������������������ԭ�Ĵ���һ�������⣬�����н��Ͳ��Ǻ�����Լ�����ĵط������������������ϸ��������ϣ���Դ�����á�
?
��Ҫ���̷�Ϊ4���֣�
1.��װcygwin����sshd����
2.����hadoop
3.����eclipse����hadoop
4.����eclipse����mapreduce
��1���������׳��ָ�������ĵط����������÷����ʱ��ǰ�����������һ��ʮ�����⣬����1��2���������ʲô���������ȫж��ɾ��Ȼ���ϸ��ղ�����������
1.��װcygwin����sshd����
��װcygwin��Ϊ�˸�hadoop�ṩlinux������sshd��Ϊ���ṩhadoop��ͨ�ŷ�ʽ��
1.1��װcygwin
�ӹ��������ذ�װ�ͺã���װѡ���ʱ����netģ������Ҫѡ��װopenssh��openssl������ģ��
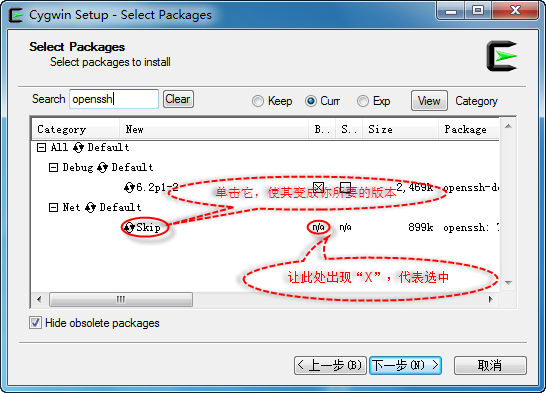
?
���ڰ�װ�����л�����������Ҫ��װ��ģ�飬������Ӧģ���bin���ԣ�ʹ���������棬�ͱ�ʾ����ѡ������������鿴http://wenku.baidu.com/view/7e8dd50b52ea551810a6879c.html���˴����ǰ����е���openssh��openssl��صIJ��ֶ���װ�ˡ���������default�ͺ���
��װ��ɺ���Ҫ����ϵͳ����,��Path�������cygwin��binĿ¼��usr/sbinĿ¼
1.2ȡ��cygwin��rootȨ��
��װ��ɺ�����һ��bash�����ٹرգ���/home/Ŀ¼�¾ͻ����һ��������û����������ļ���(Ҳ����cygwinΪ�㴴����һ����windowsһ�����û�),�����ҵľ���/home/WANGCHAO,������ļ��и���Ϊroot
��/etc/passwd�ļ����ҵ�����û�������һ��,(WANGCHAO:unused:1000:513:U-WANGCHAO-PC\WANGCHAO,S-1-5-21-703394362-527095193-1703888876-1000:/home/WANGCHAO:/bin/bash)��С�Ĵ˴����������������Ƶ���Ŀ��administrator��guest��WANGCHAO����WANGCHAO�����Ŀ������һ�е��û�������Ϊrootͬʱ����Ȩ��Ϊ���(root:unused:0:0:U-WANGCHAO-PC\root,S-1-5-21-703394362-527095193-1703888876-1000:/home/root:/bin/bash)
��������Ժ��ٴ�bash�ͻᷢ������û�����Ϊ��root����ͨ�����#,�������õ���rootȨ��������root�û�
1.3��װsshd���� ���ɲο�http://wenku.baidu.com/view/7e8dd50b52ea551810a6879c.html��
��bash��������ssh-host-config,��һ������"Should privilege separation be used?"ѡno,��Do you want to install sshd as a service?��ѡyes����enter the value of CYGWIN for the daemon:�����ntsec������Do you want to proceed anyway?����ѡyes��������ѡno��������Ǵ���sshd���û�������,�Լ���һ�¾ͺ�,��������"Have fun��"������DZ���Ҫ���ֵģ���Ȼ��ʾ�㰲װʧ���ˡ����ǰ�װ�ɹ���,��ʱ��ִ��net start sshd��������������,��Ϊ��һ�����÷����ʱ��ǿ����Ҫ��������,�����Dz���Ҫ����,���Խ�������/etc/passwd������һ��
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin
�ؿ�һ��bash����net start sshd���û�з��ش������Ϳ�����win7�Լ��IJ鿴�������濴�Dz�����һ����CYGWIN_SSHD�ķ����Լ�������.
