ¡À’‚4’≈Õº£¨ «≤ª «æıµ√∂˛≤Ê∂—µƒÃ̺”ªπ «Õ¶»›“◊µƒ£¨ƒ«√¥œ¬√ÊŒ“√«æflÃÂø¥œ¬PriorityQueueµƒ¥˙¬Î «‘ı√¥ µœ÷»Î∂”≤Ÿ◊˜µƒ∞…°£
1 /** 2 * Ã̺”“ª∏ˆ‘™Àÿ 3 */ 4 public boolean add(E e) { 5 return offer(e); 6 } 7 8 /** 9 * »Î∂”10 */11 public boolean offer(E e) {12 // »Áπ˚‘™ÀÿeŒ™ø’£¨‘Ú≈≈≥˝ø’÷∏’ΓÏ≥£13 if (e == null)14 throw new NullPointerException();15 // –fi∏ƒ∞ʱæ+116 modCount++;17 // º«¬ºµ±«∞∂”¡–÷–‘™Àÿµƒ∏ˆ ˝18 int i = size ;19 // »Áπ˚µ±«∞‘™Àÿ∏ˆ ˝¥Û”⁄µ»”⁄∂”¡–µ◊≤„ ˝◊ȵƒ≥§∂»£¨‘ÚΩ¯––¿©»›20 if (i >= queue .length)21 grow(i + 1);22 // ‘™Àÿ∏ˆ ˝+123 size = i + 1;24 // »Áπ˚∂”¡–÷–√ª”–‘™Àÿ£¨‘ÚΩ´‘™Àÿe÷±Ω”Ã̺”÷¡∏˘£® ˝◊È–°±Í0µƒŒª÷√£©25 if (i == 0)26 queue[0] = e;27 // ∑Ò‘Úµ˜”√siftUp∑Ω∑®£¨Ω´‘™ÀÿÃ̺”µΩŒ≤≤ø£¨Ω¯––…œ“∆≈–∂œ28 else29 siftUp(i, e);30 return true;31 }
°°°°’‚¿Ôµƒadd∑Ω∑®“¿»ª√ª”–∞¥’’QueueµƒπÊ∑∂£¨‘⁄∂”¡–¬˙µƒ ±∫Ú≈◊≥ˆ“Ï≥££¨“ÚŒ™PriorityQueue∫Õ«∞√ÊΩ≤µƒArrayDeque“ª—˘£¨ª·Ω¯––¿©»›£¨À˘“‘÷ª”–µ±∂”¡–»›¡ø≥¨≥ˆint∑∂Œß≤≈ª·≈◊≥ˆ“Ï≥£°£
º»»ªPriorityQueueª·Ω¯––∂”¡–¿©»›£¨ƒ«√¥æÕ¿¥ø¥œ¬¿©»›µƒæfl൜÷∞…£®∂‘”⁄ ˝◊È µœ÷µƒ»›∆˜£¨Œ“√«º˚π˝Ã´∂‡µƒ¿©»›¡À°£°£°££©°£
1 /** 2 * ˝◊È¿©»› 3 */ 4 private void grow(int minCapacity) { 5 // »Áπ˚◊Ó–°–Ë“™µƒ»›¡ø¥Û–°minCapacity–°”⁄0£¨‘ÚÀµ√˜¥À ±“—æ≠≥¨≥ˆintµƒ∑∂Œß£¨‘Ú≈◊≥ˆOutOfMemoryError“Ï≥£ 6 if (minCapacity < 0) // overflow 7 throw new OutOfMemoryError(); 