2013�����ʱ���ҿ���������������һ��������Java�������ȫ���Ķ�����������Ķ����Ժ�������ĺܶ���Ŀ���ظ���û�м�ֵ����Ŀ�����в��ٵIJο���Ҳ�Ǵ���ģ������һ��˰����ʱ��������ν�ġ�Java���Դ�ȫ��������ȫ����������·������ҵ�CSDN���͡������Ĺ����У������˵�ʱJDK���°汾��Java 7����������Ŀ�Ĵ𰸺���ش��룬ȥ����EJB 2.x��JSF���������ݻ��ʱ���ݣ����������ݽṹ���㷨��������վ�����ܹ������ģʽ��UML��Spring MVC�����ݲ��Ժܶ�֪ʶ����������������������hashCode��������ơ������ռ���������̡����ݿ�����ȡ���ʱ������ϣ���������о������ֵIJ���ϵͳ�����ݿ⡢�������Ե�����Ҳ�����ȥ���������ڸ���ԭ������ֻ��������150�������⡣������ο���ǣ���150����ǰ������˺ܶ��ˣ���������CSDN�����ϵ��ܷ�����������5��Σ����ջ����ܶ���վ������ԭ���ķ�ʽת���ˡ����һ���ڣ��ðٶ�����"Java����"��д����Щ���������϶��������������ǰ5���������Ҿ�����ɽ����Ϊ��Щ����һ����ȷ�Ϳ����ܶ��ˡ�2014���ʱ������������30���⣬ϣ����֮ǰ��©���������֪ʶ�㲹����ȥ��������Ȼ�о���һ©����Java 8������ܶ��µĶ�������Ҫȥ�ܽ��������Ϊ�ˣ��Ҳ�ֹһ�ε�����֮ǰ��180�⣬�ĵ��Լ��Ѿ��о���Щƣ�������ᷳ�ˡ�2014�������Լ�����ѧ�����кܶ�������Java����Ա��Java����ʦ�Ĺ�����λ�����ǵ����Ծ���Ҳ��û���ü�����ҷ��������Ǻ���һ�ֳ嶯���Ҿ�������дһƪ��Java������ȫ������������ƪ���¾͵����ˡ��벻Ҫ���Ұ���Щ���ֹ���������д��һ�Σ���Ϊÿ��д�����������ظ������ݣ���Ҳ��Ҫ������ʹ�õı�����Ժ���ؼ�����������˼����������������������������������������ҷ�����һ������õĶ�����һ��������Ķ�����һ�������µĶ���������Щ����Ҳ��Ȼ��˵��һ��ְҵ����Ա��˼�롢�������С�
1������������������Щ���棿
����������������Ҫ�����¼������棺
- �������ǽ�һ�����Ĺ�ͬ�����ܽ����������Ĺ��̣��������ݳ������Ϊ���������档����ֻ��ע��������Щ���Ժ���Ϊ��������ע��Щ��Ϊ��ϸ����ʲô��
- �̳У��̳��Ǵ�������õ��̳���Ϣ��������Ĺ��̡��ṩ�̳���Ϣ���౻��Ϊ���ࣨ���ࡢ���ࣩ���õ��̳���Ϣ���౻��Ϊ���ࣨ�����ࣩ���̳��ñ仯�е�����ϵͳ����һ���������ԣ�ͬʱ�̳�Ҳ�Ƿ�װ�����пɱ����ص���Ҫ�ֶΣ���������������Ķ��ֺ격ʿ�ġ�Java��ģʽ�������ģʽ���⡷�й�������ģʽ�IJ��֣���
- ��װ��ͨ����Ϊ��װ�ǰ����ݺͲ������ݵķ����������������ݵķ���ֻ��ͨ���Ѷ���Ľӿڡ��������ı��ʾ��ǽ���ʵ��������һϵ����ȫ���Ρ���յĶ������������б�д�ķ������Ƕ�ʵ��ϸ�ڵ�һ�ַ�װ�����DZ�дһ������Ƕ����ݺ����ݲ����ķ�װ������˵����װ��������һ�п����صĶ�����ֻ������ṩ��ı�̽ӿڣ�����������ͨϴ�»���ȫ�Զ�ϴ�»��IJ������ȫ�Զ�ϴ�»���װ������˲�������������������ʹ�õ������ֻ�Ҳ�Ƿ�װ���㹻�õģ���Ϊ���������㶨�����е����飩��
- ��̬�ԣ���̬����ָ������ͬ�����͵Ķ����ͬһ��Ϣ������ͬ����Ӧ����˵������ͬ���Ķ������õ���ͬ���ķ����������˲�ͬ�����顣��̬�Է�Ϊ����ʱ�Ķ�̬�Ժ�����ʱ�Ķ�̬�ԡ����������ķ�����Ϊ����������ṩ�ķ�����ô����ʱ�Ķ�̬�Կ��Խ���Ϊ����Aϵͳ����Bϵͳ�ṩ�ķ���ʱ��Bϵͳ�ж����ṩ����ķ�ʽ����һ�ж�Aϵͳ��˵�������ģ�����綯���뵶��Aϵͳ�����Ĺ���ϵͳ��Bϵͳ��Bϵͳ����ʹ�õ�ع�������ý����磬�������п�����̫���ܣ�Aϵͳֻ��ͨ��B�������ù���ķ�����������֪������ϵͳ�ĵײ�ʵ����ʲô������ͨ�����ַ�ʽ����˶��������������أ�overload��ʵ�ֵ��DZ���ʱ�Ķ�̬�ԣ�Ҳ��Ϊǰ������������д��override��ʵ�ֵ�������ʱ�Ķ�̬�ԣ�Ҳ��Ϊ���������ʱ�Ķ�̬������������Ķ�����Ҫʵ�ֶ�̬��Ҫ�������£�1). ������д������̳и��ಢ��д���������еĻ����ķ�������2). �������ͣ��ø������������������Ͷ�������ͬ�������õ���ͬ���ķ����ͻ�����������IJ�ͬ�����ֳ���ͬ����Ϊ����
2���������η�public,private,protected,�Լ���д��Ĭ�ϣ�ʱ������
��
| ���η� | ��ǰ�� | ͬ �� | �� �� | ������ |
|---|---|---|---|---|
| public | �� | �� | �� | �� |
| protected | �� | �� | �� | �� |
| default | �� | �� | �� | �� |
| private | �� | �� | �� | �� |
��ij�Ա��д��������ʱĬ��Ϊdefault��Ĭ�϶���ͬһ�����е��������൱�ڹ�����public�������ڲ���ͬһ�����е��������൱��˽�У�private�����ܱ�����protected���������൱�ڹ������Բ���ͬһ���е�û�и��ӹ�ϵ�����൱��˽�С�Java�У��ⲿ������η�ֻ����public��Ĭ�ϣ���ij�Ա�������ڲ��ࣩ�����η��������������֡�
3��String �������������������
�𣺲��ǡ�Java�еĻ�����������ֻ��8����byte��short��int��long��float��double��char��boolean�����˻������ͣ�primitive type����ö�����ͣ�enumeration type����ʣ�µĶ����������ͣ�reference type����
4��float f=3.4;�Ƿ���ȷ��
��:����ȷ��3.4��˫����������˫�����ͣ�double����ֵ�������ͣ�float��������ת�ͣ�down-casting��Ҳ��Ϊխ��������ɾ�����ʧ�������Ҫǿ������ת��float f =(float)3.4; ����д��float f =3.4F;��
5��short s1 = 1; s1 = s1 + 1;���?short s1 = 1; s1 += 1;���
�𣺶���short s1 = 1; s1 = s1 + 1;����1��int���ͣ����s1+1������Ҳ��int �ͣ���Ҫǿ��ת�����Ͳ��ܸ�ֵ��short�͡���short s1 = 1; s1 += 1;������ȷ���룬��Ϊs1+= 1;�൱��s1 = (short)(s1 + 1);������������ǿ������ת����
6��Java��û��goto��
��goto ��Java�еı����֣���Ŀǰ�汾��Java��û��ʹ�á�������James Gosling��Java֮������д�ġ�The Java Programming Language��һ��ĸ�¼�и�����һ��Java�ؼ����б���������goto��const��������������Ŀǰ��ʹ�õĹؼ��֣������Щ�ط������֮Ϊ�����֣���ʵ�����������Ӧ���и��㷺�����壬��Ϊ��ϤC���Եij���Ա��֪������ϵͳ�����ʹ�ù�������������ĵ��ʻʵ���϶�����Ϊ�����֣�
7��int��Integer��ʲô����
��Java��һ�����������������������ԣ�����Ϊ�˱�̵ķ��㻹�������˻����������ͣ�����Ϊ���ܹ�����Щ�����������͵��ɶ��������JavaΪÿһ�������������Ͷ������˶�Ӧ�İ�װ���ͣ�wrapper class����int�İ�װ�����Integer����Java 5��ʼ�������Զ�װ��/������ƣ�ʹ�ö��߿����ת����
Java Ϊÿ��ԭʼ�����ṩ�˰�װ���ͣ�
- ԭʼ����: boolean��char��byte��short��int��long��float��double
- ��װ���ͣ�Boolean��Character��Byte��Short��Integer��Long��Float��Double
class AutoUnboxingTest { public static void main(String[] args) { Integer a = new Integer(3); Integer b = 3; // ��3�Զ�װ���Integer���� int c = 3; System.out.println(a == b); // false ��������û������ͬһ���� System.out.println(a == c); // true a�Զ������int�����ٺ�c�Ƚ� }}���������һ�������⣬Ҳ�Ǻ��Զ�װ��Ͳ����е��ϵ�ģ�����������ʾ��
public class Test03 { public static void main(String[] args) { Integer f1 = 100, f2 = 100, f3 = 150, f4 = 150; System.out.println(f1 == f2); System.out.println(f3 == f4); }}������������������Ϊ�������Ҫô����trueҪô����false��������Ҫע�����f1��f2��f3��f4�ĸ���������Integer�������ã����������==����ȽϵIJ���ֵ�������á�װ��ı�����ʲô�أ������Ǹ�һ��Integer����һ��intֵ��ʱ�����Integer��ľ�̬����valueOf���������valueOf��Դ�����֪��������ʲô��
public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }IntegerCache��Integer���ڲ��࣬�����������ʾ��
/** * Cache to support the object identity semantics of autoboxing for values between * -128 and 127 (inclusive) as required by JLS. * * The cache is initialized on first usage. The size of the cache * may be controlled by the {@code -XX:AutoBoxCacheMax=<size>} option. * During VM initialization, java.lang.Integer.IntegerCache.high property * may be set and saved in the private system properties in the * sun.misc.VM class. */ private static class IntegerCache { static final int low = -128; static final int high; static final Integer cache[]; static { // high value may be configured by property int h = 127; String integerCacheHighPropValue = sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high"); if (integerCacheHighPropValue != null) { try { int i = parseInt(integerCacheHighPropValue); i = Math.max(i, 127); // Maximum array size is Integer.MAX_VALUE h = Math.min(i, Integer.MAX_VALUE - (-low) -1); } catch( NumberFormatException nfe) { // If the property cannot be parsed into an int, ignore it. } } high = h; cache = new Integer[(high - low) + 1]; int j = low; for(int k = 0; k < cache.length; k++) cache[k] = new Integer(j++); // range [-128, 127] must be interned (JLS7 5.1.7) assert IntegerCache.high >= 127; } private IntegerCache() {} }��˵�����������������ֵ��-128��127֮�䣬��ô����new�µ�Integer������ֱ�����ó������е�Integer���������������������f1==f2�Ľ����true����f3==f4�Ľ����false��
���ѣ�Խ��ò�Ƽ����������е�������Խ�࣬��Ҫ���������൱���Ĺ�����
8��&��&&������
��&������������÷���(1)��λ�룻(2)���롣&&������Ƕ�·�����㡣�������·��IJ���Ƿdz���ģ���Ȼ���߶�Ҫ��������������˵IJ���ֵ����true��������ʽ��ֵ����true��&&֮���Գ�Ϊ��·��������Ϊ�����&&��ߵı���ʽ��ֵ��false���ұߵı���ʽ�ᱻֱ�Ӷ�·��������������㡣�ܶ�ʱ�����ǿ��ܶ���Ҫ��&&������&����������֤�û���¼ʱ�ж��û�������null���Ҳ��ǿ��ַ�����Ӧ��дΪ��username != null &&!username.equals("")�����ߵ�˳���ܽ�������������&���������Ϊ��һ������������������������ܽ����ַ�����equals�Ƚϣ���������NullPointerException�쳣��ע�⣺�����������|���Ͷ�·���������||���IJ��Ҳ����ˡ�
���䣺�������ϤJavaScript��������ܸ��ܸ��ܵ���·�����ǿ�����ΪJavaScript�ĸ��־��ȴ���ת��·���㿪ʼ�ɡ�
9�������ڴ��е�ջ(stack)����(heap)�;�̬��(static area)���÷���
��ͨ�����Ƕ���һ�������������͵ı�����һ����������ã����о��Ǻ������õ��ֳ����涼ʹ���ڴ��е�ջ�ռ䣻��ͨ��new�ؼ��ֺ����������Ķ�����ڶѿռ䣻�����е���������literal����ֱ����д��100��"hello"�ͳ������Ƿ��ھ�̬���С�ջ�ռ����������쵫��ջ��С��ͨ�������Ķ����Ƿ��ڶѿռ䣬�����������ڴ�û�б���������ʹ�õĿռ�����Ӳ���ϵ������ڴ涼���Ա����ɶѿռ���ʹ�á�
String str = new String("hello");���������б���str����ջ�ϣ���new�����������ַ���������ڶ��ϣ���"hello"������������ھ�̬����
���䣺���°汾��Java����Java 6��ij�����¿�ʼ����ʹ����һ���"���ݷ���"�ļ��������Խ�һЩ�ֲ��������ջ������������IJ������ܡ�
10��Math.round(11.5) ���ڶ��٣�Math.round(-11.5)���ڶ��٣�
��Math.round(11.5)�ķ���ֵ��12��Math.round(-11.5)�ķ���ֵ��-11�����������ԭ�����ڲ����ϼ�0.5Ȼ�������ȡ����
11��swtich �Ƿ���������byte �ϣ��Ƿ���������long �ϣ��Ƿ���������String�ϣ�
����Java 5��ǰ��switch(expr)�У�exprֻ����byte��short��char��int����Java 5��ʼ��Java��������ö�����ͣ�exprҲ������enum���ͣ���Java 7��ʼ��expr���������ַ�����String�������dz����ͣ�long����Ŀǰ���еİ汾�ж��Dz����Եġ�
12��������Ч�ʵķ�������2����8��
�� 2 << 3������3λ�൱�ڳ���2��3�η�������3λ�൱�ڳ���2��3�η�����
���䣺����Ϊ��д������дhashCode����ʱ�����ܻῴ��������ʾ�Ĵ��룬��ʵ���Dz�̫����ΪʲôҪʹ�������ij˷�������������ϣ�루ɢ���룩������Ϊʲô������Ǹ�������Ϊʲôͨ��ѡ��31�������ǰ��������Ĵ�������Լ��ٶ�һ�£�ѡ��31����Ϊ��������λ�ͼ�������������˷����Ӷ��õ����õ����ܡ�˵������������Ѿ��뵽�ˣ�31 * num �ȼ���(num << 5) - num������5λ�൱�ڳ���2��5�η��ټ�ȥ�������൱�ڳ���31�����ڵ�VM�����Զ��������Ż���
public class PhoneNumber { private int areaCode; private String prefix; private String lineNumber; @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + areaCode; result = prime * result + ((lineNumber == null) ? 0 : lineNumber.hashCode()); result = prime * result + ((prefix == null) ? 0 : prefix.hashCode()); return result; } @Override public boolean equals(Object obj) { if (this == obj) return true; if (obj == null) return false; if (getClass() != obj.getClass()) return false; PhoneNumber other = (PhoneNumber) obj; if (areaCode != other.areaCode) return false; if (lineNumber == null) { if (other.lineNumber != null) return false; } else if (!lineNumber.equals(other.lineNumber)) return false; if (prefix == null) { if (other.prefix != null) return false; } else if (!prefix.equals(other.prefix)) return false; return true; }}13��������û��length()������String��û��length()������
������û��length()��������length �����ԡ�String ��length()������JavaScript�У�����ַ����ij�����ͨ��length���Եõ��ģ���һ������Java������
14����Java�У����������ǰ�Ķ���Ƕ��ѭ����
���������ѭ��ǰ��һ�������A��Ȼ����break A;������������ѭ������Java��֧�ִ���ǩ��break��continue��䣬�����е�������C��C++�е�goto��䣬���Ǿ���Ҫ����ʹ��gotoһ����Ӧ�ñ���ʹ�ô���ǩ��break��continue����Ϊ����������ij����ø����ţ��ܶ�ʱ���������෴�����ã������������ʵ��֪�����ã�
15����������constructor���Ƿ�ɱ���д��override����
�𣺹��������ܱ��̳У���˲��ܱ���д�������Ա����ء�
16����������ֵ��ͬ(x.equals(y) == true)����ȴ���в�ͬ��hash code����仰�Բ��ԣ�
�𣺲��ԣ������������x��y����x.equals(y) == true�����ǵĹ�ϣ�루hash code��Ӧ����ͬ��Java����eqauls������hashCode�����������涨�ģ�(1)�������������ͬ��equals��������true������ô���ǵ�hashCodeֵһ��Ҫ��ͬ��(2)������������hashCode��ͬ�����Dz���һ����ͬ����Ȼ����δ��Ҫ����Ҫ��ȥ�������������Υ��������ԭ��ͻᷢ����ʹ������ʱ����ͬ�Ķ�����Գ�����Set�����У�ͬʱ������Ԫ�ص�Ч�ʻ����½�������ʹ�ù�ϣ�洢��ϵͳ�������ϣ��Ƶ���ij�ͻ������ɴ�ȡ���ܼ����½�����
���䣺����equals��hashCode�������ܶ�Java����֪�������ܶ���Ҳ���ǽ���֪�����ѣ���Joshua Bloch�Ĵ�����Effective Java�����ܶ�������˾����Effective Java������Java���˼�롷�Լ����ع������Ƽ��д�����������Java����Ա�ؿ��鼮������㻹û�������ǾϽ�ȥ����ѷ��һ���ɣ�������������equals�����ģ�����equals�������������Է��ԣ�x.equals(x)���뷵��true�����Գ��ԣ�x.equals(y)����trueʱ��y.equals(x)Ҳ���뷵��true���������ԣ�x.equals(y)��y.equals(z)������trueʱ��x.equals(z)Ҳ���뷵��true����һ���ԣ���x��y���õĶ�����Ϣû�б���ʱ����ε���x.equals(y)Ӧ�õõ�ͬ���ķ���ֵ�������Ҷ����κη�nullֵ������x��x.equals(null)���뷵��false��ʵ�ָ�������equals�����ľ��ϰ�����1. ʹ��==���������"�����Ƿ�Ϊ������������"��2. ʹ��instanceof���������"�����Ƿ�Ϊ��ȷ������"��3. �������еĹؼ����ԣ��������������������Ƿ���֮��ƥ�䣻4. ��д��equals���������Լ����Ƿ�����Գ��ԡ������ԡ�һ���ԣ�5. ��дequalsʱ����Ҫ��дhashCode��6. ��Ҫ��equals���������е�Object�����滻Ϊ���������ͣ�����дʱ��Ҫ����@Overrideע�⡣
17���Ƿ���Լ̳�String�ࣿ
��String ����final�࣬�����Ա��̳С�
���䣺�̳�String��������һ���������Ϊ����String������õ����÷�ʽ�ǹ�����ϵ��Has-A����������ϵ��Use-A�������Ǽ̳й�ϵ��Is-A����
18����һ���������������ݵ�һ�������˷����ɸı������������ԣ����ɷ��ر仯��Ľ������ô���ﵽ����ֵ���ݻ������ô��ݣ�
����ֵ���ݡ�Java���Եķ�������ֻ֧�ֲ�����ֵ���ݡ���һ������ʵ����Ϊһ�����������ݵ�������ʱ��������ֵ���ǶԸö�������á���������Կ����ڱ����ù����б��ı䣬���Զ������õĸı��Dz���Ӱ�쵽�����ߵġ�C++��C#�п���ͨ�������û�����������ı䴫��IJ�����ֵ����C#�п��Ա�д������ʾ�Ĵ��룬������Java��ȴ��������
using System;namespace CS01 { class Program { public static void swap(ref int x, ref int y) { int temp = x; x = y; y = temp; } public static void Main (string[] args) { int a = 5, b = 10; swap (ref a, ref b); // a = 10, b = 5; Console.WriteLine ("a = {0}, b = {1}", a, b); } }}˵����Java��û�д�����ʵ���Ƿdz��IJ����㣬��һ����Java 8����Ȼû�еõ��Ľ������������Java��д�Ĵ����вŻ���ִ�����Wrapper�ࣨ����Ҫͨ�����������ĵ���������һ��Wrapper���У��ٽ�Wrapper�����뷽����������������ֻ���ô�����ӷ�ף��������ô�C��C++ת��ΪJava����Ա�Ŀ����������̡�
19��String��StringBuilder��StringBuffer������
��Javaƽ̨�ṩ���������͵��ַ�����String��StringBuffer/StringBuilder�����ǿ��Դ���Ͳ����ַ���������String��ֻ���ַ�����Ҳ����ζ��String���õ��ַ��������Dz��ܱ��ı�ġ���StringBuffer/StringBuilder���ʾ���ַ����������ֱ�ӽ����ġ�StringBuilder��Java 5������ģ�����StringBuffer�ķ�����ȫ��ͬ���������������ڵ��̻߳�����ʹ�õģ���Ϊ�������з��涼û�б�synchronized���Σ��������Ч��Ҳ��StringBufferҪ�ߡ�
������1 - ʲô�������+����������ַ������ӱȵ���StringBuffer/StringBuilder�����append���������ַ������ܸ��ã�
������2 - ��˵���������������
class StringEqualTest { public static void main(String[] args) { String s1 = "Programming"; String s2 = new String("Programming"); String s3 = "Program" + "ming"; System.out.println(s1 == s2); System.out.println(s1 == s3); System.out.println(s1 == s1.intern()); }}���䣺String�����intern������õ��ַ��������ڳ������ж�Ӧ�İ汾�����ã��������������һ���ַ�����String�����equals�����true���������������û�ж�Ӧ���ַ���������ַ����������ӵ��������У�Ȼ�س��������ַ��������á�
20�����أ�Overload������д��Override�����������صķ����ܷ���ݷ������ͽ������֣�
�𣺷��������غ���д����ʵ�ֶ�̬�ķ�ʽ����������ǰ��ʵ�ֵ��DZ���ʱ�Ķ�̬�ԣ�������ʵ�ֵ�������ʱ�Ķ�̬�ԡ����ط�����һ�����У�ͬ���ķ�������в�ͬ�IJ����б����������Ͳ�ͬ������������ͬ���߶��߶���ͬ������Ϊ���أ���д�����������븸��֮�䣬��дҪ�����౻��д�����븸�౻��д��������ͬ�ķ������ͣ��ȸ��౻��д�������÷��ʣ����ܱȸ��౻��д��������������쳣�����ϴ���ԭ�����ضԷ�������û�������Ҫ��
�����⣺��Ϊ���������������ʹ�����һ������ - "Ϊʲô���ܸ��ݷ�����������������"����˵����Ĵ𰸰ɣ�
21������һ��JVM����class�ļ���ԭ�����ƣ�
��JVM�����װ���������������ClassLoader��������������ʵ�ֵģ�Java�е����������һ����Ҫ��Java����ʱϵͳ�����������������ʱ���Һ�װ�����ļ��е��ࡣ
����Java�Ŀ�ƽ̨�ԣ����������JavaԴ������һ����ִ�г�����һ���������ļ�����Java������Ҫʹ��ij����ʱ��JVM��ȷ��������Ѿ������ء����ӣ���֤�����ͽ������ͳ�ʼ������ļ�����ָ�����.class�ļ��е����ݶ��뵽�ڴ��У�ͨ���Ǵ���һ���ֽ��������.class�ļ���Ȼ����������������Ӧ��Class��������ɺ�Class�������������Դ�ʱ��������á����౻���غ�ͽ������ӽΣ���һ�ΰ�����֤������Ϊ��̬���������ڴ沢����Ĭ�ϵij�ʼֵ���ͽ����������������滻Ϊֱ�����ã��������衣���JVM������г�ʼ����������1)��������ֱ�ӵĸ��ಢ������û�б���ʼ������ô���ȳ�ʼ�����ࣻ2)������д��ڳ�ʼ����䣬������ִ����Щ��ʼ����䡣
��ļ����������������ɵģ������������������������BootStrap������չ��������Extension����ϵͳ��������System�����û��Զ������������java.lang.ClassLoader�����ࣩ����Java 2��JDK 1.2����ʼ������ع��̲�ȡ�˸���ί�л��ƣ�PDM����PDM���õı�֤��Javaƽ̨�İ�ȫ�ԣ��ڸû����У�JVM�Դ���Bootstrap�Ǹ��������������ļ����������ҽ���һ���������������ļ���������������������أ��������������Ϊ��ʱ������������������м��ء�JVM������Java�����ṩ��Bootstrap�����á������ǹ��ڼ������������˵����
- Bootstrap��һ���ñ��ش���ʵ�֣��������JVM����������⣨rt.jar����
- Extension����java.ext.dirsϵͳ������ָ����Ŀ¼�м�����⣬���ĸ���������Bootstrap��
- System���ֽ�Ӧ������������丸����Extension������Ӧ����㷺��������������ӻ�������classpath����ϵͳ����java.class.path��ָ����Ŀ¼�м����࣬���û��Զ����������Ĭ�ϸ���������
22��char �ͱ������ܲ��ܴ���һ�����ĺ��֣�Ϊʲô��
��char���Ϳ��Դ洢һ�����ĺ��֣���ΪJava��ʹ�õı�����Unicode����ѡ���κ��ض��ı��룬ֱ��ʹ���ַ����ַ����еı�ţ�����ͳһ��Ψһ��������һ��char����ռ2���ֽڣ�16���أ������Է�һ��������û����ġ�
���䣺ʹ��Unicode��ζ���ַ���JVM�ڲ����ⲿ�в�ͬ�ı�����ʽ����JVM�ڲ�����Unicode��������ַ�����JVM�ڲ�ת�Ƶ��ⲿʱ����������ļ�ϵͳ�У�����Ҫ���б���ת��������Java�����ֽ������ַ������Լ����ַ������ֽ���֮�����ת����ת��������InputStreamReader��OutputStreamReader�������������ֽ������ַ���֮����������࣬�е��˱���ת����������C����Ա��˵��Ҫ��������ı���ת������Ҫ������union��������/�����壩�����ڴ��������ʵ���ˡ�
23�������ࣨabstract class���ͽӿڣ�interface����ʲô��ͬ��
�𣺳�����ͽӿڶ����ܹ�ʵ�����������Զ��������ͽӿ����͵����á�һ��������̳���ij�����������ʵ����ij���ӿڶ���Ҫ�����еij���ȫ������ʵ�֣����������Ȼ��Ҫ������Ϊ�����ࡣ�ӿڱȳ�������ӳ�����Ϊ�������п��Զ��幹�����������г����;��巽�������ӿ��в��ܶ��幹�����������еķ���ȫ�����dz������������еij�Ա������private��Ĭ�ϡ�protected��public�ģ����ӿ��еij�Աȫ����public�ġ��������п��Զ����Ա���������ӿ��ж���ij�Ա����ʵ���϶��dz������г���������뱻����Ϊ�����࣬��������δ��Ҫ�г�����
24����̬Ƕ����(Static Nested Class)���ڲ��ࣨInner Class���IJ�ͬ��
��Static Nested Class�DZ�����Ϊ��̬��static�����ڲ��࣬�����Բ��������ⲿ��ʵ����ʵ��������ͨ�����ڲ�����Ҫ���ⲿ��ʵ���������ʵ���������������ͦ����ģ�������ʾ��
/** * �˿��ࣨһ���˿ˣ� * @author ��� * */public class Poker { private static String[] suites = {"����", "����", "�ݻ�", "����"}; private static int[] faces = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13}; private Card[] cards; /** * ������ * */ public Poker() { cards = new Card[52]; for(int i = 0; i < suites.length; i++) { for(int j = 0; j < faces.length; j++) { cards[i * 13 + j] = new Card(suites[i], faces[j]); } } } /** * ϴ�� ��������� * */ public void shuffle() { for(int i = 0, len = cards.length; i < len; i++) { int index = (int) (Math.random() * len); Card temp = cards[index]; cards[index] = cards[i]; cards[i] = temp; } } /** * ���� * @param index ���Ƶ�λ�� * */ public Card deal(int index) { return cards[index]; } /** * ��Ƭ�ࣨһ���˿ˣ� * [�ڲ���] * @author ��� * */ public class Card { private String suite; // ��ɫ private int face; // ���� public Card(String suite, int face) { this.suite = suite; this.face = face; } @Override public String toString() { String faceStr = ""; switch(face) { case 1: faceStr = "A"; break; case 11: faceStr = "J"; break; case 12: faceStr = "Q"; break; case 13: faceStr = "K"; break; default: faceStr = String.valueOf(face); } return suite + faceStr; } }}���Դ��룺
class PokerTest { public static void main(String[] args) { Poker poker = new Poker(); poker.shuffle(); // ϴ�� Poker.Card c1 = poker.deal(0); // ����һ���� // ���ڷǾ�̬�ڲ���Card // ֻ��ͨ�����ⲿ��Poker������ܴ���Card���� Poker.Card c2 = poker.new Card("����", 1); // �Լ�����һ���� System.out.println(c1); // ϴ�ƺ�ĵ�һ�� System.out.println(c2); // ��ӡ: ����A }}������ - ����Ĵ�����Щ�ط�������������
class Outer { class Inner {} public static void foo() { new Inner(); } public void bar() { new Inner(); } public static void main(String[] args) { new Inner(); }}ע�⣺Java�зǾ�̬�ڲ������Ĵ���Ҫ�������ⲿ������������������foo��main�������Ǿ�̬��������̬������û��this��Ҳ����˵û����ν���ⲿ���������������ڲ���������Ҫ�ھ�̬�����д����ڲ����������������
new Outer().new Inner();25��Java �л�����ڴ�й©�����������
��������Java��Ϊ���������ջ��ƣ�GC����������ڴ�й¶���⣨��Ҳ��Java���㷺ʹ���ڷ������˱�̵�һ����Ҫԭ��Ȼ����ʵ�ʿ����У����ܻ�������õ��ɴ�Ķ�����Щ�����ܱ�GC���գ����Ҳ�ᵼ���ڴ�й¶�ķ���������Hibernate��Session��һ�����棩�еĶ������ڳ־�̬�������������Dz��������Щ����ģ�Ȼ����Щ�����п��ܴ������õ����������������ʱ�رգ�close������գ�flush��һ������Ϳ��ܵ����ڴ�й¶�����������еĴ���Ҳ�ᵼ���ڴ�й¶��
import java.util.Arrays;import java.util.EmptyStackException;public class MyStack<T> { private T[] elements; private int size = 0; private static final int INIT_CAPACITY = 16; public MyStack() { elements = (T[]) new Object[INIT_CAPACITY]; } public void push(T elem) { ensureCapacity(); elements[size++] = elem; } public T pop() { if(size == 0) throw new EmptyStackException(); return elements[--size]; } private void ensureCapacity() { if(elements.length == size) { elements = Arrays.copyOf(elements, 2 * size + 1); } }}����Ĵ���ʵ����һ��ջ���Ƚ������FILO�����ṹ��է��֮���ƺ�û��ʲô���Ե����⣬����������ͨ�����д�ĸ��ֵ�Ԫ���ԡ�Ȼ�����е�pop����ȴ�����ڴ�й¶�����⣬��������pop��������ջ�еĶ���ʱ���ö��ᱻ�����������գ���ʹʹ��ջ�ij�����������Щ������Ϊջ�ڲ�ά���Ŷ���Щ����Ĺ������ã�obsolete reference������֧���������յ������У��ڴ�й¶�Ǻ����εģ������ڴ�й¶��ʵ��������ʶ�Ķ��֡����һ���������ñ�����ʶ�ı��������ˣ���ô�������������ᴦ���������Ҳ���ᴦ���ö������õ���������ʹ�����Ķ���ֻ������������Ҳ���ܻᵼ�ºܶ�Ķ����ų�����������֮�⣬�Ӷ�����������ش�Ӱ�죬��������»�����Disk Paging�������ڴ���Ӳ�̵������ڴ潻�����ݣ����������OutOfMemoryError��
26������ģ�abstract�������Ƿ��ͬʱ�Ǿ�̬�ģ�static��,�Ƿ��ͬʱ�DZ��ط�����native�����Ƿ��ͬʱ��synchronized���Σ�
�𣺶����ܡ�������Ҫ������д������̬�ķ�����������д�ģ���˶�����ì�ܵġ����ط������ɱ��ش��루��C���룩ʵ�ֵķ�������������û��ʵ�ֵģ�Ҳ��ì�ܵġ�synchronized�ͷ�����ʵ��ϸ���йأ��������漰ʵ��ϸ�ڣ����Ҳ���ì�ܵġ�
27��������̬������ʵ������������
�𣺾�̬�����DZ�static���η����εı�����Ҳ��Ϊ��������������࣬����������κ�һ������һ����ܴ������ٸ�����̬�������ڴ������ҽ���һ��������ʵ����������������ijһʵ������Ҫ�ȴ�������Ȼ��ͨ��������ܷ��ʵ�������̬��������ʵ���ö���������ڴ档
���䣺��Java�����У����������������ͨ�����д����ľ�̬��Ա��
28���Ƿ���Դ�һ����̬��static�������ڲ������ԷǾ�̬��non-static�������ĵ��ã�
�𣺲����ԣ���̬����ֻ�ܷ��ʾ�̬��Ա����Ϊ�Ǿ�̬�����ĵ���Ҫ�ȴ��������ڵ��þ�̬����ʱ���ܶ���û�б���ʼ����
29�����ʵ�ֶ����¡��
�������ַ�ʽ��
??1). ʵ��Cloneable�ӿڲ���дObject���е�clone()������
??2). ʵ��Serializable�ӿڣ�ͨ����������л��ͷ����л�ʵ�ֿ�¡������ʵ����������ȿ�¡���������¡�
import java.io.ByteArrayInputStream;import java.io.ByteArrayOutputStream;import java.io.ObjectInputStream;import java.io.ObjectOutputStream;public class MyUtil { private MyUtil() { throw new AssertionError(); } public static <T> T clone(T obj) throws Exception { ByteArrayOutputStream bout = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream(bout); oos.writeObject(obj); ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray()); ObjectInputStream ois = new ObjectInputStream(bin); return (T) ois.readObject(); // ˵��������ByteArrayInputStream��ByteArrayOutputStream�����close����û���κ����� // �����������ڴ����ֻҪ��������������������ܹ��ͷ���Դ����һ�㲻ͬ�ڶ��ⲿ��Դ�����ļ��������ͷ� }}�����Dz��Դ��룺
