今天我们说一下Redis中最后一个数据类型 “有序集合类型”,回首之前学过的几个数据结构,不知道你会不会由衷感叹,开源的世界真好,写这
些代码的好心人真的要一生平安哈,不管我们想没想的到的东西,在这个世界上都已经存在着,曾几何时,我们想把所有数据按照数据结构模式组成
后灌输到内存中,然而为了达到内存共享的方式,不得不将这块内存包装成wcf单独部署,同时还要考虑怎么序列化,何时序列互的问题,烦心事太多
太多。。。后来才知道有redis这么个吊毛玩意,能把高级的,低级的数据结构单独包装到一个共享内存中(Redis),高级的数据结构,就是本篇所
说的 “有序集合”,和C#中的SortDictionary相对应,下面我来具体聊一聊。
一: 有序集合(SortedSet)
可能有些初次接触SortedSet集合的人可能会说,这个集合的使用场景都有哪些??? 我可以明确的告诉你:“范围查找“的天敌就是”有序集合“,
任何大数据量下,查找一个范围的时间复杂度永远都是 O[(LogN)+M],其中M:返回的元素个数。
为了从易到难,我们还是先看一下redis手册,挑选几个我们常用的方法观摩观摩效果。。。
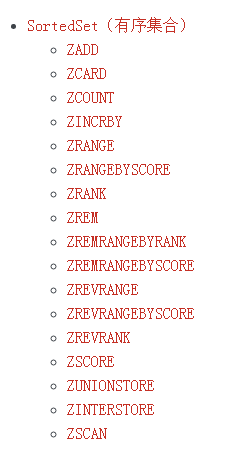
从上面17个命令中,毫无疑问,常用的命令为ZADD,ZREM,ZRANGEBYSCORE,ZRANGE。
1. ZADD
ZADD key score member [[score member] [score member] ...]将一个或多个 member 元素及其 score 值加入到有序集 key 当中。这个是官方的解释,赋值方式和hashtable差不多,只不过这里的key是有序的而已。下面我举个例子:我有一个fruits集合,其中记录了每个水
果的price,然后我根据price的各种操作来获取对应的水果信息。
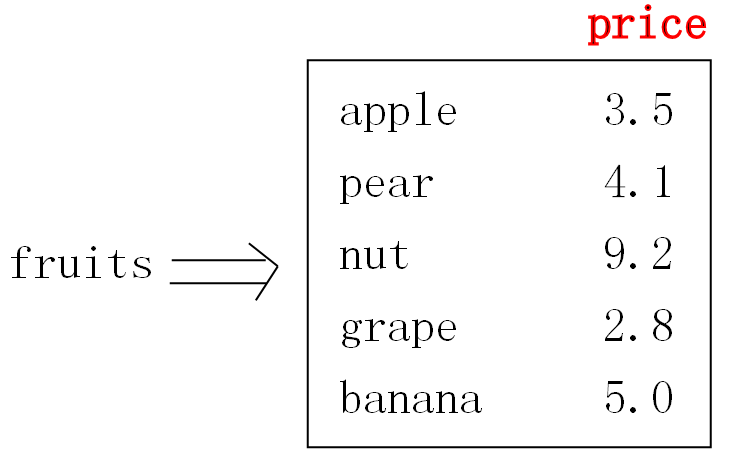
有了上面的基本信息,接下来我逐一送他们到SortedSet中,如下图:
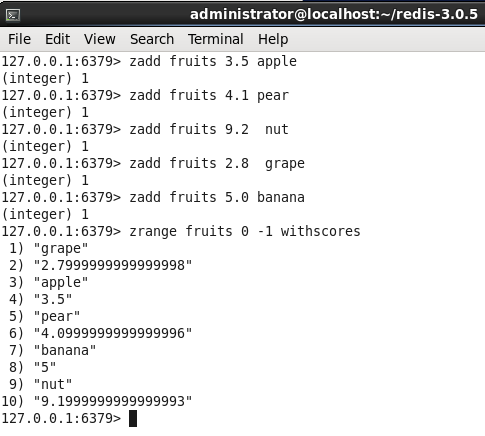
从上面的图中,不知道你有没有发现到什么异常???至少有两种。
<1> 浮点数近似值的问题,比如grape,我在add的时候,写明的是2.8,在redis中却给我显示近似值2.79999....,这个没关系,本来就是这样。
<2> 默认情况下,SortedSet是以key的升序排序的方式进行存放。
2. ZRANGE,ZREVRANGE
ZRANGE key start stop [WITHSCORES]返回有序集 key 中,指定区间内的成员。其中成员的位置按 score 值递增(从小到大)来排序。上面就是ZRange的格式模版,前面我在说ZAdd的时候其实我也已经说了,但是这个不是重点,在说ZAdd的时候留下了一个问题就是ZRange
默认是按照key升序排序的,对吧,那如果你想倒序显示的话,怎么办呢???其实你可以使用ZRange的镜像方法ZREVRANGE 即可,如下图:
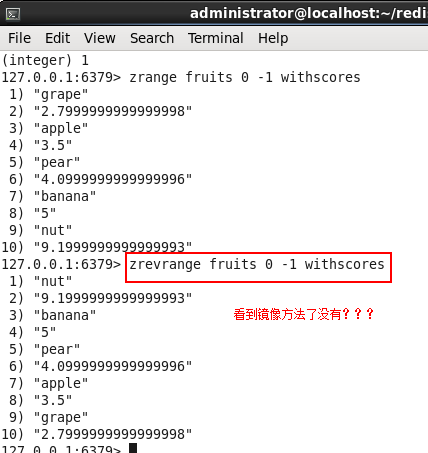
3. ZRANGEBYSCORE
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。这个算是对SortedSet来说最最重要的方法了,文章开头我也说了,有序集合最利于范围查找,既然是查找,你得有条件对吧,下面我举个例子:
<1> 我要找到1-4块钱的水果种类,理所当然,我会找到【葡萄,苹果】,如下图:
1 127.0.0.1:6379> zrangebyscore fruits 1 4 withscores2 1) "grape"3 2) "2.7999999999999998"4 3) "apple"5 4) "3.5"6 127.0.0.1:6379>
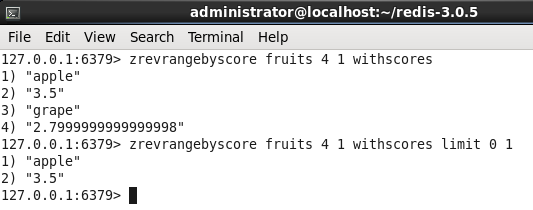
<2> 我要找到1-4区间中最接近4块的水果是哪个??? 这个问题就是要找到apple这个选项,那如果找到呢??? 仔细想想我可以这么做,
将1-4区间中的所有数倒序再取第一条数据即可,对吧,如下图:
127.0.0.1:6379> zrevrangebyscore fruits 4 1 withscores1) "apple"2) "3.5"3) "grape"4) "2.7999999999999998"127.0.0.1:6379> zrevrangebyscore fruits 4 1 withscores limit 0 11) "apple"2) "3.5"127.0.0.1:6379>
4. ZREM