8 // º«¬ºµ±«∞∂”¡–µƒ≥§∂» 9 int oldCapacity = queue .length;10 // Double size if small; else grow by 50%11 // »Áπ˚µ±«∞∂”¡–≥§∂»–°”⁄64‘Ú¿©»›2±∂£¨∑Ò‘Ú¿©»›1.5±∂12 int newCapacity = ((oldCapacity < 64)?13 ((oldCapacity + 1) * 2):14 ((oldCapacity / 2) * 3));15 // »Áπ˚¿©»›∫ÛnewCapacity≥¨≥ˆintµƒ∑∂Œß£¨‘ÚΩ´newCapacity∏≥÷µŒ™Integer.Max_VALUE16 if (newCapacity < 0) // overflow17 newCapacity = Integer. MAX_VALUE;18 // »Áπ˚¿©»›∫Û£¨newCapacity–°”⁄◊Ó–°–Ë“™µƒ»›¡ø¥Û–°minCapacity£¨‘Ú∞¥’“minCapacity≥§∂»Ω¯––¿©»›19 if (newCapacity < minCapacity)20 newCapacity = minCapacity;21 // ˝◊Ècopy£¨Ω¯––¿©»›22 queue = Arrays.copyOf( queue, newCapacity);23 }
°°°°–Ë“™¿ÌΩ‚µƒ «£¨’‚¿ÔŒ™ ≤√¥µ±minCapacity–°”⁄0µƒ ±∫Ú£¨æÕ¥˙±Ì≥¨≥ˆint∑∂Œßƒÿ£¨Œ“√«¿¥ø¥œ¬°£
int‘⁄java÷–’º4∏ˆ◊÷Ω⁄£¨“ª∏ˆ◊÷Ω⁄8Œª£¨¥”0ø™ ºº«£¨ƒ«√¥4∏ˆ◊÷Ω⁄µƒ◊Ó∏flŒªæÕ «31£¨∂¯java÷–µƒª˘±æ ˝æ›¿‡–Õ∂º «”–∑˚∫≈µƒ£¨À˘“‘◊Ó∏flŒª¥˙±Ìµƒ «∑˚∫≈Œª°£
intµƒ◊Ó¥Û÷µInteger.MAX_VALUE=0111 1111 1111 1111 1111 1111 1111 1111£¨Integer.MAX_VALUE+1=1000 0000 0000 0000 0000 0000 0000 0000£¨¥À ±◊Ó∏flŒª «∑˚∫≈ŒªŒ™1£¨À˘“‘’‚∏ˆ ˝ «∏∫ ˝°£∏∫ ˝µƒ≤π¬Î «‘⁄∆‰‘≠¬Îµƒª˘¥°…œ£¨∑˚∫≈Œª≤ª±‰£¨∆‰”‡∏˜Œª»°∑¥£¨◊Ó∫Û+1£®º¥‘⁄∑¥¬Îµƒª˘¥°…œ+1£©°£
∫√¡À£¨ø¥ÕÍ…œ√Ê’‚∏ˆ–°≤«˙£¨Œ“√«¿¥ø¥œ¬∂˛≤Ê∂—µƒ“ª∏ˆ÷ÿ“™≤Ÿ◊˜"…œ“∆" «‘ı√¥ µœ÷µƒ∞…°£