import java.io.Serializable;/** * ���� * @author ��� * */class Person implements Serializable { private static final long serialVersionUID = -9102017020286042305L; private String name; // ���� private int age; // ���� private Car car; // ���� public Person(String name, int age, Car car) { this.name = name; this.age = age; this.car = car; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public Car getCar() { return car; } public void setCar(Car car) { this.car = car; } @Override public String toString() { return "Person [name=" + name + ", age=" + age + ", car=" + car + "]"; }}/** * С������ * @author ��� * */class Car implements Serializable { private static final long serialVersionUID = -5713945027627603702L; private String brand; // Ʒ�� private int maxSpeed; // ���ʱ�� public Car(String brand, int maxSpeed) { this.brand = brand; this.maxSpeed = maxSpeed; } public String getBrand() { return brand; } public void setBrand(String brand) { this.brand = brand; } public int getMaxSpeed() { return maxSpeed; } public void setMaxSpeed(int maxSpeed) { this.maxSpeed = maxSpeed; } @Override public String toString() { return "Car [brand=" + brand + ", maxSpeed=" + maxSpeed + "]"; }}class CloneTest { public static void main(String[] args) { try { Person p1 = new Person("Hao LUO", 33, new Car("Benz", 300)); Person p2 = MyUtil.clone(p1); // ��ȿ�¡ p2.getCar().setBrand("BYD"); // �Ŀ�¡��Person����p2���������������Ʒ������ // ԭ����Person����p1���������������ܵ��κ�Ӱ�� // ��Ϊ�ڿ�¡Person����ʱ���������������Ҳ����¡�� System.out.println(p1); } catch (Exception e) { e.printStackTrace(); } }}ע�⣺�������л��ͷ����л�ʵ�ֵĿ�¡����������ȿ�¡������Ҫ����ͨ�������������Լ���Ҫ��¡�Ķ����Ƿ�֧�����л����������DZ�������ɵģ�����������ʱ�׳��쳣�������Ƿ�����������ʹ��Object���clone������¡�����������ڱ����ʱ��¶�����������ڰ�������������ʱ��
30��GC��ʲô��ΪʲôҪ��GC��
��GC�������ռ�����˼���ڴ洦���DZ����Ա���׳�������ĵط������ǻ��ߴ�����ڴ���ջᵼ�³����ϵͳ�IJ��ȶ�����������Java�ṩ��GC���ܿ����Զ��������Ƿ�������Ӷ��ﵽ�Զ������ڴ��Ŀ�ģ�Java����û���ṩ�ͷ��ѷ����ڴ����ʾ����������Java����Ա���õ����ڴ��������Ϊ�����ռ������Զ����й�����Ҫ���������ռ������Ե�������ķ���֮һ��System.gc() ��Runtime.getRuntime().gc() ����JVM�������ε���ʾ���������յ��á�
�������տ�����Ч�ķ�ֹ�ڴ�й¶����Ч��ʹ�ÿ���ʹ�õ��ڴ档����������ͨ������Ϊһ�������ĵ����ȼ����߳����У�����Ԥ֪������¶��ڴ�����Ѿ������Ļ��߳�ʱ��û��ʹ�õĶ����������ͻ��գ�����Ա����ʵʱ�ĵ���������������ij����������ж�������������ա���Java�������ڣ�����������Java��������֮һ����Ϊ�������˵ı����Ҫ��Ч�ķ�ֹ�ڴ�й¶���⣬Ȼ��ʱ����Ǩ�����Java���������ջ����Ѿ���Ϊ��ڸ���Ķ������ƶ������ն��û�ͨ������iOS��ϵͳ��Androidϵͳ�и��õ��û����飬����һ�����ε�ԭ�������Androidϵͳ���������յIJ���Ԥ֪�ԡ�
���䣺�������ջ����кܶ��֣��������ִ������������ա�����������ա������������յȷ�ʽ������Java���̼���ջ���жѡ�ջ������ԭʼ�;ֲ��������ѱ�����Ҫ�����Ķ���Javaƽ̨�Զ��ڴ���պ������õĻ����㷨����Ϊ��Ǻ����������Java��������˸Ľ������á��ִ�ʽ�����ռ��������ַ������Java������������ڽ����ڴ滮��Ϊ��ͬ�������������ռ������У����ܻὫ�����ƶ�����ͬ����
- ������Eden�������Ƕ�����������������ҶԴ����������˵������������Ψһ���ڹ�������
- �Ҵ�������Survivor�����������Ҵ������Ķ���ᱻŲ�����
- ����������Tenured���������㹻�ϵ��Ҵ����Ĺ��ޡ�������ռ���Minor-GC�������Dz��ᴥ������ط��ġ���������ռ����ܰѶ���Ž���������ʱ���ͻᴥ��һ����ȫ�ռ���Major-GC����������ܻ���ǣ����ѹ�����Ա�Ϊ������ڳ��㹻�Ŀռ䡣
������������ص�JVM������
- -Xms / -Xmx �� �ѵij�ʼ��С / �ѵ�����С
- -Xmn �� ����������Ĵ�С
- -XX:-DisableExplicitGC �� ��System.gc()�����������
- -XX:+PrintGCDetails �� ��ӡGC��ϸ��
- -XX:+PrintGCDateStamps �� ��ӡGC������ʱ���
- -XX:NewSize / XX:MaxNewSize �� ������������С/����������С
- -XX:NewRatio �� �����������������������ı���
- -XX:PrintTenuringDistribution �� ����ÿ��������GC������Ҵ������ж�������ķֲ�
- -XX:InitialTenuringThreshold / -XX:MaxTenuringThreshold�������������ֵ�ij�ʼֵ�����ֵ
- -XX:TargetSurvivorRatio�������Ҵ�����Ŀ��ʹ����
31��String s = new String("xyz");�����˼����ַ�������
����������һ���Ǿ�̬����"xyz"��һ������new�����ڶ��ϵĶ���
32���ӿ��Ƿ�ɼ̳У�extends���ӿڣ��������Ƿ��ʵ�֣�implements���ӿڣ��������Ƿ�ɼ̳о����ࣨconcrete class����
�𣺽ӿڿ��Լ̳нӿڣ�����֧�ֶ��ؼ̳С����������ʵ��(implements)�ӿڣ�������ɼ̳о�����Ҳ���Լ̳г����ࡣ
33��һ��".java"Դ�ļ����Ƿ����������ࣨ�����ڲ��ࣩ����ʲô���ƣ�
�𣺿��ԣ���һ��Դ�ļ������ֻ����һ�������ࣨpublic class�������ļ�������������������ȫ����һ�¡�
34��Anonymous Inner Class(�����ڲ���)�Ƿ���Լ̳������ࣿ�Ƿ����ʵ�ֽӿڣ�
�𣺿��Լ̳��������ʵ�������ӿڣ���Swing��̺�Android�����г��ô˷�ʽ��ʵ���¼������ͻص���
35���ڲ�������������İ����ࣨ�ⲿ�ࣩ�ij�Ա����û��ʲô���ƣ�
��һ���ڲ��������Է��ʴ��������ⲿ�����ij�Ա������˽�г�Ա��
36��Java �е�final�ؼ�������Щ�÷���
��(1)�����ࣺ��ʾ����ܱ��̳У�(2)���η�������ʾ�������ܱ���д��(3)���α�������ʾ����ֻ��һ�θ�ֵ�Ժ�ֵ���ܱ��ģ���������
37��ָ�������������н����
class A { static { System.out.print("1"); } public A() { System.out.print("2"); }}class B extends A{ static { System.out.print("a"); } public B() { System.out.print("b"); }}public class Hello { public static void main(String[] args) { A ab = new B(); ab = new B(); }}��ִ�н����1a2b2b����������ʱ�������ĵ���˳���ǣ��ȳ�ʼ����̬��Ա��Ȼ����ø���������ٳ�ʼ���Ǿ�̬��Ա��������������������
��ʾ��������ܸ����������ȷ�𰸣�˵��֮ǰ��21��Java����ػ��ƻ�û����ȫ���⣬�Ͻ��ٿ����ɡ�
38����������֮���ת����
- ��ν��ַ���ת��Ϊ�����������ͣ�
- ��ν�������������ת��Ϊ�ַ�����
��
- ���û����������Ͷ�Ӧ�İ�װ���еķ���parseXXX(String)��valueOf(String)���ɷ�����Ӧ�������ͣ�
- һ�ַ����ǽ�����������������ַ�����""�����ӣ�+�����ɻ��������Ӧ���ַ�������һ�ַ����ǵ���String ���е�valueOf()����������Ӧ�ַ���
39�����ʵ���ַ����ķ�ת���滻��
�𣺷����ܶ࣬�����Լ�дʵ��Ҳ����ʹ��String��StringBuffer/StringBuilder�еķ�������һ���ܳ��������������õݹ�ʵ���ַ�����ת������������ʾ��
public static String reverse(String originStr) { if(originStr == null || originStr.length() <= 1) return originStr; return reverse(originStr.substring(1)) + originStr.charAt(0); }40��������GB2312������ַ���ת��ΪISO-8859-1������ַ�����
�𣺴���������ʾ��
String s1 = "���";String s2 = new String(s1.getBytes("GB2312"), "ISO-8859-1");41�����ں�ʱ�䣺
- ���ȡ�������ա�Сʱ�����룿
- ���ȡ�ô�1970��1��1��0ʱ0��0�뵽���ڵĺ�������
- ���ȡ��ij�µ����һ�죿
- ��θ�ʽ�����ڣ�
��
����1������java.util.Calendar ʵ����������get()�������벻ͬ�IJ������ɻ�ò�������Ӧ��ֵ��Java 8�п���ʹ��java.time.LocalDateTimel����ȡ������������ʾ��
public class DateTimeTest { public static void main(String[] args) { Calendar cal = Calendar.getInstance(); System.out.println(cal.get(Calendar.YEAR)); System.out.println(cal.get(Calendar.MONTH)); // 0 - 11 System.out.println(cal.get(Calendar.DATE)); System.out.println(cal.get(Calendar.HOUR_OF_DAY)); System.out.println(cal.get(Calendar.MINUTE)); System.out.println(cal.get(Calendar.SECOND)); // Java 8 LocalDateTime dt = LocalDateTime.now(); System.out.println(dt.getYear()); System.out.println(dt.getMonthValue()); // 1 - 12 System.out.println(dt.getDayOfMonth()); System.out.println(dt.getHour()); System.out.println(dt.getMinute()); System.out.println(dt.getSecond()); }}����2�����·������ɻ�øú�������
Calendar.getInstance().getTimeInMillis();System.currentTimeMillis();Clock.systemDefaultZone().millis(); // Java 8����3������������ʾ��
Calendar time = Calendar.getInstance();time.getActualMaximum(Calendar.DAY_OF_MONTH);����4������java.text.DataFormat �����ࣨ��SimpleDateFormat�ࣩ�е�format(Date)�����ɽ����ڸ�ʽ����Java 8�п�����java.time.format.DateTimeFormatter����ʽ��ʱ�����ڣ�����������ʾ��
import java.text.SimpleDateFormat;import java.time.LocalDate;import java.time.format.DateTimeFormatter;import java.util.Date;class DateFormatTest { public static void main(String[] args) { SimpleDateFormat oldFormatter = new SimpleDateFormat("yyyy/MM/dd"); Date date1 = new Date(); System.out.println(oldFormatter.format(date1)); // Java 8 DateTimeFormatter newFormatter = DateTimeFormatter.ofPattern("yyyy/MM/dd"); LocalDate date2 = LocalDate.now(); System.out.println(date2.format(newFormatter)); }}���䣺Java��ʱ������APIһֱ�������DZ�ڸ���Ķ�����Ϊ�˽����һ���⣬Java 8���������µ�ʱ������API�����а���LocalDate��LocalTime��LocalDateTime��Clock��Instant���࣬��Щ�������ƶ�ʹ���˲���ģʽ��������̰߳�ȫ����ơ������������Щ���ݣ����Բο��ҵ���һƪ���¡�����Java������̵��ܽ��˼������
42����ӡ����ĵ�ǰʱ�̡�
��
import java.util.Calendar;class YesterdayCurrent { public static void main(String[] args){ Calendar cal = Calendar.getInstance(); cal.add(Calendar.DATE, -1); System.out.println(cal.getTime()); }}��Java 8�У�����������Ĵ���ʵ����ͬ�Ĺ��ܡ�
import java.time.LocalDateTime;class YesterdayCurrent { public static void main(String[] args) { LocalDateTime today = LocalDateTime.now(); LocalDateTime yesterday = today.minusDays(1); System.out.println(yesterday); }}43���Ƚ�һ��Java��JavaSciprt��
��JavaScript ��Java��������˾�����IJ�ͬ��������Ʒ��Java ��ԭSun Microsystems��˾�Ƴ����������ij���������ԣ��ر��ʺ��ڻ�����Ӧ�ó�������JavaScript��Netscape��˾�IJ�Ʒ��Ϊ����չNetscape������Ĺ��ܶ�������һ�ֿ���Ƕ��Webҳ�������еĻ��ڶ�����¼������Ľ��������ԡ�JavaScript��ǰ����LiveScript����Java��ǰ����Oak���ԡ�
������������Լ����ͬ�����±Ƚϣ�
- ���ڶ�����������Java��һ�������������������ԣ���ʹ�ǿ����ij�������ƶ���JavaScript���ֽű����ԣ����������������������صģ����û��������õĸ�������������һ�ֻ��ڶ���Object-Based�����¼�������Event-Driven���ı�����ԣ�����������ṩ�˷dz��ḻ���ڲ����������Աʹ�á�
- ���ͺͱ��룺Java��Դ������ִ��֮ǰ�����뾭�����롣JavaScript��һ�ֽ����Ա�����ԣ���Դ���벻�辭�����룬�����������ִ�С���Ŀǰ�������������ʹ����JIT����ʱ���룩����������JavaScript������Ч�ʣ�
- ǿ���ͱ�����������������Java����ǿ���ͱ�����飬�����б����ڱ���֮ǰ������������JavaScript�б����������͵ģ�������ʹ�ñ���ǰ���Բ���������JavaScript�Ľ�����������ʱ����ƶ����������͡�
- �����ʽ��һ����
���䣺�����г����ĵ���������������ν�ı��𰸡���ʵJava��JavaScript����Ҫ��������һ���Ǿ�̬���ԣ�һ���Ƕ�̬���ԡ�Ŀǰ�ı�����Եķ�չ�����Ǻ���ʽ���ԺͶ�̬���ԡ���Java���ࣨclass����һ�ȹ���JavaScript�к�����function����һ�ȹ������JavaScript֧�ֺ���ʽ��̣�����ʹ��Lambda�����ͱհ���closure������ȻJava 8Ҳ��ʼ֧�ֺ���ʽ��̣��ṩ�˶�Lambda����ʽ�Լ�����ʽ�ӿڵ�֧�֡������������⣬�����Ե�ʱ����û������Լ������Իش����ӿ��ף���Ҫ��������ν�ı��𰸡�
44��ʲôʱ���ö��ԣ�assert����
�𣺶�����������������һ�ֳ��õĵ��Է�ʽ���ܶ�������ж�֧�����ֻ��ơ�һ����˵���������ڱ�֤������������ؼ�����ȷ�ԡ����Լ��ͨ���ڿ����Ͳ���ʱ������Ϊ�˱�֤�����ִ��Ч�ʣ���������������Լ��ͨ���ǹرյġ�������һ��������������ʽ����䣬��ִ��������ʱ�ٶ��ñ���ʽΪtrue���������ʽ��ֵΪfalse����ôϵͳ�ᱨ��һ��AssertionError�����Ե�ʹ��������Ĵ�����ʾ��
assert(a > 0); // throws an AssertionError if a <= 0���Կ�����������ʽ��
assert Expression1;
assert Expression1 : Expression2 ;
Expression1 Ӧ�����Dz���һ������ֵ��
Expression2 �����ǵó�һ��ֵ���������ʽ�����ֵ����������ʾ���������Ϣ���ַ�����Ϣ��
Ҫ������ʱ���ö��ԣ�����������JVMʱʹ��-enableassertions����-ea��ǡ�Ҫ������ʱѡ����ö��ԣ�����������JVMʱʹ��-da����-disableassertions��ǡ�Ҫ��ϵͳ�������û���ö��ԣ���ʹ��-esa��-dsa��ǡ��������ڰ��Ļ��������û��߽��ö��ԡ�
ע�⣺���Բ�Ӧ�����κη�ʽ�ı�����״̬����˵�����ϣ���ڲ�����ijЩ����ʱ��ֹ�����ִ�У��Ϳ��Կ����ö�������ֹ����
45��Error��Exception��ʲô����
��Error��ʾϵͳ���Ĵ���ͳ��ش������쳣���ǻָ����Dz����ܵ������ѵ�����µ�һ���������⣻�����ڴ������������ָ�������ܴ��������������Exception��ʾ��Ҫ��������Ҫ������д������쳣����һ����ƻ�ʵ�����⣻Ҳ����˵������ʾ������������������Ӳ��ᷢ���������
�����⣺2005��Ħ�������������������ʹ���ôһ�����⡰If a process reports a stack overflow run-time error, what��s the most possible cause?���������ĸ�ѡ��a. lack of memory; b. write on an invalid memory space; c. recursive function calling; d. array index out of boundary. Java����������ʱҲ���ܻ�����StackOverflowError������һ�����ָ��Ĵ���ֻ�������Ĵ����ˣ����������Ĵ���c�����д�˲���Ѹ�������ĵݹ飬����п�������ջ����Ĵ���������ʾ��
class StackOverflowErrorTest { public static void main(String[] args) { main(null); }}��ʾ���õݹ��д����ʱһ��Ҫ�μ����㣺1. �ݹ鹫ʽ��2. ����������ʲôʱ��Ͳ��ټ����ݹ飩��
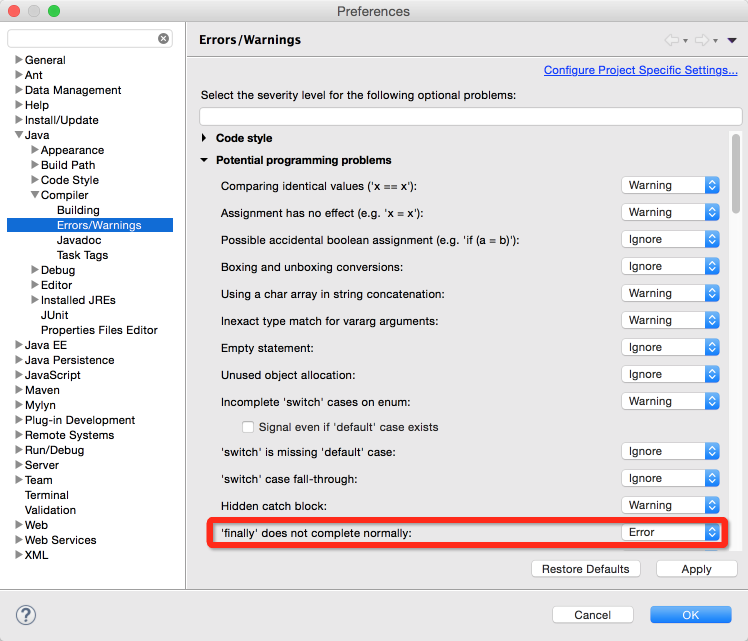
46��try{}����һ��return��䣬��ô���������try���finally{}��Ĵ����ᱻִ�У�ʲôʱ��ִ�У���returnǰ���Ǻ�?