1.4����sshd��localhost����
����ssh localhost,��������������,������Ϊ��ʱlocalhost�����ڷ���������б���������Ϊ�����������룬��ʱ���õ��롿,��Ҫ
ssh-keygen -t dsa������ʾ���س����С�
cd ~/.ssh
cat id_dsa.pub >> authorized_keys? ����Ϊһ�����
Ȼ��ssh localhost�������Ҫ����������óɹ���.
������ɹ������authorized_keys��.sshĿ¼��Ȩ��
chmod 644 authorized_keys
cd ~
chmod 700 .ssh
Ӧ�þͿ�����.
���˵�һ���������,��һ�����ܻ��зdz���Ĵ���,Ŀǰд��������ҳɹ��ķ���,����ذ���˵���IJ���˳���ϸ�ִ��.
?
2.����hadoop
2.1����hadoop
�ӹ���������hadoop1.0.2�汾��hadoop1.0.2.tar.gz,֮����������汾����ΪҪ����eclipse��������Ҫ����������Դ��,�������˰�����汾������,���ǿ���ֱ��������,������Ҫ��Դ�����Լ��Ĵ��,���ڹ���û�ҵ�src�İ�,���Ծ�ʹ��������汾,��������Ҳ��1.0.4,���������
2.2����javaϵͳ����
��һ���DZ����,��Ϊhadoop�Լ��Ĵ���ʵ�ֵ�����,�������jdk����Ҫ��װ��C:\program\Ŀ¼��.��ע�ⲻ��program files,������Ƕ�Ӧ��λ�þ���װһ��jdk��.
���û�������,�����ҵ�jdk��C:\Program\Java\jdk1.7.0_05����,�½�JAVA_HOME����,ֵΪjdk�����jreĿ¼,��C:\Program\Java\jdk1.7.0_05\jre;
��Path�������jdk��binĿ¼C:\Program\Java\jdk1.7.0_05\bin
2.3����hadoop
��hadoop1.0.2.tar.gz��ѹ��cygwin��Ŀ¼��,�����ҷ�����/home/root/,����confĿ¼��3���ļ�
2.3.1 hadoop-env.sh
����������JAVA_HOME��·��,����ע�Ͳ�����д��ʾ��,�ҵ���export JAVA_HOME=C:\\Program\\Java\\jdk1.7.0_05\\jre
2.3.2 core-site.xml
��configuration�ڵ������������property�ڵ�
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9100</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
<description>A base for other temporary directories</description>
</property>
��һ��ָ��hadoop filesystem��·��,�˿ںſ����Լ�����;�ڶ���ָ��fs�Ĵ洢λ��
2.3.3mapred-site.xml
��configuration�ڵ��������property�ڵ�
<property>
<name>mapred.job.tracker</name>
<value>localhost:9101</value>
</property>
�����ָ��mapreduce��ʱ���jobtrack·��,�˿��Լ���
2.4����hadoop
��һ��bash����hadoop��binĿ¼��,���ȳ�ʼ��filesystem�����ݽڵ�,����./hadoop namenode -format;��ɺ�����./start-all.sh,���û�г����д������Ϣ�Ϳ���ʹ��
./hadoop fs -ls / �����hadoop �ļ�ϵͳ��
3.����eclipse����hadoop
3.1��װeclipse hadoop���
�ڸ����������Ҵӱ��������ºõ�hadoop-eclipse-plugin-1.0.2.jar������ֱ�Ӵ������ҵ���,�����ŵ�eclipse��pluginsĿ¼��,��eclipse��Window->open perspective����Ϳ��Կ���һ������ͼ����Map/Reduceѡ��,ѡ������consoleͬ������Ĵ��ھͿ��Կ���һ��mapreduce location������,�Ҽ��½�һ��,
location name: localhost
Map/Reduce master�˿�:9101(�Լ����õĶ�Ӧ�˿�)
dfs master�˿�:9100
user name:root?
?
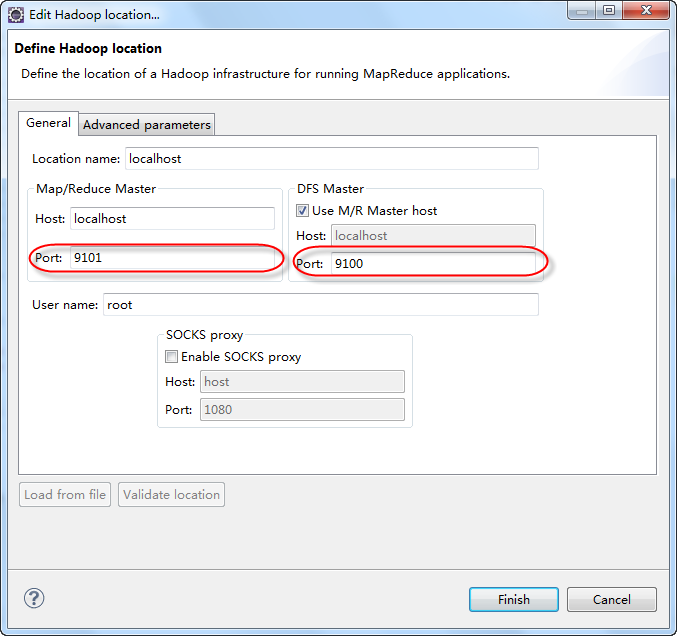
?