1 /** 2 * …œ“∆£¨x±Ì æ–¬≤»Α™Àÿ£¨k±Ì æ–¬≤»Α™Àÿ‘⁄ ˝◊ȵƒŒª÷√ 3 */ 4 private void siftUp(int k, E x) { 5 // »Áπ˚±»Ωœ∆˜comparator≤ªŒ™ø’£¨‘Úµ˜”√siftUpUsingComparator∑Ω∑®Ω¯––…œ“∆≤Ÿ◊˜ 6 if (comparator != null) 7 siftUpUsingComparator(k, x); 8 // »Áπ˚±»Ωœ∆˜comparatorŒ™ø’£¨‘Úµ˜”√siftUpComparable∑Ω∑®Ω¯––…œ“∆≤Ÿ◊˜ 9 else10 siftUpComparable(k, x);11 }12 13 private void siftUpComparable(int k, E x) {14 // ±»Ωœ∆˜comparatorŒ™ø’£¨–Ë“™≤»εƒ‘™Àÿ µœ÷ComparableΩ”ø⁄£¨”√”⁄±»Ωœ¥Û–°15 Comparable<? super E> key = (Comparable<? super E>) x;16 // k>0±Ì æ≈–∂œk≤ª «∏˘µƒ«Èøˆœ¬£¨“≤æÕ «‘™Àÿx”–∏∏Ω⁄µ„17 while (k > 0) {18 // º∆À„‘™Àÿxµƒ∏∏Ω⁄µ„Œª÷√[(n-1)/2]19 int parent = (k - 1) >>> 1;20 // »°≥ˆxµƒ∏∏«◊e21 Object e = queue[parent];22 // »Áπ˚–¬‘ˆµƒ‘™Àÿk±»∆‰∏∏«◊e¥Û£¨‘Ú≤ª–Ë“™"…œ“∆"£¨Ã¯≥ˆ—≠ª∑Ω· ¯23 if (key.compareTo((E) e) >= 0)24 break;25 // x±»∏∏«◊–°£¨‘Ú–Ë“™Ω¯––"…œ“∆"26 // Ωªªª‘™Àÿx∫Õ∏∏«◊eµƒŒª÷√27 queue[k] = e;28 // Ω´–¬≤»Α™ÀÿµƒŒª÷√k÷∏œÚ∏∏«◊µƒŒª÷√£¨Ω¯––œ¬“ª≤„—≠ª∑29 k = parent;30 }31 // ’“µΩ–¬‘ˆ‘™Àÿxµƒ∫œ Œª÷√k÷Æ∫ÛΩ¯––∏≥÷µ32 queue[k] = key;33 }34 35 // ’‚∏ˆ∑Ω∑®∫Õ…œ√ʵƒ≤Ÿ◊˜“ª—˘£¨≤ª∂‡Àµ¡À36 private void siftUpUsingComparator(int k, E x) {37 while (k > 0) {38 int parent = (k - 1) >>> 1;39 Object e = queue[parent];40 if (comparator .compare(x, (E) e) >= 0)41 break;42 queue[k] = e;43 k = parent;44 }45 queue[k] = x;46 }