�𣺻�ִ�У��ڷ������ص�����ǰִ�С�
ע�⣺��finally�иı䷵��ֵ�������Dz��õģ���Ϊ�������finally����飬try�е�return��䲻���������ص����ߣ����Ǽ�¼�·���ֵ��finally�����ִ�����֮����������߷�����ֵ��Ȼ�������finally�����˷���ֵ���ͻ᷵���ĺ��ֵ����Ȼ����finally�з��ػ����ķ���ֵ��Գ�����ɺܴ�����ţ�C#��ֱ���ñ������ķ�ʽ����ֹ����Ա���������������飬Java��Ҳ����ͨ�����������������鼶����������������Eclipse�п�������ͼ��ʾ�ĵط��������ã�ǿ�ҽ��齫��������Ϊ�������
47��Java������ν����쳣�������ؼ��֣�throws��throw��try��catch��finally�ֱ����ʹ�ã�
��Javaͨ���������ķ��������쳣�������Ѹ��ֲ�ͬ���쳣���з��࣬���ṩ�����õĽӿڡ���Java�У�ÿ���쳣����һ����������Throwable����������ʵ������һ�����������쳣����׳�һ���쳣���ö����а������쳣��Ϣ�������������ķ������Բ�������쳣�����Զ�����д�����Java���쳣������ͨ��5���ؼ�����ʵ�ֵģ�try��catch��throw��throws��finally��һ�����������try��ִ��һ�γ������ϵͳ���׳���throw��һ���쳣������ͨ����������������catch��������ͨ������ִ�д���飨finally����������try����ָ��һ��Ԥ�������쳣�ij���catch�Ӿ������try����棬����ָ������Ҫ������쳣�����ͣ�throw���������ȷ���׳�һ���쳣��throws��������һ�����������׳��ĸ����쳣����Ȼ�����쳣ʱ��������������finallyΪȷ��һ�δ��벻�ܷ���ʲô�쳣״����Ҫ��ִ�У�try������Ƕ�ף�ÿ������һ��try��䣬�쳣�Ľṹ�ͻᱻ�����쳣ջ�У�ֱ�����е�try��䶼��ɡ������һ����try���û�ж�ij���쳣���д������쳣ջ�ͻ�ִ�г�ջ������ֱ�������д��������쳣��try���������ս��쳣��JVM��
48������ʱ�쳣���ܼ��쳣�к���ͬ��
���쳣��ʾ�������й����п��ܳ��ֵķ�����״̬������ʱ�쳣��ʾ�������ͨ�������п����������쳣����һ�ֳ������д���ֻҪ������Ƶ�û������ͨ���Ͳ��ᷢ�����ܼ��쳣���������е������Ļ����йأ���ʹ�������������Ȼ������ʹ�õ������������Java������Ҫ�����������׳����ܷ������ܼ��쳣�����Dz���Ҫ����������׳�δ�����������ʱ�쳣���쳣�ͼ̳�һ��������������������о��������õĶ�������Effective Java�ж��쳣��ʹ������������ָ��ԭ��
- ��Ҫ���쳣�������������Ŀ�������������õ�API��Ӧ��ǿ�����ĵ�����Ϊ�������Ŀ�������ʹ���쳣��
- �Կ��Իָ������ʹ���ܼ��쳣���Ա�̴���ʹ������ʱ�쳣
- ���ⲻ��Ҫ��ʹ���ܼ��쳣������ͨ��һЩ״̬����ֶ��������쳣�ķ�����
- ����ʹ�ñ����쳣
- ÿ�������׳����쳣��Ҫ���ĵ�
- �����쳣��ԭ����
- ��Ҫ��catch�к��Ե������쳣
49���г�һЩ�㳣��������ʱ�쳣��
��
- ArithmeticException�������쳣��
- ClassCastException ����ת���쳣��
- IllegalArgumentException ���Ƿ������쳣��
- IndexOutOfBoundsException ���±�Խ���쳣��
- NullPointerException ����ָ���쳣��
- SecurityException ����ȫ�쳣��
50������final��finally��finalize������
��
- final�����η����ؼ��֣��������÷������һ���౻����Ϊfinal����ζ�����������������µ����࣬�����ܱ��̳У��������abstract�Ƿ���ʡ�����������Ϊfinal�����Ա�֤������ʹ���в����ı䣬������Ϊfinal�ı�������������ʱ������ֵ�������Ժ��������ֻ�ܶ�ȡ�����ġ�������Ϊfinal�ķ���Ҳͬ��ֻ��ʹ�ã������������б���д��
- finally��ͨ������try��catch���ĺ��湹������ִ�д���飬�����ζ�ų�����������ִ�л��Ƿ����쳣������Ĵ���ֻҪJVM���رն���ִ�У����Խ��ͷ��ⲿ��Դ�Ĵ���д��finally���С�
- finalize��Object���ж���ķ�����Java������ʹ��finalize()�����������ռ�����������ڴ��������ȥ֮ǰ����Ҫ����������������������������ռ��������ٶ���ʱ���õģ�ͨ����дfinalize()������������ϵͳ��Դ����ִ����������������
51����ExampleA�̳�Exception����ExampleB�̳�ExampleA��
�����´���Ƭ�ϣ�
try { throw new ExampleB("b")} catch��ExampleA e��{ System.out.println("ExampleA");} catch��Exception e��{ System.out.println("Exception");}����ִ�д˶δ���������ʲô��
�������ExampleA�����������ϴ���ԭ��[��ʹ�ø����͵ĵط�һ����ʹ��������]��ץȡExampleA�����쳣��catch���ܹ�ץסtry�����׳���ExampleB���͵��쳣��
������ - ˵�������������н����������ij����ǡ�Java���˼�롷һ�飩
class Annoyance extends Exception {}class Sneeze extends Annoyance {}class Human { public static void main(String[] args) throws Exception { try { try { throw new Sneeze(); } catch ( Annoyance a ) { System.out.println("Caught Annoyance"); throw a; } } catch ( Sneeze s ) { System.out.println("Caught Sneeze"); return ; } finally { System.out.println("Hello World!"); } }}52��List��Set��Map�Ƿ�̳���Collection�ӿڣ�
��List��Set �ǣ�Map ���ǡ�Map�Ǽ�ֵ��ӳ����������List��Set�����Ե����𣬶�Set�洢����ɢ��Ԫ���Ҳ��������ظ�Ԫ�أ���ѧ�еļ���Ҳ����ˣ���List�����Խṹ�������������ڰ���ֵ��������Ԫ�ص����Ρ�
53������ArrayList��Vector��LinkedList�Ĵ洢���ܺ����ԡ�
��ArrayList ��Vector����ʹ�����鷽ʽ�洢���ݣ�������Ԫ��������ʵ�ʴ洢�������Ա����ӺͲ���Ԫ�أ����Ƕ�����ֱ�Ӱ��������Ԫ�أ����Dz���Ԫ��Ҫ�漰����Ԫ���ƶ����ڴ�����������������ݿ��������������Vector�еķ�������������synchronized���Σ����Vector���̰߳�ȫ���������������Ͻ�ArrayList�����Ѿ���Java�е�����������LinkedListʹ��˫������ʵ�ִ洢�����ڴ�����ɢ���ڴ浥Ԫͨ�����ӵ����ù����������γ�һ������������������Խṹ��������ʽ�洢��ʽ������������洢��ʽ��ȣ��ڴ�������ʸ��ߣ������������������Ҫ����ǰ��������������Dz�������ʱֻ��Ҫ��¼�����ǰ����ɣ����Բ����ٶȽϿ졣Vector��������������Java���ڵİ汾���ṩ������������֮�⣬Hashtable��Dictionary��BitSet��Stack��Properties�����������������Ѿ����Ƽ�ʹ�ã���������ArrayList��LinkedListed���Ƿ��̰߳�ȫ�ģ������������̲߳���ͬһ�������ij����������ͨ��������Collections�е�synchronizedList��������ת�����̰߳�ȫ����������ʹ�ã����Ƕ�װ��ģʽ��Ӧ�ã������ж�������һ����Ĺ������д����µĶ�������ǿʵ�֣���
���䣺���������е�Properties���Stack��������������ص����⣬Properties��һ������ֵ�����ַ���������ļ�ֵ��ӳ�䣬�������Ӧ���ǹ���һ��Hashtable�������������Ͳ�������ΪString���ͣ�����Java API�е�Propertiesֱ�Ӽ̳���Hashtable����������ǶԼ̳е����á����︴�ô���ķ�ʽӦ����Has-A��ϵ������Is-A��ϵ����һ�������������ڹ����࣬�̳й����౾������һ�������������ʹ�ù�������õķ�ʽ��Has-A��ϵ����������Use-A��ϵ����������ͬ����Stack��̳�VectorҲ�Dz���ȷ�ġ�Sun��˾�Ĺ���ʦ��Ҳ�᷸���ֵͼ������������겻�ѡ�
54��Collection��Collections������
��Collection��һ���ӿڣ�����Set��List�������ĸ��ӿڣ�Collections�Ǹ�һ�������࣬�ṩ��һϵ�еľ�̬����������������������Щ���������������������������̰߳�ȫ���ȵȡ�
55��List��Map��Set�����ӿڴ�ȡԪ��ʱ������ʲô�ص㣿
��List���ض���������ȡԪ�أ��������ظ�Ԫ�ء�Set���ܴ���ظ�Ԫ�أ��ö����equals()����������Ԫ���Ƿ��ظ�����Map�����ֵ�ԣ�key-value pair��ӳ�䣬ӳ���ϵ������һ��һ����һ��Set��Map�������л��ڹ�ϣ�洢��������������ʵ�ְ汾�����ڹ�ϣ�洢�İ汾���۴�ȡʱ�临�Ӷ�ΪO(1)���������������汾��ʵ���ڲ����ɾ��Ԫ��ʱ�ᰴ��Ԫ�ػ�Ԫ�صļ���key�������������Ӷ��ﵽ�����ȥ�ص�Ч����
56��TreeMap��TreeSet������ʱ��αȽ�Ԫ�أ�Collections�������е�sort()������αȽ�Ԫ�أ�
��TreeSetҪ���ŵĶ��������������ʵ��Comparable�ӿڣ��ýӿ��ṩ�˱Ƚ�Ԫ�ص�compareTo()������������Ԫ��ʱ��ص��÷����Ƚ�Ԫ�صĴ�С��TreeMapҪ���ŵļ�ֵ��ӳ��ļ�����ʵ��Comparable�ӿڴӶ����ݼ���Ԫ�ؽ�������Collections�������sort�������������ص���ʽ����һ��Ҫ����Ĵ����������д�ŵĶ���Ƚ�ʵ��Comparable�ӿ���ʵ��Ԫ�صıȽϣ��ڶ��ֲ�ǿ���Ե�Ҫ�������е�Ԫ�ر���ɱȽϣ�����Ҫ����ڶ���������������Comparator�ӿڵ������ͣ���Ҫ��дcompare����ʵ��Ԫ�صıȽϣ����൱��һ����ʱ��������������ʵ����ͨ���ӿ�ע��Ƚ�Ԫ�ش�С���㷨��Ҳ�ǶԻص�ģʽ��Ӧ�ã�Java�жԺ���ʽ��̵�֧�֣���
����1��
public class Student implements Comparable<Student> { private String name; // ���� private int age; // ���� public Student(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Student [name=" + name + ", age=" + age + "]"; } @Override public int compareTo(Student o) { return this.age - o.age; // �Ƚ�����(���������) }}import java.util.Set;import java.util.TreeSet;class Test01 { public static void main(String[] args) { Set<Student> set = new TreeSet<>(); // Java 7����ʯ�(����������ļ������в���Ҫд����) set.add(new Student("Hao LUO", 33)); set.add(new Student("XJ WANG", 32)); set.add(new Student("Bruce LEE", 60)); set.add(new Student("Bob YANG", 22)); for(Student stu : set) { System.out.println(stu); }// ������: // Student [name=Bob YANG, age=22]// Student [name=XJ WANG, age=32]// Student [name=Hao LUO, age=33]// Student [name=Bruce LEE, age=60] }}����2��
public class Student { private String name; // ���� private int age; // ���� public Student(String name, int age) { this.name = name; this.age = age; } /** * ��ȡѧ������ */ public String getName() { return name; } /** * ��ȡѧ������ */ public int getAge() { return age; } @Override public String toString() { return "Student [name=" + name + ", age=" + age + "]"; }}import java.util.ArrayList;import java.util.Collections;import java.util.Comparator;import java.util.List;class Test02 { public static void main(String[] args) { List<Student> list = new ArrayList<>(); // Java 7����ʯ�(����������ļ������в���Ҫд����) list.add(new Student("Hao LUO", 33)); list.add(new Student("XJ WANG", 32)); list.add(new Student("Bruce LEE", 60)); list.add(new Student("Bob YANG", 22)); // ͨ��sort�����ĵڶ�����������һ��Comparator�ӿڶ��� // �൱���Ǵ���һ���Ƚ϶����С���㷨��sort������ // ����Java��û�к���ָ�롢�º�����ί�������ĸ��� // ���Ҫ��һ���㷨����һ��������Ψһ��ѡ�����ͨ���ӿڻص� Collections.sort(list, new Comparator<Student> () { @Override public int compare(Student o1, Student o2) { return o1.getName().compareTo(o2.getName()); // �Ƚ�ѧ������ } }); for(Student stu : list) { System.out.println(stu); }// ������: // Student [name=Bob YANG, age=22]// Student [name=Bruce LEE, age=60]// Student [name=Hao LUO, age=33]// Student [name=XJ WANG, age=32] }}57��Thread���sleep()�����Ͷ����wait()�������������߳���ִͣ�У�������ʲô����?
