本节续上节
机器学习之logistic回归与分类
对logistic分类的线性与非线性进行实验。上节中的“种子”分类实例中,样本虽然有7维,但是很大很大程度上符合线性可分的,为了在说明上节中的那种logistic对于非线性不可分,进行如下的两组样本进行实验,一组线性,一组非线性,样本如下:
线性样本: 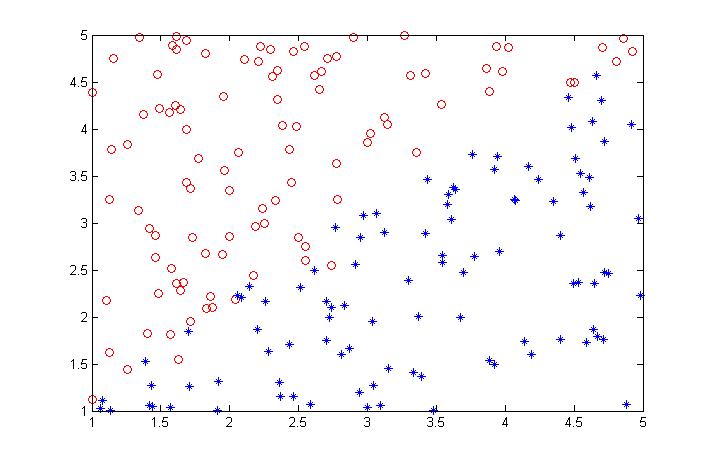
非线性样本: 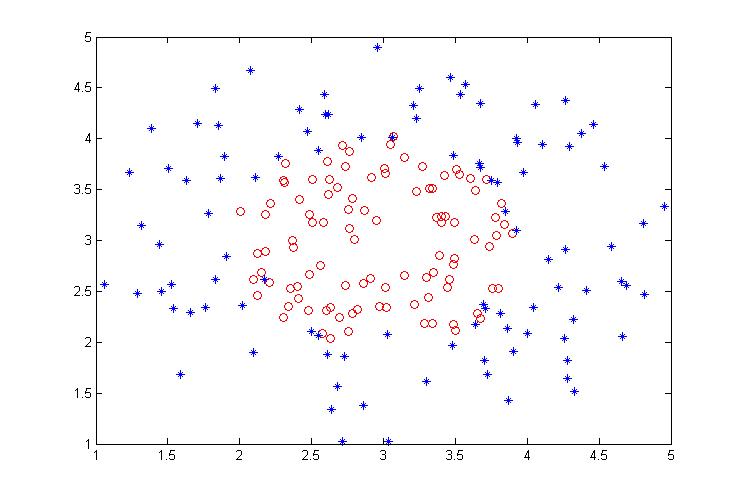
为了防止完全可分,在1,2类样本的分界面上重叠一部分样本,也就是说这部分样本很难分出来,图中的样本也可以看出来。
线性与非线性样本都包含两类,每类100个样本点。
先对线性样本实验,代码同上节的大致相同:
%% % * Logistic方法用于回归分析与分类设计% * 简单0-1两类分类--非线性分类与线性分类% %% clcclearclose all%% Load data% * 数据预处理--分两类情况% 并将标签重新设置为0与1,方便sigmod函数应用 data = load('data_test.mat');data = data.data';data(:,3) = data(:,3) - 1;%选择训练样本个数num_train = 50;%构造随机选择序列choose = randperm(length(data));train_data = data(choose(1:num_train),:);label_train = train_data(:,end);test_data = data(choose(num_train+1:end),:);label_test = test_data(:,end);data_D = size(train_data,2) - 1;% initial 'weights' paraweights = ones(1,data_D);%% training data weights% * 随机梯度上升算法-在线学习for j = 1:100 alpha = 0.1/j; for i = 1:length(train_data) data = train_data(i,1:end-1); h = 1.0/(1+exp(-(data*weights'))); error = label_train(i) - h; weights = weights + (alpha * error * data); endend% * 整体梯度算法-批量/离线学习% for j = 1:2000% alpha = 0.1/j;% % alpha = 0.001;% data = train_data(:,1:end-1);% h = 1./(1+exp(-(data*weights')));% error = label_train - h;% weights = weights + (alpha * data' * error)';% end%% predict the testing datadiff = zeros(2,length(test_data));for i = 1:length(test_data) data = test_data(i,1:end-1); h = 1.0/(1+exp(-(data*weights'))); %compare to every label for j = 1:2 diff(j,i) = abs((j-1)-h); endend[~,predict] = min(diff);% show the resultfigure;plot(label_test+1,'+')hold onplot(predict,'or');hold on plot(abs(predict'-(label_test+1)));axis([0,length(test_data),0,3])accuracy = length(find(predict'==(label_test+1)))/length(test_data);title(['predict the testing data and the accuracy is :',num2str(accuracy)]);%-------------------figure;index1 = find(predict==1);data1 = (test_data(index1,:))';plot(data1(1,:),data1(2,:),'or');hold onindex2 = find(predict==2);data2 = (test_data(index2,:))';plot(data2(1,:),data2(2,:),'*');hold onindexw = find(predict'~=(label_test+1));dataw = (test_data(indexw,:))';plot(dataw(1,:),dataw(2,:),'+g','LineWidth',3);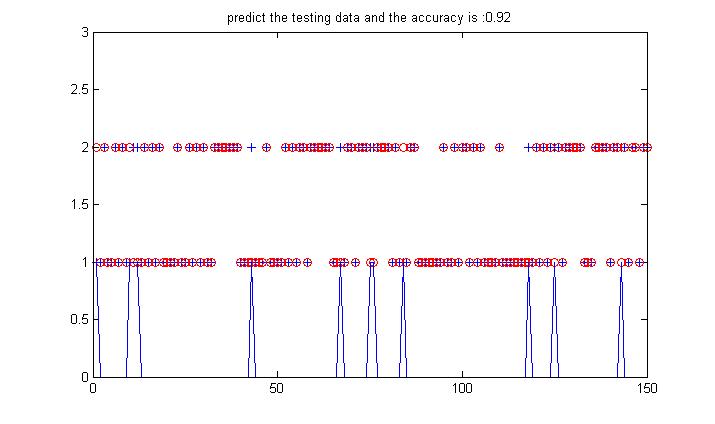
分割结果已经错分的点(绿色标出) 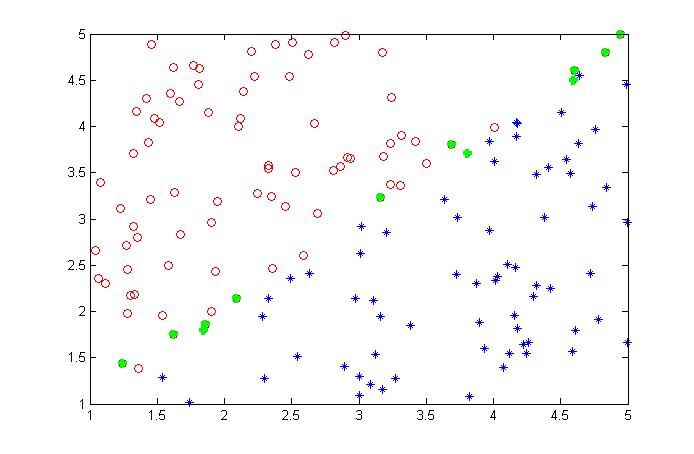
下面将data换成非线性的试试: 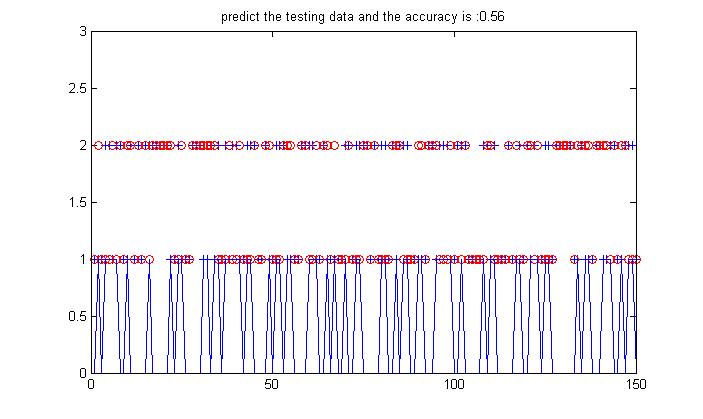
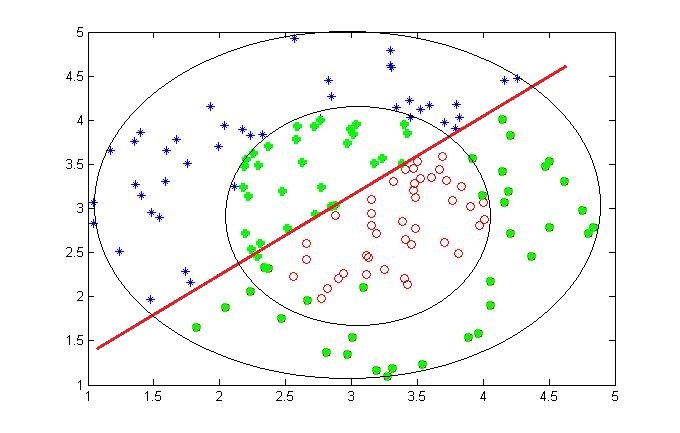
可以看到对于非线性是不可分的,它产生的分界面似乎还是线性界面(如红线画出),红线上面的本来输入内圆的被分到了外圆导致错分,下面的本来属于外圆的本分到了内圆导致错分。
对于非线性的分类,可以再logistic基础上增加多层sigmod分类节点,也就演化为基本的神经网络模型。
版权声明:本文为博主原创文章,未经博主允许不得转载。