°°°°Ω·∫œ…œ√ʵƒÕºΩ‚£¨∂˛≤Ê∂—"…œ“∆"≤Ÿ◊˜µƒ¥˙¬Îªπ «∫‹»›“◊¿ÌΩ‚µƒ£¨÷˜“™æÕ «≤ª∂œµƒΩ´–¬‘ˆ‘™Àÿ∫Õ∆‰∏∏«◊Ω¯––¥Û–°±»Ωœ£¨±»∏∏«◊–°‘Ú…œ“∆£¨◊Ó÷’’“µΩ“ª∏ˆ∫œ µƒŒª÷√°£
5.∂˛≤Ê∂—µƒ…æ≥˝∏˘‘≠¿Ìº∞PriorityQueueµƒ≥ˆ∂” µœ÷
∂‘”⁄∂˛≤Ê∂—µƒ≥ˆ∂”≤Ÿ◊˜£¨≥ˆ∂””¿‘∂ «“™…æ≥˝∏˘‘™Àÿ£¨“≤æÕ «◊Ó–°µƒ‘™Àÿ£¨“™…æ≥˝∏˘‘™Àÿ£¨æÕ“™’““ª∏ˆÃÊ¥˙’fl“∆∂صΩ∏˘Œª÷√£¨œ‡∂‘”⁄±ª…æ≥˝µƒ‘™Àÿ¿¥ÀµæÕ «"œ¬“∆"°£

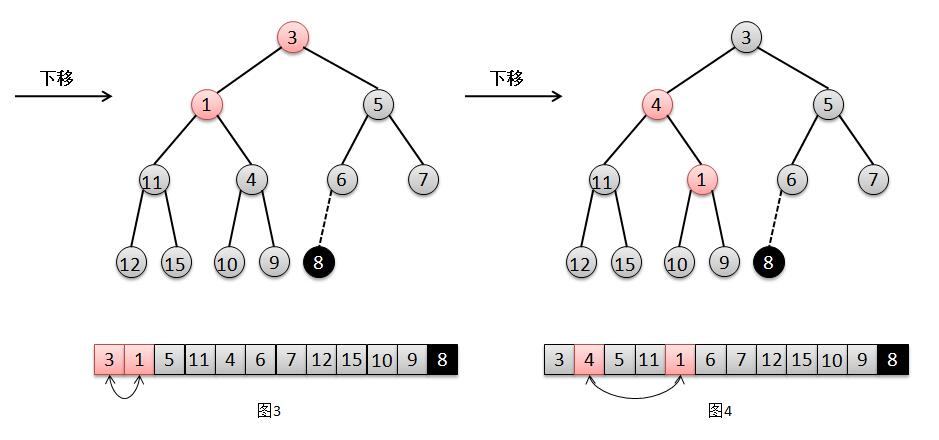
°°°°Ω·∫œ…œ√ʵƒÕºΩ‚£¨Œ“√«¿¥Àµ√˜“ªœ¬∂˛≤Ê∂—µƒ≥ˆ∂”π˝≥Ã:
1. Ω´’“≥ˆ∂”Œ≤µƒ‘™Àÿ8£¨≤¢Ω´À¸‘⁄∂”Œ≤Œª÷√…œ…æ≥˝£®Õº2£©;
2. ¥À ±∂”Œ≤‘™Àÿ8±»∏˘‘™Àÿ1µƒ◊Ó–°∫¢◊”3“™¥Û£¨À˘“‘Ω´‘™Àÿ1œ¬“∆£¨Ωªªª1∫Õ3µƒŒª÷√£®Õº3£©£ª
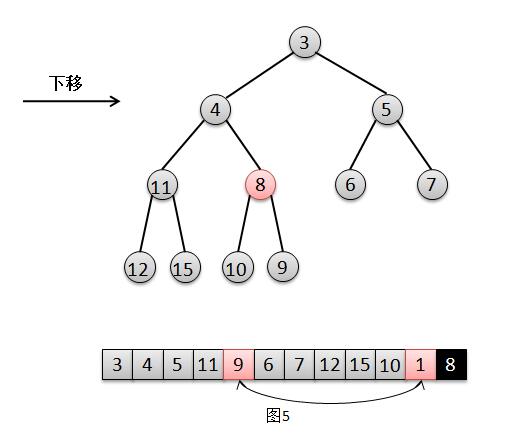
3. »ª∫Û¥À ±∂”Œ≤‘™Àÿ8±»‘™Àÿ1µƒ◊Ó–°∫¢◊”4“™¥Û£¨ºÃ–¯Ω´1œ¬“∆£¨Ωªªª1∫Õ4µƒŒª÷√£®Õº4£©£ª
4. »ª∫Û¥À ±∏˘‘™Àÿ8±»‘™Àÿ1µƒ◊Ó–°∫¢◊”9“™–°£¨≤ª–Ë“™œ¬“∆£¨÷±Ω”Ω´∏˘‘™Àÿ8∏≥÷µ∏¯¥À ±‘™Àÿ1µƒŒª÷√£¨1±ª∏≤∏«‘Úœ‡µ±”⁄…æ≥˝£®Õº5£©£¨Ω· ¯°£
ø¥ÕÍ¡À’‚6’≈Õº£¨œ¬√ÊŒ“√«æflÃÂø¥œ¬PriorityQueueµƒ¥˙¬Î «‘ı√¥ µœ÷≥ˆ∂”≤Ÿ◊˜µƒ∞…°£
1 /** 2 * …æ≥˝≤¢∑µªÿ∂”Õ∑µƒ‘™Àÿ£¨»Áπ˚∂”¡–Œ™ø’‘Ú≈◊≥ˆNoSuchElementException“Ï≥££®∏√∑Ω∑®‘⁄AbstractQueue÷–£© 3 */ 4 public E remove() { 5 E x = poll(); 6 if (x != null) 7 return x; 8 else 9 throw new NoSuchElementException();10 }11 12 /**13 * …æ≥˝≤¢∑µªÿ∂”Õ∑µƒ‘™Àÿ£¨»Áπ˚∂”¡–Œ™ø’‘Ú∑µªÿnull14 */15 public E poll() {16 // ∂”¡–Œ™ø’£¨∑µªÿnull17 if (size == 0)18 return null;19 // ∂”¡–‘™Àÿ∏ˆ ˝-120 int s = --size ;21 // –fi∏ƒ∞ʱæ+122 modCount++;23 // ∂”Õ∑µƒ‘™Àÿ24 E result = (E) queue[0];25 // ∂”Œ≤µƒ‘™Àÿ26 E x = (E) queue[s];27 // œ»Ω´∂”Œ≤∏≥÷µŒ™null28 queue[s] = null;29 // »Áπ˚∂”¡–÷–≤ª÷π∂”Œ≤“ª∏ˆ‘™Àÿ£¨‘Úµ˜”√siftDown∑Ω∑®Ω¯––"œ¬“∆"≤Ÿ◊˜30 if (s != 0)31 siftDown(0, x);32 return result;33 }34 35 /**36 * …œ“∆£¨x±Ì æ∂”Œ≤µƒ‘™Àÿ£¨k±Ì 汪…æ≥˝‘™Àÿ‘⁄ ˝◊ȵƒŒª÷√37 */38 private void siftDown(int k, E x) {39 // »Áπ˚±»Ωœ∆˜comparator≤ªŒ™ø’£¨‘Úµ˜”√siftDownUsingComparator∑Ω∑®Ω¯––œ¬“∆≤Ÿ◊˜40 if (comparator != null)41 siftDownUsingComparator(k, x);42 // ±»Ωœ∆˜comparatorŒ™ø’£¨‘Úµ˜”√siftDownComparable∑Ω∑®Ω¯––œ¬“∆≤Ÿ◊˜43 else44 siftDownComparable(k, x);45 }46 47 private void siftDownComparable(int k, E x) {48 // ±»Ωœ∆˜comparatorŒ™ø’£¨–Ë“™≤»εƒ‘™Àÿ µœ÷ComparableΩ”ø⁄£¨”√”⁄±»Ωœ¥Û–°49 Comparable<? super E> key = (Comparable<? super E>)x;50 // Õ®π˝size/2’“µΩ“ª∏ˆ√ª”–“∂◊”Ω⁄µ„µƒ‘™Àÿ51 int half = size >>> 1; // loop while a non-leaf52 // ±»ΩœŒª÷√k∫Õhalf£¨»Áπ˚k–°”⁄half£¨‘ÚkŒª÷√µƒ‘™ÀÿæÕ≤ª «“∂◊”Ω⁄µ„53 while (k < half) {54 // ’“µΩ∏˘‘™Àÿµƒ◊Û∫¢◊”µƒŒª÷√[2n+1]55 int child = (k << 1) + 1; // assume left child is least56 // ◊Û∫¢◊”µƒ‘™Àÿ57 Object c = queue[child];58 // ’“µΩ∏˘‘™Àÿµƒ”“∫¢◊”µƒŒª÷√[2(n+1)]59 int right = child + 1;60 // »Áπ˚◊Û∫¢◊”¥Û”⁄”“∫¢◊”£¨‘ÚΩ´c∏¥÷∆Œ™”“∫¢◊”µƒ÷µ£¨’‚¿Ô“≤æÕ «’“≥ˆ◊Û”“∫¢◊”ƒƒ∏ˆ◊Ó–°61 if (right < size &&62 ((Comparable<? super E>) c).compareTo((E) queue [right]) > 0)63 c = queue[child = right];64 // »Áπ˚∂”Œ≤‘™Àÿ±»∏˘‘™Àÿ∫¢◊”∂º“™–°£¨‘Ú≤ª–Ë"œ¬“∆"£¨Ω· ¯65 if (key.compareTo((E) c) <= 0)66 break; 67 // ∂”Œ≤‘™Àÿ±»∏˘‘™Àÿ∫¢◊”∂º¥Û£¨‘Ú–Ë“™"œ¬“∆"68 // Ωªªª∏˙‘™Àÿ∫Õ∫¢◊”cµƒŒª÷√69 queue[k] = c;70 // Ω´∏˘‘™ÀÿŒª÷√k÷∏œÚ◊Ó–°∫¢◊”µƒŒª÷√£¨Ω¯»Îœ¬≤„—≠ª∑71 k = child;72 }73 // ’“µΩ∂”Œ≤‘™Àÿxµƒ∫œ Œª÷√k÷Æ∫ÛΩ¯––∏≥÷µ74 queue[k] = key;75 }76 77 // ’‚∏ˆ∑Ω∑®∫Õ…œ√ʵƒ≤Ÿ◊˜“ª—˘£¨≤ª∂‡Àµ¡À78 private void siftDownUsingComparator(int k, E x) {79 int half = size >>> 1;80 while (k < half) {81 int child = (k << 1) + 1;82 Object c = queue[child];83 int right = child + 1;84 if (right < size &&85 comparator.compare((E) c, (E) queue [right]) > 0)86 c = queue[child = right];87 if (comparator .compare(x, (E) c) <= 0)88 break;89 queue[k] = c;90 k = child;91 }92 queue[k] = x;93 }
°°°°
°°°°jdk÷–£¨≤ª «÷±Ω”Ω´∏˘‘™Àÿ…æ≥˝£¨»ª∫Û‘ŸΩ´œ¬√ʵƒ‘™Àÿ◊ˆ…œ“∆£¨÷ÿ–¬≤π≥‰∏˘‘™Àÿ£ª∂¯ «’“≥ˆ∂”Œ≤µƒ‘™Àÿ£¨≤¢‘⁄∂”Œ≤µƒŒª÷√…œ…æ≥˝£¨»ª∫ÛÕ®π˝∏˘‘™Àÿµƒœ¬“∆£¨∏¯∂”Œ≤‘™Àÿ’“µΩ“ª∏ˆ∫œ µƒŒª÷√£¨◊Ó÷’∏≤∏«µÙ∏˙‘™Àÿ£¨¥”∂¯¥ÔµΩ…æ≥˝∏˘‘™Àÿµƒƒøµƒ°£’‚—˘◊ˆ‘⁄“ª–©«Èøˆœ¬£¨ª·±»÷±Ω”…æ≥˝‘⁄…œ“∆∏˘‘™Àÿ£¨ªÚ’fl÷±Ω”œ¬“∆∏˘‘™Àÿ‘Ÿµ˜’˚∂”Œ≤‘™ÀÿµƒŒª÷√…Ÿ≤Ÿ◊˜“ª–©≤Ω◊‡£®±»»Á…œ√ÊÕºΩ‚÷–µƒ¿˝◊”£¨≤ª–≈ƒ„ø…“‘ ‘“ªœ¬^_^£©°£
