再说一下目前的主要环境信息和版本:
操作系统:win7 64位
python版本:2.7.6
RIDE版本:1.2.3
selenium2library:1.5.0
selenium:2.40.0
pip:1.5.4
setuptools:0.6c11
decorator:3.4.0
robotframework:2.8.4
wx:2.8-unicode
wx:3.0
IEDiverServer:2.41.0
注意:除操作系统外,各软件都是32位的版本。
现在说下如何用ride分层测试案例和截图以及一些需要注意的细节
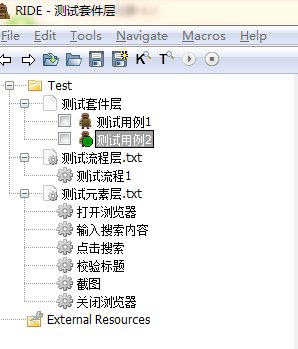
上图中我们分了三层,测试元素层放的是我们的测试步骤,测试流程层放的是测试步骤的组合,测试套件层放的是我们的测试案例(测试用例)
我们的测试用例2用了分层的逻辑,测试用例1用的未分层的
测试用例1的内容:
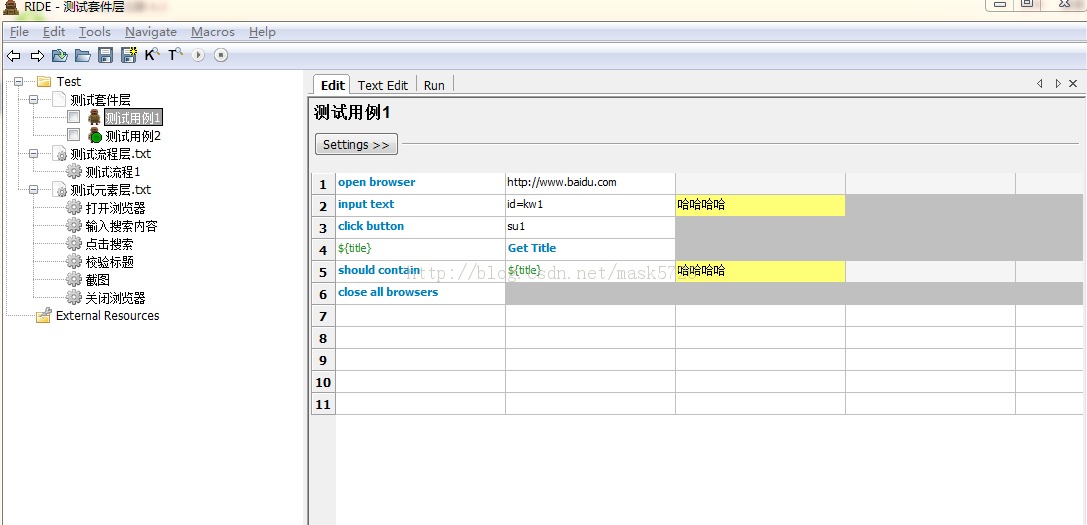
如图 ,我们首先打开浏览器,输入百度的url,然后输入搜索的内容哈哈哈哈,然后对页面标题进行验证,最后关闭浏览器。
那 么在分层设计下是什么样的,看测试用例2:
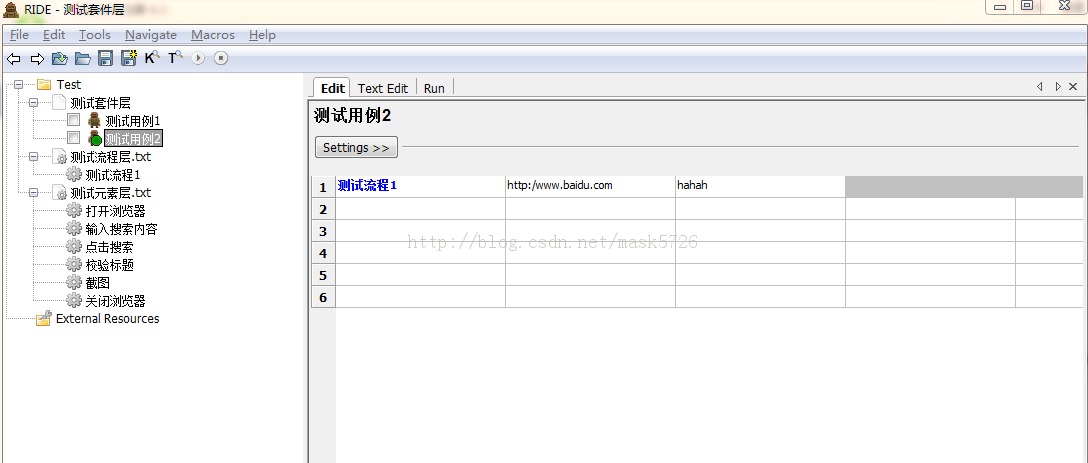
只有一行数据,后面是输入的参数,调用的是测试流程1
再看测试流程1:
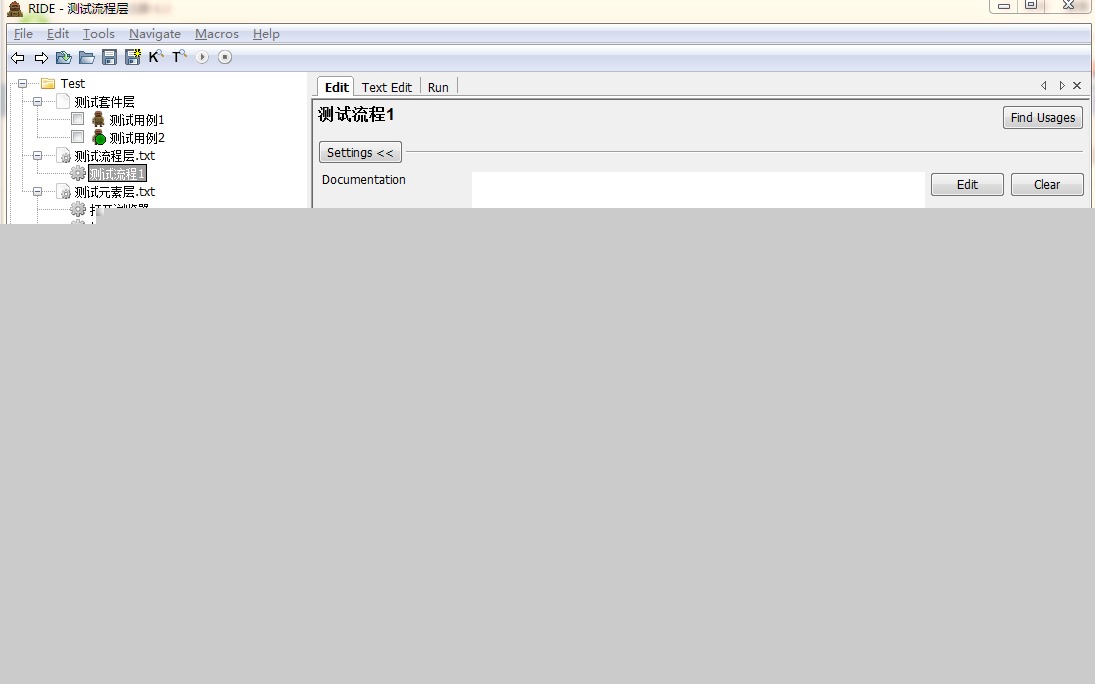
我们加了两个参数,所以测试用例2中需要输入两个参数的值,步骤中引用的就是测试元素层中的关键字了,我们逐条的看下,
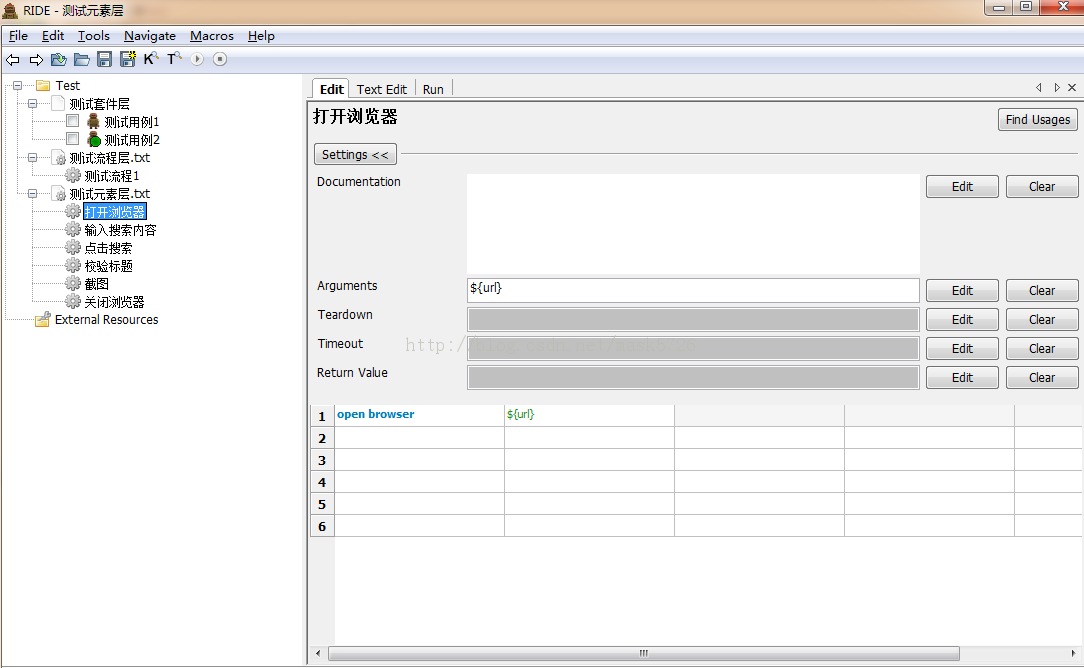
打开浏览器:
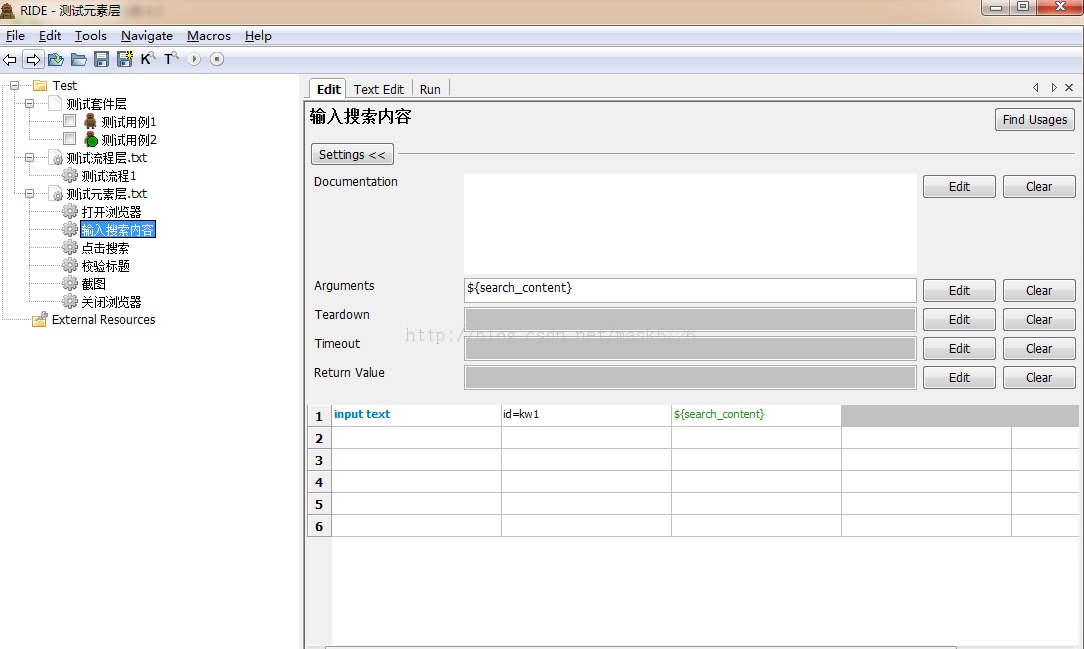
输入搜索内容:
点击搜索: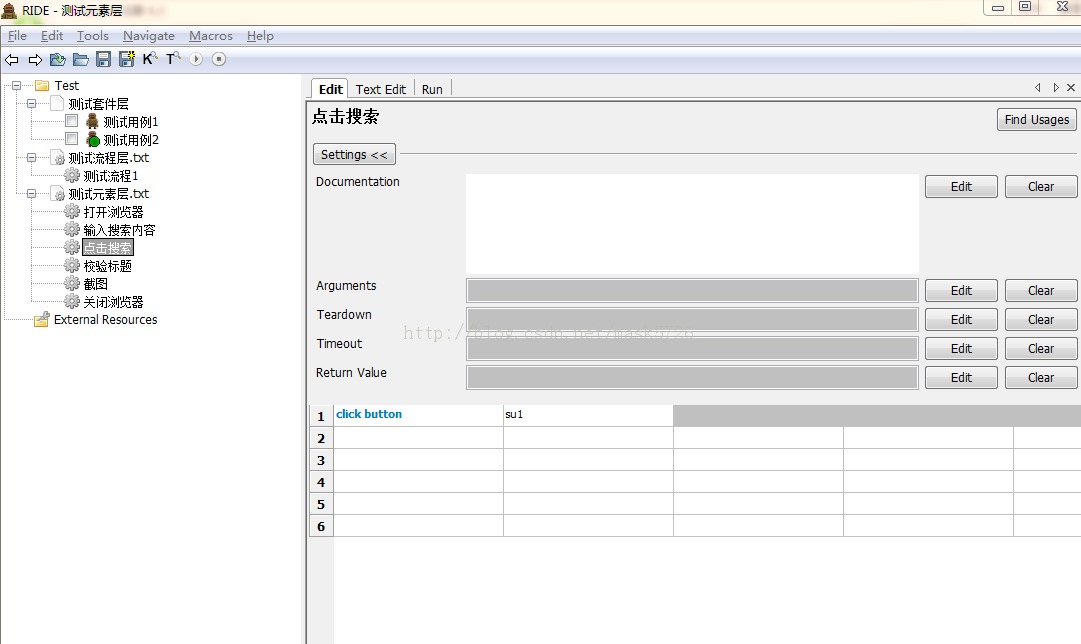
校验标题: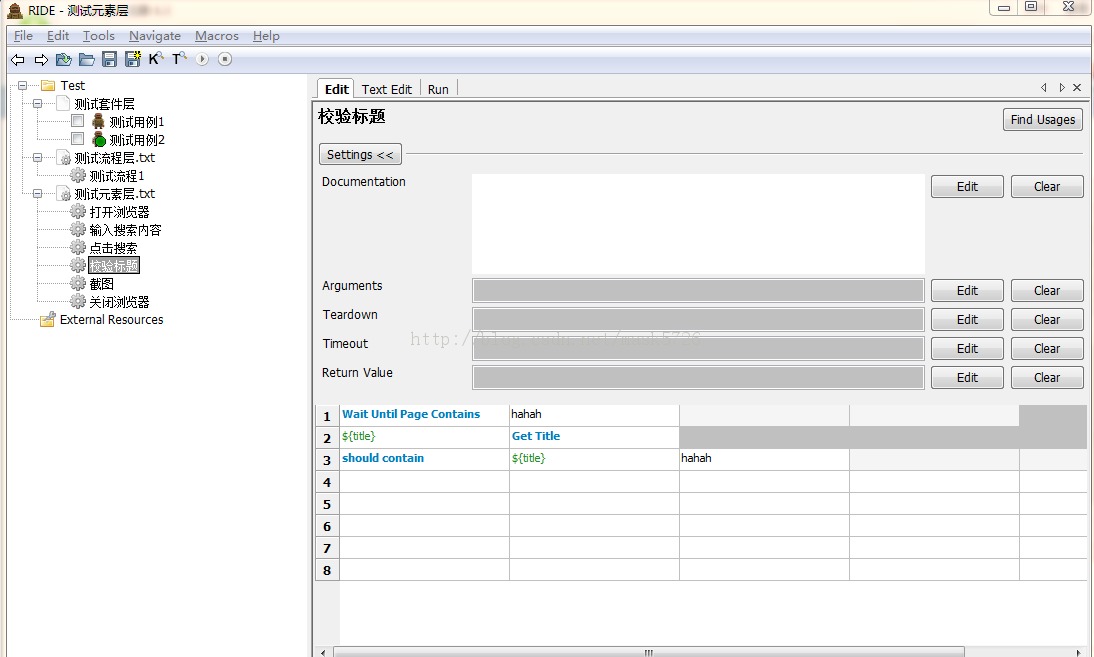