��sleep()���������ߣ����߳��ࣨThread���ľ�̬���������ô˷������õ�ǰ�߳���ִͣ��ָ����ʱ�䣬��ִ�л��ᣨCPU���ø������̣߳����Ƕ��������Ȼ���֣��������ʱ���������Զ��ָ����̻߳ص�����״̬����ο���66���е��߳�״̬ת��ͼ����wait()��Object��ķ��������ö����wait()�������µ�ǰ�̷߳�������������߳���ִͣ�У����������ĵȴ��أ�wait pool����ֻ�е��ö����notify()��������notifyAll()������ʱ���ܻ��ѵȴ����е��߳̽�������أ�lock pool��������߳����»�ö�������Ϳ��Խ������״̬��
���䣺���ܲ����˶�ʲô�ǽ��̣�ʲô���̻߳��Ƚ�ģ��������Ϊʲô��Ҫ���̱߳��Ҳ�����ر����⡣��˵�������Ǿ���һ���������ܵij������ij�����ݼ����ϵ�һ�����л���Dz���ϵͳ������Դ����͵��ȵ�һ��������λ���߳��ǽ��̵�һ��ʵ�壬��CPU���Ⱥͷ��ɵĻ�����λ���DZȽ��̸�С���ܶ������еĻ�����λ���̵߳Ļ��ֳ߶�С�ڽ��̣���ʹ�ö��̳߳���IJ����Ըߣ�������ִ��ʱͨ��ӵ�ж������ڴ浥Ԫ�����߳�֮����Թ����ڴ档ʹ�ö��̵߳ı��ͨ���ܹ��������õ����ܺ��û����飬���Ƕ��̵߳ij���������������Dz��Ѻõģ���Ϊ������ռ���˸����CPU��Դ����Ȼ��Ҳ�����߳�Խ�࣬��������ܾ�Խ�ã���Ϊ�߳�֮��ĵ��Ⱥ��л�Ҳ���˷�CPUʱ�䡣ʱ�º�ʱ�ֵ�Node.js�Ͳ����˵��߳��첽I/O�Ĺ���ģʽ��
58���̵߳�sleep()������yield()������ʲô����
��
�� sleep()�����������߳����л���ʱ�������̵߳����ȼ�����˻�������ȼ����߳������еĻ��yield()����ֻ�����ͬ���ȼ���������ȼ����߳������еĻ��
�� �߳�ִ��sleep()������ת��������blocked��״̬����ִ��yield()������ת�������ready��״̬��
�� sleep()���������׳�InterruptedException����yield()����û�������κ��쳣��
�� sleep()������yield()������������ϵͳCPU������أ����и��õĿ���ֲ�ԡ�
59����һ���߳̽���һ�������synchronized����A֮�������߳��Ƿ�ɽ���˶����synchronized����B��
�𣺲��ܡ������߳�ֻ�ܷ��ʸö���ķ�ͬ��������ͬ���������ܽ��롣��Ϊ�Ǿ�̬�����ϵ�synchronized���η�Ҫ��ִ�з���ʱҪ��ö������������Ѿ�����A����˵���������Ѿ���ȡ�ߣ���ô��ͼ����B�������߳̾�ֻ���ڵ����أ�ע�ⲻ�ǵȴ���Ŷ���еȴ����������
60����˵�����߳�ͬ���Լ��̵߳�����صķ�����
��
- wait()��ʹһ���̴߳��ڵȴ���������״̬�������ͷ������еĶ��������
- sleep()��ʹһ���������е��̴߳���˯��״̬����һ����̬���������ô˷���Ҫ����InterruptedException�쳣��
- notify()������һ�����ڵȴ�״̬���̣߳���Ȼ�ڵ��ô˷�����ʱ������ȷ�еĻ���ijһ���ȴ�״̬���̣߳�������JVMȷ�������ĸ��̣߳����������ȼ��أ�
- notityAll()���������д��ڵȴ�״̬���̣߳��÷��������ǽ���������������̣߳����������Ǿ�����ֻ�л�������̲߳��ܽ������״̬��
��ʾ������Java���̺߳Ͳ�����̵����⣬�����ҿ��ҵ���һƪ���¡�����Java������̵��ܽ��˼������
���䣺Java 5ͨ��Lock�ӿ��ṩ����ʽ�������ƣ�explicit lock������ǿ��������Լ����̵߳�Э����Lock�ӿ��ж����˼�����lock()���ͽ�����unlock()���ķ�����ͬʱ���ṩ��newCondition()���������������߳�֮��ͨ�ŵ�Condition�����⣬Java 5���ṩ���ź������ƣ�semaphore�����ź��������������ƶ�ij��������Դ���з��ʵ��̵߳��������ڶ���Դ���з���֮ǰ���̱߳���õ��ź��������ɣ�����Semaphore�����acquire()������������ɶ���Դ�ķ��ʺ��̱߳������ź����黹���ɣ�����Semaphore�����release()��������
�����������ʾ��100���߳�ͬʱ��һ�������˻��д���1ԪǮ����û��ʹ��ͬ�����ƺ�ʹ��ͬ����������µ�ִ�������
- �����˻��ࣺ
/** * �����˻� * @author ��� * */public class Account { private double balance; // �˻���� /** * ��� * @param money ������ */ public void deposit(double money) { double newBalance = balance + money; try { Thread.sleep(10); // ģ���ҵ����Ҫһ�δ���ʱ�� } catch(InterruptedException ex) { ex.printStackTrace(); } balance = newBalance; } /** * ����˻���� */ public double getBalance() { return balance; }}- ��Ǯ�߳��ࣺ
/** * ��Ǯ�߳� * @author ��� * */public class AddMoneyThread implements Runnable { private Account account; // �����˻� private double money; // ������ public AddMoneyThread(Account account, double money) { this.account = account; this.money = money; } @Override public void run() { account.deposit(money); }}- �����ࣺ
import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;public class Test01 { public static void main(String[] args) { Account account = new Account(); ExecutorService service = Executors.newFixedThreadPool(100); for(int i = 1; i <= 100; i++) { service.execute(new AddMoneyThread(account, 1)); } service.shutdown(); while(!service.isTerminated()) {} System.out.println("�˻����: " + account.getBalance()); }}��û��ͬ��������£�ִ�н��ͨ������ʾ�˻������10Ԫ���£���������״����ԭ���ǣ���һ���߳�A��ͼ����1Ԫ��ʱ������һ���߳�BҲ�ܹ�������ķ����У��߳�B��ȡ�����˻������Ȼ���߳�A����1ԪǮ֮ǰ���˻������Ҳ����ԭ�������0�������˼�1Ԫ�IJ�����ͬ���߳�CҲ�������Ƶ����飬�������100���߳�ִ�н���ʱ�����������˻����Ϊ100Ԫ����ʵ�ʵõ���ͨ����10Ԫ���£��ܿ�����1ԪŶ��������������İ취����ͬ������һ���̶߳������˻���Ǯʱ����Ҫ�����˻����������������ɺ�������������߳̽��в��������������¼��ֵ���������
- �������˻��Ĵ�deposit��������ͬ����synchronized���ؼ���
/** * �����˻� * @author ��� * */public class Account { private double balance; // �˻���� /** * ��� * @param money ������ */ public synchronized void deposit(double money) { double newBalance = balance + money; try { Thread.sleep(10); // ģ���ҵ����Ҫһ�δ���ʱ�� } catch(InterruptedException ex) { ex.printStackTrace(); } balance = newBalance; } /** * ����˻���� */ public double getBalance() { return balance; }}- ���̵߳��ô���ʱ�������˻�����ͬ��
/** * ��Ǯ�߳� * @author ��� * */public class AddMoneyThread implements Runnable { private Account account; // �����˻� private double money; // ������ public AddMoneyThread(Account account, double money) { this.account = account; this.money = money; } @Override public void run() { synchronized (account) { account.deposit(money); } }}- ͨ��Java 5��ʾ�������ƣ�Ϊÿ�������˻�����һ���������ڴ��������м����ͽ����IJ���
import java.util.concurrent.locks.Lock;import java.util.concurrent.locks.ReentrantLock;/** * �����˻� * * @author ��� * */public class Account { private Lock accountLock = new ReentrantLock(); private double balance; // �˻���� /** * ��� * * @param money * ������ */ public void deposit(double money) { accountLock.lock(); try { double newBalance = balance + money; try { Thread.sleep(10); // ģ���ҵ����Ҫһ�δ���ʱ�� } catch (InterruptedException ex) { ex.printStackTrace(); } balance = newBalance; } finally { accountLock.unlock(); } } /** * ����˻���� */ public double getBalance() { return balance; }}�����������ַ�ʽ�Դ�������ĺ���дִ�в��Դ���Test01�����������յ��˻����Ϊ100Ԫ����ȻҲ����ʹ��Semaphore��CountdownLatch��ʵ��ͬ����
61����д���̳߳����м���ʵ�ַ�ʽ��
��Java 5��ǰʵ�ֶ��߳�������ʵ�ַ�����һ���Ǽ̳�Thread�ࣻ��һ����ʵ��Runnable�ӿڡ����ַ�ʽ��Ҫͨ����дrun()�����������̵߳���Ϊ���Ƽ�ʹ�ú��ߣ���ΪJava�еļ̳��ǵ��̳У�һ������һ�����࣬����̳���Thread������ټ̳��������ˣ���Ȼʹ��Runnable�ӿڸ�Ϊ��
���䣺Java 5�Ժ��̻߳��е����ַ�ʽ��ʵ��Callable�ӿڣ��ýӿ��е�call�����������߳�ִ�н���ʱ����һ������ֵ������������ʾ��
import java.util.ArrayList;import java.util.List;import java.util.concurrent.Callable;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.Future;class MyTask implements Callable<Integer> { private int upperBounds; public MyTask(int upperBounds) { this.upperBounds = upperBounds; } @Override public Integer call() throws Exception { int sum = 0; for(int i = 1; i <= upperBounds; i++) { sum += i; } return sum; }}class Test { public static void main(String[] args) throws Exception { List<Future<Integer>> list = new ArrayList<>(); ExecutorService service = Executors.newFixedThreadPool(10); for(int i = 0; i < 10; i++) { list.add(service.submit(new MyTask((int) (Math.random() * 100)))); } int sum = 0; for(Future<Integer> future : list) { // while(!future.isDone()) ; sum += future.get(); } System.out.println(sum); }}62��synchronized�ؼ��ֵ��÷���
��synchronized�ؼ��ֿ��Խ�������߷������Ϊͬ������ʵ�ֶԶ���ͷ����Ļ�����ʣ�������synchronized(����) { �� }����ͬ������飬��������������ʱ��synchronized��Ϊ���������η����ڵ�60����������Ѿ�չʾ��synchronized�ؼ��ֵ��÷���
63������˵��ͬ�����첽��
�����ϵͳ�д����ٽ���Դ����Դ�������ھ�����Դ���߳���������Դ������������д�������Ժ���ܱ���һ���̶߳������������ڶ������ݿ����Ѿ�����һ���߳�д���ˣ���ô��Щ���ݾͱ������ͬ����ȡ�����ݿ�����е�������������õ����ӣ�����Ӧ�ó����ڶ����ϵ�����һ����Ҫ���Ѻܳ�ʱ����ִ�еķ��������Ҳ�ϣ���ó���ȴ������ķ���ʱ����Ӧ��ʹ���첽��̣��ںܶ�����²����첽;����������Ч�ʡ���ʵ�ϣ���ν��ͬ������ָ����ʽ���������첽���Ƿ�����ʽ������
64������һ���߳��ǵ���run()����start()������
������һ���߳��ǵ���start()������ʹ�߳�������������������ڿ�����״̬������ζ����������JVM ���Ȳ�ִ�У��Ⲣ����ζ���߳̾ͻ��������С�run()�������߳�������Ҫ���лص���callback���ķ�����
65��ʲô���̳߳أ�thread pool����
��������������У����������ٶ����Ǻܷ�ʱ��ģ���Ϊ����һ������Ҫ��ȡ�ڴ���Դ��������������Դ����Java�и�����ˣ����������ͼ����ÿһ�������Ա��ܹ��ڶ������ٺ�����������ա�������߷������Ч�ʵ�һ���ֶξ��Ǿ����ܼ��ٴ��������ٶ���Ĵ������ر���һЩ�ܺ���Դ�Ķ��������٣�����ǡ��ػ���Դ������������ԭ���̳߳ع���˼��������ȴ������ɸ���ִ�е��̷߳���һ���أ��������У���Ҫ��ʱ��ӳ��л�ȡ�̲߳������д�����ʹ����ϲ���Ҫ�����̶߳��ǷŻس��У��Ӷ����ٴ����������̶߳���Ŀ�����
Java 5+�е�Executor�ӿڶ���һ��ִ���̵߳Ĺ��ߡ����������ͼ��̳߳ؽӿ���ExecutorService��Ҫ����һ���̳߳��DZȽϸ��ӵģ������Ƕ����̳߳ص�ԭ�����Ǻ����������£�����ڹ�����Executors���ṩ��һЩ��̬��������������һЩ���õ��̳߳أ�������ʾ��
- newSingleThreadExecutor������һ�����̵߳��̳߳ء�����̳߳�ֻ��һ���߳��ڹ�����Ҳ�����൱�ڵ��̴߳���ִ����������������Ψһ���߳���Ϊ�쳣��������ô����һ���µ��߳�������������̳߳ر�֤���������ִ��˳����������ύ˳��ִ�С�
- newFixedThreadPool�������̶���С���̳߳ء�ÿ���ύһ������ʹ���һ���̣߳�ֱ���̴߳ﵽ�̳߳ص�����С���̳߳صĴ�Сһ���ﵽ���ֵ�ͻᱣ�ֲ��䣬���ij���߳���Ϊִ���쳣����������ô�̳߳ػᲹ��һ�����̡߳�
- newCachedThreadPool������һ���ɻ�����̳߳ء�����̳߳صĴ�С�����˴�����������Ҫ���̣߳���ô�ͻ���ղ��ֿ��У�60�벻ִ�������̣߳�������������ʱ�����̳߳��ֿ������ܵ��������߳������������̳߳ز�����̳߳ش�С�����ƣ��̳߳ش�С��ȫ�����ڲ���ϵͳ������˵JVM���ܹ�����������̴߳�С��
- newScheduledThreadPool������һ����С�����̳߳ء����̳߳�֧�ֶ�ʱ�Լ�������ִ�����������
- newSingleThreadExecutor������һ�����̵߳��̳߳ء����̳߳�֧�ֶ�ʱ�Լ�������ִ�����������
��60�����������ʾ��ͨ��Executors�����ഴ���̳߳ز�ʹ���̳߳�ִ���̵߳Ĵ��롣���ϣ���ڷ�������ʹ���̳߳أ�ǿ�ҽ���ʹ��newFixedThreadPool�����������̳߳أ������ܻ�ø��õ����ܡ�
66���̵߳Ļ���״̬�Լ�״̬֮��Ĺ�ϵ��
�� 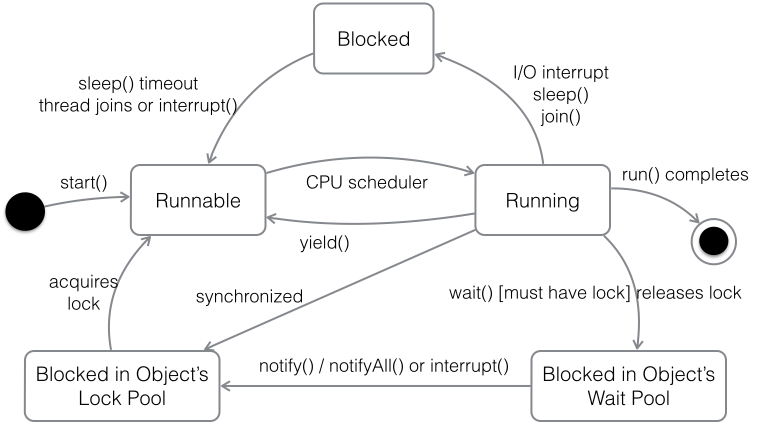
˵��������Running��ʾ����״̬��Runnable��ʾ����״̬�����¾㱸��ֻǷCPU����Blocked��ʾ����״̬������״̬���ж����������������Ϊ����wait()��������ȴ��أ�Ҳ������ִ��ͬ��������ͬ��������������أ������ǵ�����sleep()������join()�����ȴ����������߳̽�����������Ϊ������I/O�жϡ�
67������synchronized ��java.util.concurrent.locks.Lock����ͬ��
��Lock��Java 5�Ժ�������µ�API���ؼ���synchronized�����Ҫ��ͬ�㣺Lock �����synchronized��ʵ�ֵ����й��ܣ���Ҫ��ͬ�㣺Lock�б�synchronized����ȷ���߳�������õ����ܣ����Ҳ�ǿ���Ե�Ҫ��һ��Ҫ�������synchronized���Զ��ͷ�������Lockһ��Ҫ�����Ա�ֹ��ͷţ����������finally �����ͷţ������ͷ��ⲿ��Դ����õĵط�����
68��Java�����ʵ�����л�����ʲô���壿
�����л�����һ�����������������Ļ��ƣ���ν������Ҳ���ǽ���������ݽ������������Զ�������Ķ�����ж�д������Ҳ�ɽ�������Ķ�����������֮�䡣���л���Ϊ�˽����������д����ʱ�������������⣨������������л����ܻ����������������⣩��
Ҫʵ�����л�����Ҫ��һ����ʵ��Serializable�ӿڣ��ýӿ���һ����ʶ�Խӿڣ���ע��������ǿɱ����л��ģ�Ȼ��ʹ��һ�������������һ�������������ͨ��writeObject(Object)�����Ϳ��Խ�ʵ�ֶ���д������������״̬���������Ҫ�����л��������һ������������������������Ȼ��ͨ��readObject���������ж�ȡ�������л������ܹ�ʵ�ֶ���ij־û�֮�⣬���ܹ����ڶ������ȿ�¡�����Բο���29�⣩��
69��Java���м������͵�����
���ֽ������ַ������ֽ����̳���InputStream��OutputStream���ַ����̳���Reader��Writer����java.io ���л�������������������Ҫ��Ϊ��������ܺ�ʹ�÷��㡣����Java��I/O��Ҫע��������㣺һ�����ֶԳ��ԣ����������ĶԳ��ԣ��ֽں��ַ��ĶԳ��ԣ��������������ģʽ��������ģʽ��װ��ģʽ��������Java�е�����ͬ��C#������ֻ��һ��ά��һ������
������ - ���ʵ���ļ��������������Ŀ�ڱ��Ե�ʱ�����֣�����Ĵ������������ʵ�ַ�����
import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IOException;import java.io.InputStream;import java.io.OutputStream;import java.nio.ByteBuffer;import java.nio.channels.FileChannel;public final class MyUtil { private MyUtil() { throw new AssertionError(); } public static void fileCopy(String source, String target) throws IOException { try (InputStream in = new FileInputStream(source)) { try (OutputStream out = new FileOutputStream(target)) { byte[] buffer = new byte[4096]; int bytesToRead; while((bytesToRead = in.read(buffer)) != -1) { out.write(buffer, 0, bytesToRead); } } } } public static void fileCopyNIO(String source, String target) throws IOException { try (FileInputStream in = new FileInputStream(source)) { try (FileOutputStream out = new FileOutputStream(target)) { FileChannel inChannel = in.getChannel(); FileChannel outChannel = out.getChannel(); ByteBuffer buffer = ByteBuffer.allocate(4096); while(inChannel.read(buffer) != -1) { buffer.flip(); outChannel.write(buffer); buffer.clear(); } } } }}ע�⣺�����õ�Java 7��TWR��ʹ��TWR����Բ�����finally���ͷ��ⲿ��Դ ���Ӷ��ô���������š�
70��дһ������������һ���ļ�����һ���ַ�����ͳ������ַ���������ļ��г��ֵĴ�����
�𣺴������£�
import java.io.BufferedReader;import java.io.FileReader;public final class MyUtil { // �������еķ������Ǿ�̬��ʽ���ʵ���˽�������˽�в�������������(���Ժ�ϰ��) private MyUtil() { throw new AssertionError(); } /** * ͳ�Ƹ����ļ��и����ַ����ij��ִ��� * * @param filename �ļ��� * @param word �ַ��� * @return �ַ������ļ��г��ֵĴ��� */ public static int countWordInFile(String filename, String word) { int counter = 0; try (FileReader fr = new FileReader(filename)) { try (BufferedReader br = new BufferedReader(fr)) { String line = null; while ((line = br.readLine()) != null) { int index = -1; while (line.length() >= word.length() && (index = line.indexOf(word)) >= 0) { counter++; line = line.substring(index + word.length()); } } } } catch (Exception ex) { ex.printStackTrace(); } return counter; }}71�������Java�����г�һ��Ŀ¼�����е��ļ���
��
���ֻҪ���г���ǰ�ļ����µ��ļ�������������ʾ��
import java.io.File;class Test12 { public static void main(String[] args) { File f = new File("/Users/Hao/Downloads"); for(File temp : f.listFiles()) { if(temp.isFile()) { System.out.println(temp.getName()); } } }}�����Ҫ���ļ��м���չ��������������ʾ��
import java.io.File;class Test12 { public static void main(String[] args) { showDirectory(new File("/Users/Hao/Downloads")); } public static void showDirectory(File f) { _walkDirectory(f, 0); } private static void _walkDirectory(File f, int level) { if(f.isDirectory()) { for(File temp : f.listFiles()) { _walkDirectory(temp, level + 1); } } else { for(int i = 0; i < level - 1; i++) { System.out.print("\t"); } System.out.println(f.getName()); } }}��Java 7�п���ʹ��NIO.2��API����ͬ�������飬����������ʾ��
class ShowFileTest { public static void main(String[] args) throws IOException { Path initPath = Paths.get("/Users/Hao/Downloads"); Files.walkFileTree(initPath, new SimpleFileVisitor<Path>() { @Override public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException { System.out.println(file.getFileName().toString()); return FileVisitResult.CONTINUE; } }); }}72����Java�����ֱ��ʵ��һ�����̵߳Ļ��ԣ�echo����������
��
import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.io.PrintWriter;import java.net.ServerSocket;import java.net.Socket;public class EchoServer { private static final int ECHO_SERVER_PORT = 6789; public static void main(String[] args) { try(ServerSocket server = new ServerSocket(ECHO_SERVER_PORT)) { System.out.println("�������Ѿ�����..."); while(true) { Socket client = server.accept(); new Thread(new ClientHandler(client)).start(); } } catch (IOException e) { e.printStackTrace(); } } private static class ClientHandler implements Runnable { private Socket client; public ClientHandler(Socket client) { this.client = client; } @Override public void run() { try(BufferedReader br = new BufferedReader(new InputStreamReader(client.getInputStream())); PrintWriter pw = new PrintWriter(client.getOutputStream())) { String msg = br.readLine(); System.out.println("�յ�" + client.getInetAddress() + "���͵�: " + msg); pw.println(msg); pw.flush(); } catch(Exception ex) { ex.printStackTrace(); } finally { try { client.close(); } catch (IOException e) { e.printStackTrace(); } } } }}ע�⣺����Ĵ���ʹ����Java 7��TWR������ںܶ��ⲿ��Դ���ӵ�ʵ����AutoCloseable�ӿڣ��������ص��ӿڣ�����˿�������TWR���try������ʱ��ͨ���ص��ķ�ʽ�Զ������ⲿ��Դ���close()������������д�߳���finally����顣���⣬����Ĵ�����һ����̬�ڲ���ʵ���̵߳Ĺ��ܣ�ʹ�ö��߳̿��Ա���һ���û�I/O�������������ж�Ӱ�������û��Է������ķ��ʣ���˵����һ���û����������������������û�����������Ȼ������Ĵ���ʹ���̳߳ؿ��Ի�ø��õ����ܣ���ΪƵ���Ĵ����������߳�����ɵĿ���Ҳ�Dz��ɺ��ӵġ�
������һ�λ��Կͻ��˲��Դ��룺
import java.io.BufferedReader;import java.io.InputStreamReader;import java.io.PrintWriter;import java.net.Socket;import java.util.Scanner;public class EchoClient { public static void main(String[] args) throws Exception { Socket client = new Socket("localhost", 6789); Scanner sc = new Scanner(System.in); System.out.print("����������: "); String msg = sc.nextLine(); sc.close(); PrintWriter pw = new PrintWriter(client.getOutputStream()); pw.println(msg); pw.flush(); BufferedReader br = new BufferedReader(new InputStreamReader(client.getInputStream())); System.out.println(br.readLine()); client.close(); }}���ϣ����NIO�Ķ�·��������ʵ�ַ�����������������ʾ��NIO�IJ�����Ȼ�����˸��õ����ܣ�������Щ�����DZȽϵײ�ģ����ڳ�ѧ����˵������Щ�������⡣
import java.io.IOException;import java.net.InetSocketAddress;import java.nio.ByteBuffer;import java.nio.CharBuffer;import java.nio.channels.SelectionKey;import java.nio.channels.Selector;import java.nio.channels.ServerSocketChannel;import java.nio.channels.SocketChannel;import java.util.Iterator;public class EchoServerNIO { private static final int ECHO_SERVER_PORT = 6789; private static final int ECHO_SERVER_TIMEOUT = 5000; private static final int BUFFER_SIZE = 1024; private static ServerSocketChannel serverChannel = null; private static Selector selector = null; // ��·����ѡ���� private static ByteBuffer buffer = null; // ������ public static void main(String[] args) { init(); listen(); } private static void init() { try { serverChannel = ServerSocketChannel.open(); buffer = ByteBuffer.allocate(BUFFER_SIZE); serverChannel.socket().bind(new InetSocketAddress(ECHO_SERVER_PORT)); serverChannel.configureBlocking(false); selector = Selector.open(); serverChannel.register(selector, SelectionKey.OP_ACCEPT); } catch (Exception e) { throw new RuntimeException(e); } } private static void listen() { while (true) { try { if (selector.select(ECHO_SERVER_TIMEOUT) != 0) { Iterator<SelectionKey> it = selector.selectedKeys().iterator(); while (it.hasNext()) { SelectionKey key = it.next(); it.remove(); handleKey(key); } } } catch (Exception e) { e.printStackTrace(); } } } private static void handleKey(SelectionKey key) throws IOException { SocketChannel channel = null; try { if (key.isAcceptable()) { ServerSocketChannel serverChannel = (ServerSocketChannel) key.channel(); channel = serverChannel.accept(); channel.configureBlocking(false); channel.register(selector, SelectionKey.OP_READ); } else if (key.isReadable()) { channel = (SocketChannel) key.channel(); buffer.clear(); if (channel.read(buffer) > 0) { buffer.flip(); CharBuffer charBuffer = CharsetHelper.decode(buffer); String msg = charBuffer.toString(); System.out.println("�յ�" + channel.getRemoteAddress() + "����Ϣ��" + msg); channel.write(CharsetHelper.encode(CharBuffer.wrap(msg))); } else { channel.close(); } } } catch (Exception e) { e.printStackTrace(); if (channel != null) { channel.close(); } } }}import java.nio.ByteBuffer;import java.nio.CharBuffer;import java.nio.charset.CharacterCodingException;import java.nio.charset.Charset;import java.nio.charset.CharsetDecoder;import java.nio.charset.CharsetEncoder;public final class CharsetHelper { private static final String UTF_8 = "UTF-8"; private static CharsetEncoder encoder = Charset.forName(UTF_8).newEncoder(); private static CharsetDecoder decoder = Charset.forName(UTF_8).newDecoder(); private CharsetHelper() { } public static ByteBuffer encode(CharBuffer in) throws CharacterCodingException{ return encoder.encode(in); } public static CharBuffer decode(ByteBuffer in) throws CharacterCodingException{ return decoder.decode(in); }}73��XML�ĵ������м�����ʽ������֮���кα������𣿽���XML�ĵ����ļ��ַ�ʽ��
��XML�ĵ������ΪDTD��Schema������ʽ�����߶��Ƕ�XML���Լ�����䱾����������Schema����Ҳ��һ��XML�ļ������Ա�XML���������������ҿ���ΪXML���ص����ݶ������ͣ�Լ��������֮DTD��ǿ��XML�Ľ�����Ҫ��DOM���ĵ�����ģ�ͣ�Document Object Model����SAX��Simple API for XML����StAX��Java 6��������µĽ���XML�ķ�ʽ��Streaming API for XML��������DOM���������ļ�ʱ�������½��ķdz������������������DOM���ṹռ�õ��ڴ�϶���ɵģ�����DOM������ʽ�����ڽ����ļ�֮ǰ�������ĵ�װ���ڴ棬�ʺ϶�XML��������ʣ����͵��ÿռ任ȡʱ��IJ��ԣ���SAX���¼������͵�XML������ʽ����˳���ȡXML�ļ�������Ҫһ��ȫ��װ�������ļ������������ļ���ͷ���ĵ����������߱�ǩ��ͷ���ǩ����ʱ�����ᴥ��һ���¼����û�ͨ���¼��ص�����������XML�ļ����ʺ϶�XML��˳����ʣ�����˼�壬StAX���ص�������ϣ�ʵ����StAX������������ʽ�ı������������Ӧ�ó����ܹ���XML��Ϊһ���¼�������������XML��Ϊһ���¼����������뷨������ӱ��SAX�����������ģ�������֮ͬ������StAX����Ӧ�ó���������Щ�¼�������������������ṩ�ڽ���������ʱ�ӽ������н����¼��Ĵ�������
74��������Ŀ����Щ�ط��õ���XML��
��XML����Ҫ�������������棺���ݽ�������Ϣ���á��������ݽ���ʱ��XML�������ñ�ǩ��װ��������Ȼ��ѹ��������ܺ�ͨ�����紫�������ߣ����ս������ѹ�����ٴ�XML�ļ��л�ԭ�����Ϣ���д�����XML�������칹ϵͳ�佻�����ݵ���ʵ����������ܼ����Ѿ���JSON��JavaScript Object Notation��ȡ����֮����Ȼ��Ŀǰ�ܶ�������Ȼʹ��XML���洢������Ϣ�������ںܶ���Ŀ��ͨ��Ҳ�Ὣ��Ϊ������Ϣ��Ӳ����д��XML�ļ��У�Java�ĺܶ���Ҳ����ô���ģ�������Щ��ܶ�ѡ����dom4j��Ϊ����XML�Ĺ��ߣ���ΪSun��˾�Ĺٷ�APIʵ�ڲ���ô���á�
���䣺�����кܶ�ʱ�ֵ���������Sublime���Ѿ���ʼ�������ļ���д��JSON��ʽ�������Ѿ�ǿ�ҵĸ��ܵ�XML����һ���Ҳ����ҵ��������
75������JDBC�������ݿ�IJ��衣
������Ĵ��������ӱ�����Oracle���ݿ�Ϊ������ʾJDBC�������ݿ�IJ��衣
- ����������
Class.forName("oracle.jdbc.driver.OracleDriver");- �������ӡ�
Connection con = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:orcl", "scott", "tiger");- ������䡣
PreparedStatement ps = con.prepareStatement("select * from emp where sal between ? and ?"); ps.setInt(1, 1000); ps.setInt(2, 3000);- ִ����䡣