�����½�����,�����������ʾProject Explorer���ھͿ��Կ���һ��Dfs location��ѡ����,�㿪�����ȷ�Ϳ��Կ���֮ǰ��õ�hadoop��Ŀ¼�ṹ���ļ���
4.����eclipse����mapreduce

?
��Ŀ¼ˢ���ſɿ������ڴ˴�Ҫ��ˢ�¡�
�������������Ľ���HDFS�ֲ�ʽ�ļ�ϵͳ�Ĺ������ϴ���ɾ���Ȳ�����
Ϊ���������������Ҫ�Ƚ���һ��Ŀ¼ user/root/input2��Ȼ���ϴ�����txt�ļ�����Ŀ¼��
intput1.txt ��Ӧ���ݣ�Hello Hadoop Goodbye Hadoop
intput2.txt ��Ӧ���ݣ�Hello World Bye World
HDFS�����������ˣ�������Կ�ʼ�����ˡ�
Hadoop����
�½�һ��Map/Reduce Project���̣��趨�ñ��ص�hadoopĿ¼

?
�½�һ��������WordCountTest��
?
package com.hadoop.learn.test; import java.io.IOException;import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;import org.apache.log4j.Logger; /** * ���в��Գ��� * * @author yongboy * @date 2012-04-16 */public class WordCountTest { private static final Logger log = Logger.getLogger(WordCountTest.class); public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { log.info("Map key : " + key); log.info("Map value : " + value); StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { String wordStr = itr.nextToken(); word.set(wordStr); log.info("Map word : " + wordStr); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { log.info("Reduce key : " + key); log.info("Reduce value : " + values); int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); log.info("Reduce sum : " + sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args) .getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: WordCountTest <in> <out>"); System.exit(2); } Job job = new Job(conf, "word count"); job.setJarByClass(WordCountTest.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }}
?
?�Ҽ���ѡ��Run Configurations��,�������ڣ������Arguments��ѡ�,�ڡ�Program argumetns����Ԥ���������:
?
hdfs://localhost:9100/user/root/input2 hdfs://localhost:9100/user/root/output2
?

?
��ע������Ϊ���ڱ��ص���ʹ�ã�������ʵ������
Ȼ�����Apply����Ȼ��Close�������ڿ����Ҽ���ѡ��Run on Hadoop�������С�
����ʱ����������쳣��Ϣ��
?
12/04/24 15:32:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable12/04/24 15:32:44 ERROR security.UserGroupInformation: PriviledgedActionException as:Administrator cause:java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator-519341271\.staging to 0700Exception in thread "main" java.io.IOException: Failed to set permissions of path: \tmp\hadoop-Administrator\mapred\staging\Administrator-519341271\.staging to 0700 at org.apache.hadoop.fs.FileUtil.checkReturnValue(FileUtil.java:682) at org.apache.hadoop.fs.FileUtil.setPermission(FileUtil.java:655) at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:509) at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:344) at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:189) at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:116) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:856) at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:850) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:396) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1093) at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:850) at org.apache.hadoop.mapreduce.Job.submit(Job.java:500) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:530) at com.hadoop.learn.test.WordCountTest.main(WordCountTest.java:85)
?
�����Windows���ļ�Ȩ�����⣬��Linux�¿����������У����������������⡣
�����ṩһ���İ��hadoop-core-1.0.2.jar�ļ������ļ��ڱ��ĵĸ����С����滻ԭC:\cygwin\home\root\hadoop-1.0.2\hadoop-core-1.0.2.jar���ɡ�
�滻֮��ˢ����Ŀ�����ú���ȷ��jar������������������WordCountTest�����ɡ�
�ɹ�֮����Eclipse��ˢ��HDFSĿ¼�����Կ���������ouput2Ŀ¼��

?
����� part-r-00000���ļ������Կ�����������
?
Bye 1Goodbye 1Hadoop 2Hello 2World 2