√˜∞◊¡À∂˛≤Ê∂—µƒ»Î∂”∫Õ≥ˆ∂”≤Ÿ◊˜∫Û£¨∆‰À˚µƒ∑Ω∑®æÕ∂º±»ΩœºÚµ•¡À£¨œ¬√ÊŒ“√«‘Ÿ¿¥ø¥“ª∏ˆ∂˛≤Ê∂—÷–±»Ωœ÷ÿ“™µƒπ˝≥ã¨∂˛≤Ê∂—µƒππ‘Ï°£
6.∂—µƒππ‘Ïπ˝≥Ã
Œ“√«‘⁄…œ√Ê÷µΩπ˝µƒ£¨∂—µƒππ‘Ï «Õ®π˝“ª∏ˆheapify∑Ω∑®£¨œ¬√ÊŒ“√«¿¥ø¥œ¬heapify∑Ω∑®µƒ µœ÷°£
1 /**2 * Establishes the heap invariant (described above) in the entire tree,3 * assuming nothing about the order of the elements prior to the call.4 */5 private void heapify() {6 for (int i = (size >>> 1) - 1; i >= 0; i--)7 siftDown(i, (E) queue[i]);8 }
°°°°’‚∏ˆ∑Ω∑®∫‹ºÚµ•£¨æÕ’‚º∏––¥˙¬Î£¨µ´ «¿ÌΩ‚∆¿¥»¥≤ª «ƒ«√¥»›∆˜µƒ£¨Œ“√«¿¥∑÷Œˆœ¬°£
ºŸ…Ë”–“ª∏ˆŒfi–Úµƒ ˝◊È£¨“™«ÛŒ“√«Ω´’‚∏ˆ ˝◊ÈΩ®≥…“ª∏ˆ∂˛≤Ê∂—£¨ƒ„ª·‘ı√¥◊ˆƒÿ£ø◊ÓºÚµ•µƒ∞Ï∑®µ±»ª «Ω´ ˝◊ȵƒ ˝æ›“ª∏ˆ∏ˆ»°≥ˆ¿¥£¨µ˜”√»Î∂”∑Ω∑®°£µ´ «’‚—˘◊ˆ£¨√ø¥Œ»Î∂”∂º”–ø…ƒ‹ª·∞ÈÀÊ◊≈‘™Àÿµƒ“∆∂Ø£¨’‚√¥◊ˆ « Æ∑÷µÕ–ßµƒ°£ƒ«√¥”–√ª”–∏¸º”∏fl–ßµƒ∑Ω∑®ƒÿ£¨Œ“√«¿¥ø¥œ¬°£
Œ™¡À∑Ω±„£¨Œ“√«Ω´…œ√ÊŒ“√«ÕºΩ‚÷–µƒ ˝◊È»•µÙº∏∏ˆ‘™Àÿ£¨÷ª¡Ùœ¬7°¢6°¢5°¢12°¢10°¢3°¢1°¢11°¢15°¢4£®À≥–Ú“—æ≠Àʪ˙¥Ú¬“£©°£ok°¢ƒ«√¥Ω”œ¬¿¥£¨Œ“√«æÕ∞¥’’µ±«∞µƒÀ≥–ÚΩ®¡¢“ª∏ˆ∂˛≤Ê∂—£¨‘› ±≤ª”√π‹À¸ «∑Ò∑˚∫œ±Í◊º°£
int a = [7, 6, 5, 12, 10, 3, 1, 11, 15, 4 ];

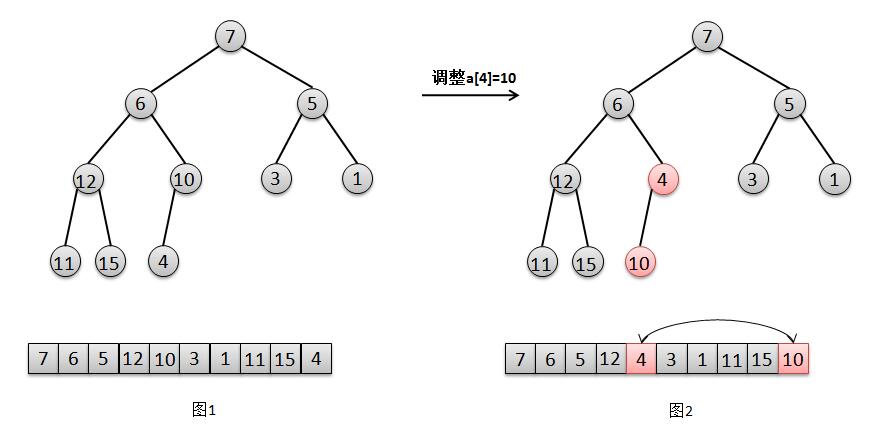