这个步骤1加入了等待页面显示hahah这个内容,如果不加这一步,得到的标题就会是“百度一下”,而不是我们希望的,这个熟悉selenium的应该很清楚,selenium有这个步骤太快导致还没有出现我们希望的结果时就进行get title操作,所以我们显示声明一下出现这个结果后,在进行get title,这样就不会因为运行太快或者其他原因导致预期结果和实际结果不一致的现象。
截图:
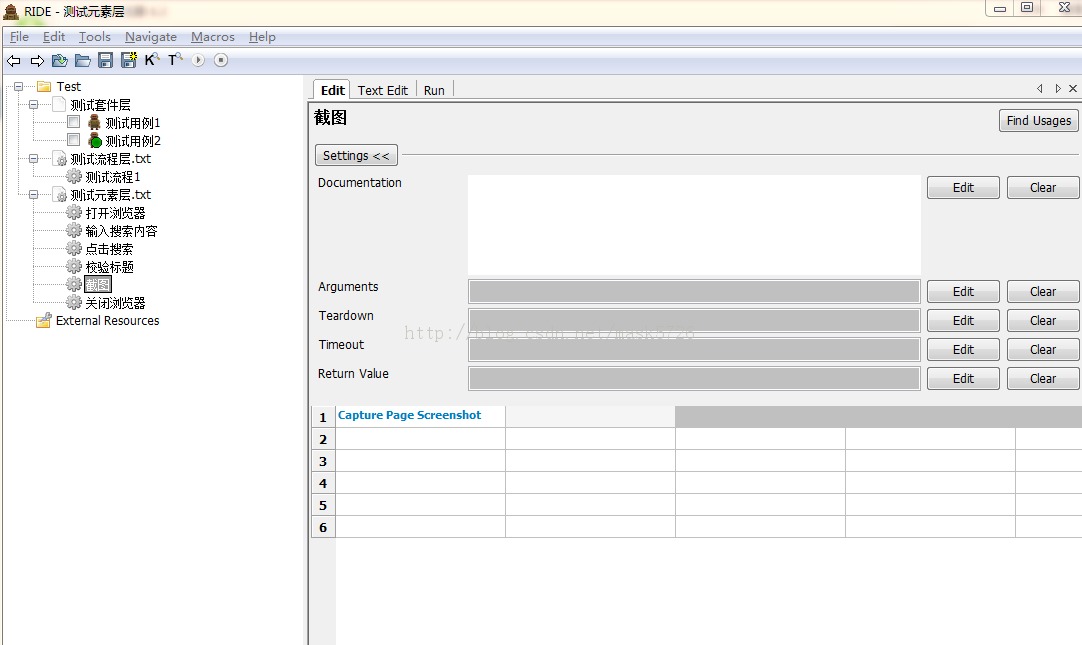
自动化测试有时候需要通过截图来检测页面是否变形等,或者出错时加入截图,方便查看。我们在此地加入截图后,在测试报告中会看到
关闭浏览器:

完了,这就是整个分层步骤,有些地方有了参数,有些没用,比如预期结果是写死的,这个可以根据实际情况自行修改,也可以根据实际情况自行分层,等待页面显示内容和截图方法需要注意,我们在步骤中写入的都是关键字,selenium2library的关键字使用文档,可以在ride上面按ctrl查看,给一个连接,是selenium2library 1.5.0的api在线地址,方便我们查看:http://rtomac.github.io/robotframework-selenium2library/doc/Selenium2Library.html
最后,需要注意如果我们使用截图的时候没有指明保存的目录,我们的截图就会放在与报告一样的目录下
在报告中点开截图关键字就可以看到我们的截图:,因为图片太多超过限制了,自己看看吧,这里就不贴上了。