ResultSet rs = ps.executeQuery();- ���������
while(rs.next()) { System.out.println(rs.getInt("empno") + " - " + rs.getString("ename")); }- �ر���Դ��
finally { if(con != null) { try { con.close(); } catch (SQLException e) { e.printStackTrace(); } } }��ʾ���ر��ⲿ��Դ��˳��Ӧ�úʹ�˳���෴��Ҳ����˵�ȹر�ResultSet���ٹر�Statement���ڹر�Connection������Ĵ���ֻ�ر���Connection�����ӣ�����Ȼͨ��������ڹر�����ʱ�������ϴ��������ʹ��α�Ҳ��رգ������ܱ�֤������ˣ����Ӧ�ð��ող�˵��˳��ֱ�رա����⣬��һ������������JDBC 4.0���ǿ���ʡ�Եģ��Զ�����·���м������������������ǽ��鱣����
76��Statement��PreparedStatement��ʲô�����ĸ����ܸ��ã�
����Statement��ȣ���PreparedStatement�ӿڴ���Ԥ�������䣬����Ҫ���������ڿ��Լ���SQL�ı����������SQL�İ�ȫ�ԣ�����SQLע�乥���Ŀ����ԣ�����PreparedStatement�е�SQL����ǿ��Դ������ģ����������ַ�������ƴ��SQL�����鷳�Ͳ���ȫ���۵���������SQL��Ƶ��ִ����ͬ�IJ�ѯʱ��PreparedStatement�����Ե������ϵ����ƣ��������ݿ���Խ������Ż����SQL��仺���������´�ִ����ͬ�ṹ�����ʱ�ͻ�ܿ죨�����ٴα��������ִ�мƻ�����
���䣺Ϊ���ṩ�Դ洢���̵ĵ��ã�JDBC API�л��ṩ��CallableStatement�ӿڡ��洢���̣�Stored Procedure�������ݿ���һ��Ϊ������ض����ܵ�SQL���ļ��ϣ��������洢�����ݿ��У��û�ͨ��ָ���洢���̵����ֲ���������������ô洢���̴��в�������ִ��������Ȼ���ô洢���̻������翪������ȫ�ԡ������ϻ�úܶ�ô������Ǵ�������ײ����ݿⷢ��Ǩ��ʱ�ͻ��кܶ��鷳����Ϊÿ�����ݿ�Ĵ洢��������д�ϴ��ڲ��ٵIJ��
77��ʹ��JDBC�������ݿ�ʱ�����������ȡ���ݵ����ܣ���������������ݵ����ܣ�
��Ҫ������ȡ���ݵ����ܣ�����ָ��ͨ���������ResultSet�������setFetchSize()����ָ��ÿ��ץȡ�ļ�¼�������͵Ŀռ任ʱ����ԣ���Ҫ�����������ݵ����ܿ���ʹ��PreparedStatement��乹����������������SQL�������һ����������ִ�С�
78���ڽ������ݿ���ʱ�����ӳ���ʲô���ã�
�����ڴ������Ӻ��ͷ����Ӷ��кܴ�Ŀ��������������ݿ���������ڱ���ʱ��ÿ�ν������Ӷ���Ҫ����TCP���������֣��ͷ�������Ҫ����TCP�Ĵ����֣���ɵĿ����Dz��ɺ��ӵģ���Ϊ������ϵͳ�������ݿ�����ܣ��������ȴ������������������ӳ��У���Ҫʱֱ�Ӵ����ӳػ�ȡ��ʹ�ý���ʱ�黹���ӳض����عر����ӣ��Ӷ�����Ƶ���������ͷ���������ɵĿ��������ǵ��͵��ÿռ任ȡʱ��IJ��ԣ��˷��˿ռ�洢���ӣ�����ʡ�˴������ͷ����ӵ�ʱ�䣩���ػ�������Java�������Ǻܳ����ģ���ʹ���߳�ʱ�����̳߳صĵ��������ͬ������Java�Ŀ�Դ���ݿ����ӳ���Ҫ�У�C3P0��Proxool��DBCP��BoneCP��Druid�ȡ�
���䣺�ڼ����ϵͳ��ʱ��Ϳռ��Dz��ɵ��͵�ì�ܣ�������һ��������������Ҫ����㷨��������Ҫ�ġ�������վ�����Ż���һ���ؼ�����ʹ�û��棬����������潲�����ӳص����dz����ƣ�Ҳ��ʹ�ÿռ任ʱ��IJ��ԡ����Խ��ȵ��������ڻ����У����û���ѯ��Щ����ʱ����ֱ�Ӵӻ����еõ������������Ҳ���ȥ���ݿ��в�ѯ����Ȼ��������û����Ե�Ҳ���ϵͳ���ܲ�����ҪӰ�죬�����������������Ѿ�����������Ҫ�����ķ�Χ��
79��ʲô��DAOģʽ��
��DAO��Data Access Object������˼����һ��Ϊ���ݿ�������־û������ṩ�˳���ӿڵĶ����ڲ���¶�ײ�־û�����ʵ��ϸ�ڵ�ǰ�����ṩ�˸������ݷ��ʲ�������ʵ�ʵĿ����У�Ӧ�ý����ж�����Դ�ķ��ʲ������г����װ��һ������API�С��ó������������˵�����ǽ���һ���ӿڣ��ӿ��ж����˴�Ӧ�ó����н����õ������������������Ӧ�ó����У�����Ҫ������Դ���н�����ʱ����ʹ������ӿڣ����ұ�дһ������������ʵ������ӿڣ������ϸ����Ӧһ���ض������ݴ洢��DAOģʽʵ���ϰ���������ģʽ��һ��Data Accessor�����ݷ�������������Data Object�����ݶ���ǰ��Ҫ�����η������ݵ����⣬������Ҫ�����������ö����װ���ݡ�
80�������ACID��ָʲô��
��
- ԭ����(Atomic)�������и��������Ҫôȫ��Ҫôȫ�������κ�һ�������ʧ�ܶ��ᵼ�����������ʧ�ܣ�
- һ����(Consistent)�����������ϵͳ״̬��һ�µģ�
- ������(Isolated)������ִ�е�����˴��������Է����м�״̬��
- �־���(Durable)��������ɺ������ĸĶ����ᱻ�־û�����ʹ���������Ե�ʧ�ܡ�ͨ����־��ͬ�����ݿ����ڹ��Ϸ������ؽ����ݡ�
���䣺���������������б��ʵ��ĸ����Ǻܸߵģ������ʵ�����Ҳ�Ǻܶ�ġ�������Ҫ֪�����ǣ�ֻ�д��ڲ������ݷ���ʱ����Ҫ��������������ͬһ����ʱ�����ܻ����5�����⣬����3�����ݶ�ȡ���⣨����������ظ����ͻö�����2�����ݸ������⣨��1�ඪʧ���º͵�2�ඪʧ���£���
�����Dirty Read����A�����ȡB������δ�ύ�����ݲ��ڴ˻����ϲ�������B����ִ�лع�����ôA��ȡ�������ݾ��������ݡ�
| ʱ�� | ת������A | ȡ������B |
|---|---|---|
| T1 | ��ʼ���� | |
| T2 | ��ʼ���� | |
| T3 | ��ѯ�˻����Ϊ1000Ԫ | |
| T4 | ȡ��500Ԫ�����Ϊ500Ԫ | |
| T5 | ��ѯ�˻����Ϊ500Ԫ������� | |
| T6 | �����������ָ�Ϊ1000Ԫ | |
| T7 | ����100Ԫ�������Ϊ600Ԫ | |
| T8 | �ύ���� |
�����ظ�����Unrepeatable Read��������A���¶�ȡǰ���ȡ�������ݣ����ָ������Ѿ�����һ�����ύ������B�Ĺ��ˡ�
| ʱ�� | ת������A | ȡ������B |
|---|---|---|
| T1 | ��ʼ���� | |
| T2 | ��ʼ���� | |
| T3 | ��ѯ�˻����Ϊ1000Ԫ | |
| T4 | ��ѯ�˻����Ϊ1000Ԫ | |
| T5 | ȡ��100Ԫ�����Ϊ900Ԫ | |
| T6 | �ύ���� | |
| T7 | ��ѯ�˻����Ϊ900Ԫ�������ظ����� |
�ö���Phantom Read��������A����ִ��һ����ѯ������һϵ�з��ϲ�ѯ�������У��������в����˱�����B�ύ���С�
| ʱ�� | ͳ�ƽ������A | ת������B |
|---|---|---|
| T1 | ��ʼ���� | |
| T2 | ��ʼ���� | |
| T3 | ͳ���ܴ��Ϊ10000Ԫ | |
| T4 | ����һ������˻�����100Ԫ | |
| T5 | �ύ���� | |
| T6 | �ٴ�ͳ���ܴ��Ϊ10100Ԫ���ö��� |
��1�ඪʧ���£�����A����ʱ�����Ѿ��ύ������B�ĸ������ݸ����ˡ�
| ʱ�� | ȡ������A | ת������B |
|---|---|---|
| T1 | ��ʼ���� | |
| T2 | ��ʼ���� | |
| T3 | ��ѯ�˻����Ϊ1000Ԫ | |
| T4 | ��ѯ�˻����Ϊ1000Ԫ | |
| T5 | ����100Ԫ�����Ϊ1100Ԫ | |
| T6 | �ύ���� | |
| T7 | ȡ��100Ԫ�������Ϊ900Ԫ | |
| T8 | �������� | |
| T9 | ���ָ�Ϊ1000Ԫ����ʧ���£� |
��2�ඪʧ���£�����A��������B�Ѿ��ύ�����ݣ��������B�����IJ�����ʧ��
| ʱ�� | ת������A | ȡ������B |
|---|---|---|
| T1 | ��ʼ���� | |
| T2 | ��ʼ���� | |
| T3 | ��ѯ�˻����Ϊ1000Ԫ | |
| T4 | ��ѯ�˻����Ϊ1000Ԫ | |
| T5 | ȡ��100Ԫ�������Ϊ900Ԫ | |
| T6 | �ύ���� | |
| T7 | ����100Ԫ�������Ϊ1100Ԫ | |
| T8 | �ύ���� | |
| T9 | ��ѯ�˻����Ϊ1100Ԫ����ʧ���£� |
���ݲ������������������⣬����Щ�����¿����������ģ�������Щ�����¿��ܾ��������ģ����ݿ�ͨ����ͨ����������������ݲ����������⣬����������ͬ���Է�Ϊ���������м���������������������ϵ���Է�Ϊ�������Ͷ�ռ������������ݴ�ҿ������в������Ͻ����˽⡣
ֱ��ʹ�����Ƿdz��鷳�ģ�Ϊ�����ݿ�Ϊ�û��ṩ���Զ������ƣ�ֻҪ�û�ָ���Ự��������뼶�����ݿ�ͻ�ͨ������SQL���Ȼ��Ϊ������ʵ���Դ���Ϻ��ʵ��������⣬���ݿ��ά����Щ��ͨ�������ֶ����ϵͳ�����ܣ���Щ���û���˵�������ģ�����˵�㲻�����⣬��ʵ����ȷʵҲ��֪������ANSI/ISO SQL 92��������4���ȼ���������뼶�����±���ʾ��
| ���뼶�� | ��� | �����ظ��� | �ö� | ��һ�ඪʧ���� | �ڶ��ඪʧ���� |
|---|---|---|---|---|---|
| READ UNCOMMITED | ���� | ���� | ���� | ������ | ���� |
| READ COMMITTED | ������ | ���� | ���� | ������ | ���� |
| REPEATABLE READ | ������ | ������ | ���� | ������ | ������ |
| SERIALIZABLE | ������ | ������ | ������ | ������ | ������ |
��Ҫ˵�����ǣ�������뼶������ݷ��ʵIJ������Ƕ����ģ�������뼶��Խ�߲����Ծ�Խ�����Ҫ���ݾ����Ӧ����ȷ�����ʵ�������뼶������ط�û�����ܵ�ԭ��
81��JDBC��������������
��Connection�ṩ���������ķ�����ͨ������setAutoCommit(false)���������ֶ��ύ����������ɺ���commit()��ʽ�ύ��������������������з����쳣��ͨ��rollback()��������ع�������֮�⣬��JDBC 3.0�л�������Savepoint������㣩�ĸ������ͨ���������ñ���㲢������ع���ָ���ı���㡣 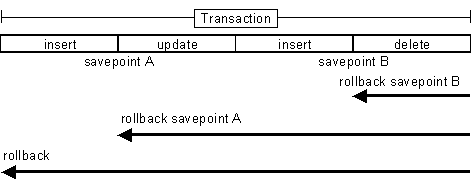
82��JDBC�ܷ���Blob��Clob��
�� Blob��ָ�����ƴ����Binary Large Object������Clob��ָ���ַ�����Character Large Objec�����������Blob��Ϊ�洢��Ķ��������ݶ���Ƶģ���Clob��Ϊ�洢����ı����ݶ���Ƶġ�JDBC��PreparedStatement��ResultSet���ṩ����Ӧ�ķ�����֧��Blob��Clob����������Ĵ���չʾ�����ʹ��JDBC����LOB��
������MySQL���ݿ�Ϊ��������һ�����������ֶε��û�����������ţ�id����������name������Ƭ��photo��������������£�
create table tb_user(id int primary key auto_increment,name varchar(20) unique not null,photo longblob);�����Java���������ݿ��в���һ����¼��
import java.io.FileInputStream;import java.io.IOException;import java.io.InputStream;import java.sql.Connection;import java.sql.DriverManager;import java.sql.PreparedStatement;import java.sql.SQLException;class JdbcLobTest { public static void main(String[] args) { Connection con = null; try { // 1. ����������Java6���ϰ汾����ʡ�ԣ� Class.forName("com.mysql.jdbc.Driver"); // 2. �������� con = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "123456"); // 3. ���������� PreparedStatement ps = con.prepareStatement("insert into tb_user values (default, ?, ?)"); ps.setString(1, "���"); // ��SQL����е�һ��ռλ�������ַ��� try (InputStream in = new FileInputStream("test.jpg")) { // Java 7��TWR ps.setBinaryStream(2, in); // ��SQL����еڶ���ռλ�����ɶ������� // 4. ����SQL�������Ӱ������ System.out.println(ps.executeUpdate() == 1 ? "����ɹ�" : "����ʧ��"); } catch(IOException e) { System.out.println("��ȡ��Ƭʧ��!"); } } catch (ClassNotFoundException | SQLException e) { // Java 7�Ķ��쳣���� e.printStackTrace(); } finally { // �ͷ��ⲿ��Դ�Ĵ��붼Ӧ������finally�б�֤���ܹ��õ�ִ�� try { if(con != null && !con.isClosed()) { con.close(); // 5. �ͷ����ݿ����� con = null; // ָʾ�������������Ի��ոö��� } } catch (SQLException e) { e.printStackTrace(); } } }}83�������������ʽ������;��
���ڱ�д�����ַ����ij���ʱ���������в��ҷ���ijЩ���ӹ�����ַ�������Ҫ���������ʽ��������������Щ����Ĺ��ߡ����仰˵���������ʽ���Ǽ�¼�ı�����Ĵ��롣
˵����������������ڴ�������Ϣ����������ֵ������ʱ����Ǩ����������ʹ�ü������������Ϣ�����ʱ������ֵ�����ַ������������ʽ�����ڽ����ַ���ƥ��ʹ�����ʱ����Ϊǿ��Ĺ��ߣ�����������Զ��ṩ�˶��������ʽ��֧�֡�
84��Java�������֧���������ʽ�����ģ�
��Java�е�String���ṩ��֧���������ʽ�����ķ�����������matches()��replaceAll()��replaceFirst()��split()�����⣬Java�п�����Pattern���ʾ�������ʽ�������ṩ�˷ḻ��API���и����������ʽ��������ο�����������Ĵ��롣
�����⣺ - ���Ҫ���ַ����н�ȡ��һ��Ӣ��������֮ǰ���ַ��������磺������(������)(������)(������)����ȡ���Ϊ�������У���ô�������ʽ��ôд��
import java.util.regex.Matcher;import java.util.regex.Pattern;class RegExpTest { public static void main(String[] args) { String str = "������(������)(������)(������)"; Pattern p = Pattern.compile(".*?(?=\\()"); Matcher m = p.matcher(str); if(m.find()) { System.out.println(m.group()); } }}˵����������������ʽ��ʹ��������ƥ���ǰհ������������Щ���ݣ��Ƽ���һ�����Ϻ������ġ��������ʽ30�������Ž̡̳���
85�����һ��������������Щ��ʽ��
��
- ����1������.class�����磺String.class
- ����2������.getClass()�����磺"hello".getClass()
- ����3��Class.forName()�����磺Class.forName("java.lang.String")
86�����ͨ�����䴴������
��
- ����1��ͨ����������newInstance()���������磺String.class.newInstance()
- ����2��ͨ��������getConstructor()��getDeclaredConstructor()������ù�������Constructor����������newInstance()���������������磺String.class.getConstructor(String.class).newInstance("Hello");
87�����ͨ�������ȡ�����ö���˽���ֶε�ֵ��
�𣺿���ͨ��������getDeclaredField()�����ֶΣ�Field������Ȼ����ͨ���ֶζ����setAccessible(true)��������Ϊ���Է��ʣ��������Ϳ���ͨ��get/set��������ȡ/�����ֶε�ֵ�ˡ�����Ĵ���ʵ����һ������Ĺ����࣬���е�������̬�����ֱ����ڻ�ȡ������˽���ֶε�ֵ���ֶο����ǻ�������Ҳ�����Ƕ���������֧�ֶ༶�������������ReflectionUtil.get(dog, "owner.car.engine.id");���Ի��dog��������˵������������ID�š�
import java.lang.reflect.Constructor;import java.lang.reflect.Field;import java.lang.reflect.Modifier;import java.util.ArrayList;import java.util.List;/** * ���乤���� * @author ��� * */public class ReflectionUtil { private ReflectionUtil() { throw new AssertionError(); } /** * ͨ������ȡ����ָ���ֶ�(����)��ֵ * @param target Ŀ����� * @param fieldName �ֶε����� * @throws ���ȡ��������ָ���ֶε�ֵ���׳��쳣 * @return �ֶε�ֵ */ public static Object getValue(Object target, String fieldName) { Class<?> clazz = target.getClass(); String[] fs = fieldName.split("\\."); try { for(int i = 0; i < fs.length - 1; i++) { Field f = clazz.getDeclaredField(fs[i]); f.setAccessible(true); target = f.get(target); clazz = target.getClass(); } Field f = clazz.getDeclaredField(fs[fs.length - 1]); f.setAccessible(true); return f.get(target); } catch (Exception e) { throw new RuntimeException(e); } } /** * ͨ������������ָ���ֶθ�ֵ * @param target Ŀ����� * @param fieldName �ֶε����� * @param value ֵ */ public static void setValue(Object target, String fieldName, Object value) { Class<?> clazz = target.getClass(); String[] fs = fieldName.split("\\."); try { for(int i = 0; i < fs.length - 1; i++) { Field f = clazz.getDeclaredField(fs[i]); f.setAccessible(true); Object val = f.get(target); if(val == null) { Constructor<?> c = f.getType().getDeclaredConstructor(); c.setAccessible(true); val = c.newInstance(); f.set(target, val); } target = val; clazz = target.getClass(); } Field f = clazz.getDeclaredField(fs[fs.length - 1]); f.setAccessible(true); f.set(target, value); } catch (Exception e) { throw new RuntimeException(e); } }}88�����ͨ��������ö���ķ�����
���뿴����Ĵ��룺
import java.lang.reflect.Method;class MethodInvokeTest { public static void main(String[] args) throws Exception { String str = "hello"; Method m = str.getClass().getMethod("toUpperCase"); System.out.println(m.invoke(str)); // HELLO }}89������һ����������"��ԭ��һ����"��
��
- ��һְ��ԭ��һ����ֻ�������������顣����һְ��ԭ�������ľ���"���ھ�"��д�������ռ���ԭ��ֻ��������"���ھۡ������"������ͬ����������а��������˼��Ͱ˸���"�����˹������Թ�"����ν�ĸ��ھ۾���һ������ģ��ֻ���һ��ܣ�����������У����ֻ��һ����������������£������漰�����ص�������Ǽ����˸��ھ۵�ԭ��������ֻ�е�һְ�����Ƕ�֪��һ�仰��"��Ϊרע������רҵ"��һ����������е�̫���ְ����ôע����ʲô�������á�����������κκõĶ�����������������һ���ǹ��ܵ�һ���õ�������Բ��ǵ��ӹ���������������һ��������һ�ٶ��ֹ��ܵģ���������ֻ�����ࣻ��һ����ģ�黯���õ����г�����װ�����Ӽ���桢ɲ���������������еIJ������ǿ��Բ�ж��������װ�ģ��õ�ƹ������Ҳ���dz�Ʒ�ģ�һ���ǵװ�ͽ�Ƥ���Բ�ֺ�������װ�ģ�һ���õ�����ϵͳ���������ÿ������ģ��ҲӦ���ǿ��������õ�����ϵͳ��ʹ�õģ���������ʵ���������õ�Ŀ�ꡣ��
- ����ԭ������ʵ��Ӧ������չ���ţ����Ĺرա����������״̬�£���������ҪΪһ������ϵͳ�����¹���ʱ��ֻ��Ҫ��ԭ����ϵͳ������һЩ����Ϳ��ԣ�����Ҫ��ԭ�����κ�һ�д��롣Ҫ��������������Ҫ�㣺�ٳ����ǹؼ���һ��ϵͳ�����û�г������ӿ�ϵͳ��û����չ�㣻�ڷ�װ�ɱ��ԣ���ϵͳ�еĸ��ֿɱ����ط�װ��һ���̳нṹ�У��������ɱ����ػ�����һ��ϵͳ����ø��Ӷ����ң�����������η�װ�ɱ��ԣ����Բο������ģʽ���⡷һ���ж�����ģʽ�Ľ�����½ڡ���
- ������תԭ������ӿڱ�̡�����ԭ��˵��ֱ�;���һЩ�������������IJ������͡������ķ������͡���������������ʱ��������ʹ�ó������Ͷ����þ������ͣ���Ϊ�������Ϳ��Ա������κ�һ�����������������ο�����������滻ԭ��
�����滻ԭ���κ�ʱ�������������滻�������͡������������滻ԭ���������Barbara LiskovŮʿ�����������Ҫ���ӵö࣬����˵�������ø����͵ĵط���һ����ʹ�������͡������滻ԭ����Լ��̳й�ϵ�Ƿ���������һ���̳й�ϵΥ���������滻ԭ����ô����̳й�ϵһ���Ǵ���ģ���Ҫ�Դ�������ع���������è�̳й������߹��̳�è���ֻ����������μ̳г����ζ��Ǵ���ļ̳й�ϵ����Ϊ��������ҵ�Υ�������滻ԭ��ij�������Ҫע����ǣ�����һ�������Ӹ�������������Ǽ��ٸ������������Ϊ����ȸ�����������࣬��������Ķ��������ٵĶ������õ�Ȼû���κ����⡣��
- �ӿڸ���ԭ�ӿ�ҪС��ר�������ܴ��ȫ����ӷ�Ľӿ��ǶԽӿڵ���Ⱦ����Ȼ�ӿڱ�ʾ��������ôһ���ӿ�ֻӦ������һ���������ӿ�ҲӦ���Ǹ߶��ھ۵ġ����磬�����黭��Ӧ�÷ֱ����Ϊ�ĸ��ӿڣ�����Ӧ��Ƴ�һ���ӿ��е��ĸ���������Ϊ�����Ƴ�һ���ӿ��е��ĸ���������ô����ӿں����ã��Ͼ������黭��������ͨ���˻����������������Ƴ��ĸ��ӿڣ��Ἰ���ʵ�ּ����ӿڣ������Ļ�ÿ���ӿڱ����õĿ������Ǻܸߵġ�Java�еĽӿڴ�������������Լ����������ɫ���ܷ���ȷ��ʹ�ýӿ�һ���DZ��ˮƽ�ߵ͵���Ҫ��ʶ����
- �ϳɾۺϸ���ԭ������ʹ�þۺϻ�ϳɹ�ϵ���ô��롣��ͨ���̳������ô�������������������б����õ����Ķ�������Ϊ���еĽ̿��鶼��һ����ĶԼ̳н����˹Ĵ��Ӷ����˳�ѧ�ߣ�������֮���˵�����ֹ�ϵ��Is-A��ϵ��Has-A��ϵ��Use-A��ϵ���ֱ�����̳С����������������У�������ϵ�����������ǿ���ֿ��Խ�һ������Ϊ�������ۺϺͺϳɣ���˵���˶���Has-A��ϵ���ϳɾۺϸ���ԭ�������������ȿ���Has-A��ϵ������Is-A��ϵ���ô��룬ԭ��������Լ��Ӱٶ����ҵ�һ������ɣ���Ҫ˵�����ǣ���ʹ��Java��API��Ҳ�в������ü̳е����ӣ�����Properties��̳���Hashtable�࣬Stack��̳���Vector�࣬��Щ�̳����Ծ��Ǵ���ģ����õ���������Properties���з���һ��Hashtable���͵ij�Ա���ҽ������ֵ������Ϊ�ַ������洢���ݣ���Stack������ҲӦ������Stack���з�һ��Vector�������洢���ݡ���ס���κ�ʱ��Ҫ�̳й����࣬�����ǿ���ӵ�в�����ʹ�õģ������������̳еġ���
- �����ط������ط����ֽ�����֪ʶԭ��һ������Ӧ�������������о������ٵ��˽⡣�������ط����˵�����������"�����"������ģʽ�͵�ͣ��ģʽ���ǶԵ����ط���ļ��С���������ģʽ���Ծ�һ�������ӣ���ȥһ�ҹ�˾Ǣ̸ҵ���㲻��Ҫ�˽������˾�ڲ�����������ģ����������Զ������˾һ����֪��ȥ��ʱ��ֻ��Ҫ�ҵ���˾��ڴ���ǰ̨��Ů������������Ҫ��ʲô�����ǻ��ҵ����ʵ��˸����Ǣ��ǰ̨����Ů���ǹ�˾���ϵͳ�����档�ٸ��ӵ�ϵͳ������Ϊ�û��ṩһ�������棬Java Web��������Ϊǰ�˿�������Servlet��Filter������һ��������������Է�������������ʽһ����֪������ͨ��ǰ�˿��������ܹ������������õ���Ӧ�ķ���ͣ��ģʽҲ���Ծ�һ����������˵��������һ̨�������CPU���ڴ桢Ӳ�̡��Կ������������豸��Ҫ���ϲ��ܺܺõĹ��������������Щ������ֱ�����ӵ�һ�𣬼�����IJ��߽��쳣���ӣ�����������£�������Ϊһ����ͣ�ߵ����ݳ��֣����������豸������һ�������Ҫÿ���豸֮��ֱ�ӽ������ݣ������ͼ�С��ϵͳ����϶Ⱥ��Ӷȣ�����ͼ��ʾ�������ط�����ͨ�Ļ��������Dz�Ҫ��İ���˴�����������Ҫ����һ���Լ������ѣ����������İ���˴�����
90������һ�����˽�����ģʽ��
����ν���ģʽ������һ�ױ�����ʹ�õĴ�����ƾ�����ܽᣨ�龳��һ�����⾭��֤ʵ��һ�������������ʹ�����ģʽ��Ϊ�˿����ô��롢�ô�������ױ��������⡢��֤����ɿ��ԡ����ģʽʹ���ǿ��Ը��Ӽ���ĸ��óɹ�����ƺ���ϵ�ṹ������֤ʵ�ļ������������ģʽҲ��ʹ��ϵͳ�����߸����������������˼·��
��GoF�ġ�Design Patterns: Elements of Reusable Object-Oriented Software���и��������ࣨ������[�����ʵ�������̵ij���]���ṹ��[������ν�����������һ���γɸ���Ľṹ]����Ϊ��[���ڲ�ͬ�Ķ���֮�仮�����κ��㷨�ij���]����23�����ģʽ��������Abstract Factory������ģʽ����Builder��������ģʽ����Factory Method����������ģʽ����Prototype��ԭʼģ��ģʽ����Singleton������ģʽ����Facade������ģʽ����Adapter��������ģʽ����Bridge������ģʽ����Composite���ϳ�ģʽ����Decorator��װ��ģʽ����Flyweight����Ԫģʽ����Proxy������ģʽ����Command������ģʽ����Interpreter��������ģʽ����Visitor��������ģʽ����Iterator��������ģʽ����Mediator����ͣ��ģʽ����Memento������¼ģʽ����Observer���۲���ģʽ����State��״̬ģʽ����Strategy������ģʽ����Template Method��ģ�巽��ģʽ���� Chain Of Responsibility��������ģʽ����
���Ա��ʵ��������ģʽ��֪ʶʱ�����Լ���õ��������磺
- ����ģʽ����������Ը����������ɲ�ͬ������ʵ������Щ������һ�������ij����ಢ��ʵ������ͬ�ķ�����������Щ������Բ�ͬ�����ݽ����˲�ͬ�IJ�������̬�����������õ������ʵ��������Ա���Ե��û����еķ��������ؿ��ǵ����ص�����һ�������ʵ����
- ����ģʽ����һ�������ṩһ�����������ɴ����������ԭ��������á�ʵ�ʿ����У�����ʹ��Ŀ�ĵIJ�ͬ���������Է�Ϊ��Զ�̴������������������������Cache����������ǽ������ͬ�����������������ô�����
- ������ģʽ����һ����Ľӿڱ任�ɿͻ������ڴ�����һ�ֽӿڣ��Ӷ�ʹԭ����ӿڲ�ƥ�������һ��ʹ�õ����ܹ�һ������
- ģ�巽��ģʽ���ṩһ�������࣬���������Ծ��巽������������ʽʵ�֣�Ȼ������һЩ��������ʹ����ʵ��ʣ���������ͬ����������Բ�ͬ�ķ�ʽʵ����Щ��������̬ʵ�֣����Ӷ�ʵ�ֲ�ͬ��ҵ������
����֮�⣬�����Խ��������ᵽ������ģʽ������ģʽ������ģʽ��װ��ģʽ��Collections�������I/Oϵͳ�ж�ʹ��װ��ģʽ���ȣ���������ԭ����Ǽ��Լ�����Ϥ�ġ��õ��������������Զ��ʧ��
91����Javaдһ�������ࡣ
��
- ����ʽ����
public class Singleton { private Singleton(){} private static Singleton instance = new Singleton(); public static Singleton getInstance(){ return instance; }}- ����ʽ����
public class Singleton { private static Singleton instance = null; private Singleton() {} public static synchronized Singleton getInstance(){ if (instance == null) instance �� new Singleton(); return instance; }}ע�⣺ʵ��һ������������ע������ٽ�������˽�У����������ͨ����������������ͨ�������ľ�̬��������緵�����Ψһʵ����������һ���������˼����Spring��IoC��������Ϊ��ͨ���ഴ��������������ô�������أ�
92��ʲô��UML��
��UML��ͳһ��ģ���ԣ�Unified Modeling Language������д����������1997�꣬�ۺ��˵�ʱ�Ѿ����ڵ��������Ľ�ģ���ԡ��������̣���һ��֧��ģ�ͻ�������ϵͳ������ͼ�λ����ԣ�Ϊ�������������н��ṩģ�ͻ��Ϳ��ӻ�֧�֡�ʹ��UML��������ͨ�뽻��������Ӧ����ƺ��ĵ������ɣ����ܹ�����ϵͳ�Ľṹ����Ϊ��
93��UML������Щ���õ�ͼ��
��UML�����˶���ͼ�λ��ķ�������������ϵͳ���ֻ�ȫ���ľ�̬�ṹ�Ͷ�̬�ṹ������������ͼ��use case diagram������ͼ��class diagram����ʱ��ͼ��sequence diagram����Э��ͼ��collaboration diagram����״̬ͼ��statechart diagram�����ͼ��activity diagram��������ͼ��component diagram��������ͼ��deployment diagram���ȡ�����Щͼ�λ������У�������ͼ��Ϊ��Ҫ���ֱ��ǣ�����ͼ������������������ϵͳ�Ĺ��ܣ�ͨ����ͼ����Ѹ�ٵ��˽�ϵͳ�Ĺ���ģ�鼰���ϵ������ͼ���������Լ�������֮��Ĺ�ϵ��ͨ����ͼ���Կ����˽�ϵͳ����ʱ��ͼ������ִ���ض�����ʱ����֮��Ľ�����ϵ�Լ�ִ��˳��ͨ����ͼ�����˽�����ܽ��յ���ϢҲ����˵�����ܹ�������ṩ�ķ���
����ͼ�� 
��ͼ�� 
ʱ��ͼ�� 
94����Javaдһ��ð������
��ð�������Ǹ�����Ա��д�ó������������Ե�ʱ�����дһ���Ƹ�ߵ�ð������ȴ����ÿ���˶��������������ṩһ���ο����룺
import java.util.Comparator;/** * �������ӿ�(����ģʽ: ���㷨��װ�����й�ͬ�ӿڵĶ���������ʹ�����ǿ�����滻) * @author��� * */public interface Sorter { /** * ���� * @param list ����������� */ public <T extends Comparable<T>> void sort(T[] list); /** * ���� * @param list ����������� * @param comp �Ƚ���������ıȽ��� */ public <T> void sort(T[] list, Comparator<T> comp);}import java.util.Comparator;/** * ð������ * * @author��� * */public class BubbleSorter implements Sorter { @Override public <T extends Comparable<T>> void sort(T[] list) { boolean swapped = true; for (int i = 1, len = list.length; i < len && swapped; ++i) { swapped = false; for (int j = 0; j < len - i; ++j) { if (list[j].compareTo(list[j + 1]) > 0) { T temp = list[j]; list[j] = list[j + 1]; list[j + 1] = temp; swapped = true; } } } } @Override public <T> void sort(T[] list, Comparator<T> comp) { boolean swapped = true; for (int i = 1, len = list.length; i < len && swapped; ++i) { swapped = false; for (int j = 0; j < len - i; ++j) { if (comp.compare(list[j], list[j + 1]) > 0) { T temp = list[j]; list[j] = list[j + 1]; list[j + 1] = temp; swapped = true; } } } }}95����Javaдһ���۰���ҡ�
���۰���ң�Ҳ�ƶ��ֲ��ҡ�������������һ�������������в���ijһ�ض�Ԫ�ص������㷨�����ع��̴�������м�Ԫ�ؿ�ʼ������м�Ԫ��������Ҫ���ҵ�Ԫ�أ������ع��̽��������ijһ�ض�Ԫ�ش��ڻ���С���м�Ԫ�أ�����������ڻ�С���м�Ԫ�ص���һ���в��ң����Ҹ���ʼһ�����м�Ԫ�ؿ�ʼ�Ƚϡ������ijһ���������Ѿ�Ϊ�գ����ʾ�Ҳ���ָ����Ԫ�ء����������㷨ÿһ�αȽ϶�ʹ������Χ��Сһ�룬��ʱ�临�Ӷ���O(logN)��
import java.util.Comparator;public class MyUtil { public static <T extends Comparable<T>> int binarySearch(T[] x, T key) { return binarySearch(x, 0, x.length- 1, key); } // ʹ��ѭ��ʵ�ֵĶ��ֲ��� public static <T> int binarySearch(T[] x, T key, Comparator<T> comp) { int low = 0; int high = x.length - 1; while (low <= high) { int mid = (low + high) >>> 1; int cmp = comp.compare(x[mid], key); if (cmp < 0) { low= mid + 1; } else if (cmp > 0) { high= mid - 1; } else { return mid; } } return -1; } // ʹ�õݹ�ʵ�ֵĶ��ֲ��� private static<T extends Comparable<T>> int binarySearch(T[] x, int low, int high, T key) { if(low <= high) { int mid = low + ((high -low) >> 1); if(key.compareTo(x[mid])== 0) { return mid; } else if(key.compareTo(x[mid])< 0) { return binarySearch(x,low, mid - 1, key); } else { return binarySearch(x,mid + 1, high, key); } } return -1; }}˵��������Ĵ����и������۰���ҵ������汾��һ���õݹ�ʵ�֣�һ����ѭ��ʵ�֡���Ҫע����Ǽ����м�λ��ʱ��Ӧ��ʹ��(high+ low) / 2�ķ�ʽ����Ϊ�ӷ�������ܵ�������Խ�磬����Ӧ��ʹ���������ַ�ʽ֮һ��low + (high - low) / 2��low + (high �C low) >> 1��(low + high) >>> 1��>>>�������ƣ��Dz�������λ�����ƣ