°°°°Œ“√«π€≤Ïœ¬”√ ˝◊ÈaΩ®≥…µƒ∂˛≤Ê∂—£¨∫‹√˜œ‘£¨∂‘”⁄“∂◊”Ω⁄µ„4°¢15°¢11°¢1°¢3¿¥Àµ£¨À¸√«“—æ≠ «“ª∏ˆ∫œ∑®µƒ∂—°£À˘“‘÷ª“™◊Ó∫Û“ª∏ˆΩ⁄µ„µƒ∏∏Ω⁄µ„£¨“≤æÕ «◊Ó∫Û“ª∏ˆ∑«“∂◊”Ω⁄µ„a[4]=10ø™ ºµ˜’˚£¨»ª∫Û“¿¥Œµ˜’˚a[3]=12£¨a[2]=5£¨a[1]=6£¨a[0]=7£¨∑÷±∂‘’‚º∏∏ˆΩ⁄µ„◊ˆ“ª¥Œ"œ¬“∆"≤Ÿ◊˜æÕø…“‘ÕÍ≥…¡À∂—µƒππ‘Ï°£ok£¨Œ“√«ªπ «”√ÕºΩ‚¿¥∑÷Œˆœ¬’‚∏ˆπ˝≥ð£
°°°°Œ“√«≤Œ’’ÕºΩ‚∑÷±¿¥Ω‚ Õœ¬’‚º∏∏ˆ≤Ω◊‡£∫
1. ∂‘”⁄Ω⁄µ„a[4]=10µƒµ˜’˚£®Õº1£©£¨÷ª–Ë“™Ωªªª‘™Àÿ10∫Õ∆‰◊”Ω⁄µ„4µƒŒª÷√£®Õº2£©°£
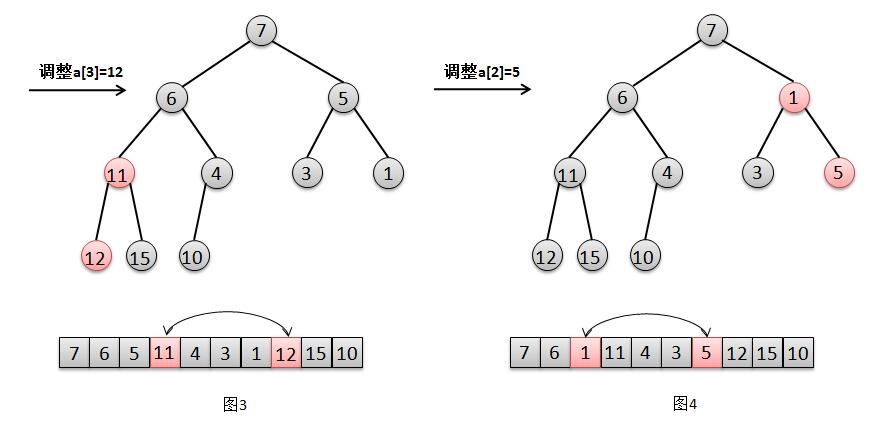
2. ∂‘”⁄Ω⁄µ„a[3]=12µƒµ˜’˚£¨÷ª–Ë“™Ωªªª‘™Àÿ12∫Õ∆‰◊Ó–°◊”Ω⁄µ„11µƒŒª÷√£®Õº3£©°£
3. ∂‘”⁄Ω⁄µ„a[2]=5µƒµ˜’˚£¨÷ª–Ë“™Ωªªª‘™Àÿ5∫Õ∆‰◊Ó–°◊”Ω⁄µ„1µƒŒª÷√£®Õº4£©°£
4. ∂‘”⁄Ω⁄µ„a[1]=6µƒµ˜’˚£¨÷ª–Ë“™Ωªªª‘™Àÿ6∫Õ∆‰◊Ó–°◊”Ω⁄µ„4µƒŒª÷√£®Õº5£©°£
5. ∂‘”⁄Ω⁄µ„a[0]=7µƒµ˜’˚£¨÷ª–Ë“™Ωªªª‘™Àÿ7∫Õ∆‰◊Ó–°◊”Ω⁄µ„1µƒŒª÷√£¨»ª∫ÛΩªªª7∫Õ∆‰◊Ó–°◊‘º∫µ„3µƒŒª÷√£®Õº6£©°£
÷¡¥À£¨µ˜’˚Õͱœ£¨Ω®∂—ÕÍ≥…°£
‘Ÿ¿¥ªÿπÀ“ªœ¬£¨PriorityQueueµƒΩ®∂—¥˙¬Î£¨ø¥ø¥ «∑Òø…“‘ø¥µ√∂Æ¡À°£
1 private void heapify() {2 for (int i = (size >>> 1) - 1; i >= 0; i--)3 siftDown(i, (E) queue[i]);4 }
°°°°int i = (size >>> 1) - 1£¨’‚––¥˙¬Î «Œ™¡À’“—∞◊Ó∫Û“ª∏ˆ∑«“∂◊”Ω⁄µ„£¨»ª∫Ûµπ–ÚΩ¯––"œ¬“∆"siftDown≤Ÿ◊˜£¨ «≤ª «∫‹œ‘»ª¡À°£
µΩ’‚¿ÔPriorityQueueµƒª˘±æ≤Ÿ◊˜æÕ∑÷ŒˆÕÍ¡À£¨√˜∞◊¡À∆‰µ◊≤„∂˛≤Ê∂—µƒ∏≈ƒÓº∞∆‰»Î∂”°¢≥ˆ∂”°¢Ω®∂—µ»≤Ÿ◊˜£¨∆‰À˚µƒ“ª–©∑Ω∑®¥˙¬ÎæÕ∫‹ºÚµ•¡À£¨’‚¿ÔæÕ≤ª“ª“ª∑÷Œˆ¡À°£
PriorityQueue ÕÍ£°
≤Œº˚£∫
≤Œøº◊ ¡œ£∫