ZREM key member [member ...]移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。当 key 存在但不是有序集类型时,返回一个错误。跟其他方法一样,zrem的目的就是删除指定的value成员,比如这里我要删除scores=3.5 的 apple记录。
127.0.0.1:6379> zrem fruits apple(integer) 1127.0.0.1:6379> zrange fruits 0 -1 withscores1) "grape"2) "2.7999999999999998"3) "pear"4) "4.0999999999999996"5) "banana"6) "5"7) "nut"8) "9.1999999999999993"127.0.0.1:6379>
你会发现,已经没有apple的相关记录了,因为已经被我删除啦。。。
二:探索原理
简单的操作都已经演示完毕了,接下来探讨下sortedset到底是由什么数据结构支撑的,大家应该早有耳闻,sortedset在CURD的摊还分析上
都是Log(N)的复杂度,可以与平衡二叉树媲美,它就是1987年才出来的新型高效数据结构“跳跃表(SkipList)”,SkipList牛逼的地方在于跳出了树模
型的思维,用多层链表的模式构造了Log(N)的时间复杂度,层的高度增加与否,采用随机数的模式,这个和 ”Treap树“ 的思想一样,用它来保持”树“
或者”链表”的平衡。
详细的我就不说了哈,不然的话又是一篇文章啦,如果非要了解的话,大家可以参见一下百度百科:http://baike.baidu.com/link?url=I8F7T
W933ZjIeBea_-dW9KeNsfKXMni0IdwNB10N1qnVfrOh_ubzcUpgwNVgRPFw3iCkhewGaYjM_o51xchS8a
我大概看了下百科里面画的这张图,就像下面这样:
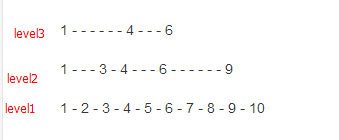
这幅图中有三条链,对吧,在SkipList中是必须要保证每条链中的数据必须有序才可以,这是必须的。
1. 如果要在level1层中找到节点6,那么你需要逐一遍历,需要6次查找才能正确的找到数据。
2. 如果你在level2层中找到节点6的话,那么你需要4次才能找到。
3. 如果你在level3层中找到节点6的话,那么你需要3次就可以找到。。。。
现在宏观理解上,是不是有一种感觉,如果level的层数越高,相对找到数据需要遍历的次数就越少,对吧,这就是跳跃表的思想,不然怎么跳哈,
接下来我们来看看redis中是怎么定义这个skiplist的,它的源码在redis.h 中:
1 /* ZSETs use a specialized version of Skiplists */ 2 typedef struct zskiplistNode { 3 robj *obj; 4 double score; 5 struct zskiplistNode *backward; 6 struct zskiplistLevel { 7 struct zskiplistNode *forward; 8 unsigned int span; 9 } level[];10 } zskiplistNode;11 12 typedef struct zskiplist {13 struct zskiplistNode *header, *tail;14 unsigned long length;15 int level;16 } zskiplist;
从源码中可以看出如下几点:
<1> zskiplistnode就是skiplist中的node节点,节点中有一个level[]数组,如果你够聪明的话,你应该知道这个level[]就是存放着上图中
的 level1,level2,level3 这三条链。
<2> level[]里面是zskiplistLevel实体,这个实体中有一个 *forward指针,这个指针就是指向同层中的后续节点。
<3> 在zskiplistLevel中还有一个 robj类型的*obj指针,这个就是RedisObject对象哈,里面存放的就是我们的value值,接下来还有一个
score属性,这个就是key值啦。。。skiplist就是根据它来进行排序的哈。
<4> 接下来就是第二个枚举zskiplist,这个没什么意思,纯粹的包装层,比如里面的length是记录skiplist中的节点个数,level记录skiplist
当前的层数,用*header,*tail记录skiplist中的首节点和尾节点。。。仅此而已。。。
好了,不管你听懂没听懂,大体上就这样了。。。上班去啦~~~
- 1楼HBird
- 如果想根据多个维度进行排序,如何解决?
- Re: 一线码农
- @HBird,这个毕竟是kv模式,做不了的哈。
- Re: ~Kewell
- @HBird,多个维度赋予不同权重,加权后就可以在一个维度里面排序了