1.综述
现有的轨迹聚类算法可分为两类:一种是基于整体的轨迹聚类,即将一条轨迹视为一个整体而对其不做分段,通过定义轨迹的相似度函数将其聚类,这样一条轨迹只能属于一个簇;另一种是基于分段的轨迹聚类,即将一条轨迹分为多段,分段的轨迹之和不一定是原轨迹,也可以是原轨迹特征的抽取。之后再进行轨迹聚类,这样同一条轨迹可能分属于多个簇,可视的结果会出现分流与聚流的效果。
基于不同的应用场景会运用不同的算法,如果只从准确度上评价而不考虑其它因素,基于分段的轨迹聚类相对更好一此。因为它研究的粒度更细,而基于整体的轨迹聚类会丢失一些细节信息,举一个例子: 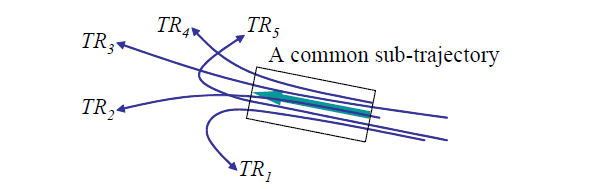
如上图,有五条轨迹
基于此,原文提出了“分段及归组”的轨迹聚类框架,正如其名,算法分为两大步:
1. 分段:将轨迹进行分段以作为下一阶段的输入;
2. 归组:相似的线段归为一类。归类的算法采用基于密度的聚类算法,本文采用的是DBSCAN算法,若不熟悉该算法可查看我的前一篇博客。
http://blog.csdn.net/jsc9410/article/details/51004057 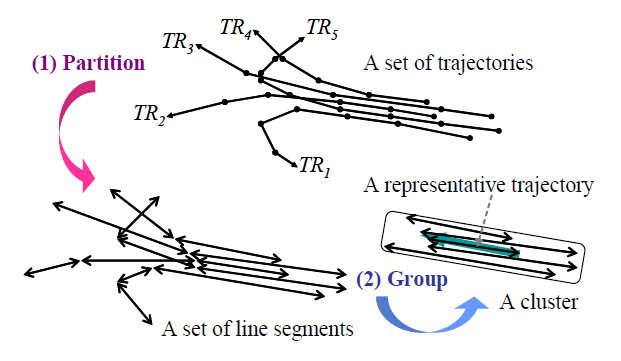
2. 轨迹聚类
2.1 TRACLUS算法
原文将该算法概括如下: 
2.2轨迹距离函数
由于DBSCAN算法是基于密度的算法,对于散点的聚类利用欧氏距离衡量就可以,但轨迹就不同如此。因此必须事先定义轨迹之间的距离。
给定任意的两条线段,其长度及方向不一定相同,如何衡量它们之间的相似度?
先从简单的开始,情况一:给定两条同等长度相互平行且两起点的连线或两终点的连线与这两条线段垂直,那么我们可以用它们之间的垂直距离
若在上面的基础上,情况二:将两条线段沿其方向错位或改变其中一条线段的长度,在同等
若在情况二的基础上,情况三:将其中一条线段沿某一方向旋转,则两条线段的夹角越大,其相似度越小,因此又需要引入夹角距离
原文对距离的定义就基于这种思想。 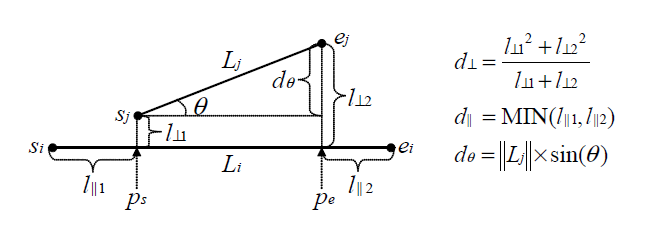
三者的定义如下:
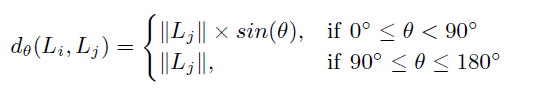
第三个公式考虑了轨迹的方向,当夹角大于90度时可视为极不相似,如果不考虑轨迹的方向时,可以用
将三个部分综合起来就是:
3.轨迹分段
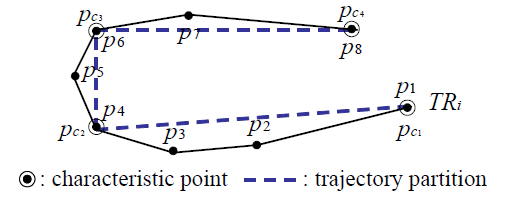
轨迹分段是在原轨迹中选取一些特征点,利用特征点的连线来近似原轨迹。特征点是多指轨迹中角度变化较大的点。
对轨迹的分段要保证两个性质:准确性和简洁性。
准确性是指特征点不能太少,否则不足以概括轨迹特征;
简洁性是指特征点要利用尽可能少的点来概括轨迹特征。
这两个特性相互矛盾,因此算法要能够很好地平衡这两个特性。
3.1 MDL原则
原文采用信息压缩中广泛采用的标准来平衡:MDL(Minimum Description Length)原则。
最小描述长度( MDL) 原理是 Rissane 在研究通用编码时提出的。其基本原理是对于一组给定的实例数据 D , 如果要对其进行保存 ,为了节省存储空间, 一般采用某种模型H对其进行编码压缩,然后再保存压缩后的数据。同时, 为了以后正确恢复这些实例数据,将所用的模型也保存起来。所以需要保存的数据长度( 比特数) 等于这些实例数据进行编码压缩后的长度加上保存模型所需的数据长度,将该数据长度称为总描述长度。最小描述长度( MDL) 原理就是要求选择总描述长度最小的模型。
MDL原则包含两个部分:
1.
2.
原文中对两部分的定义如下: 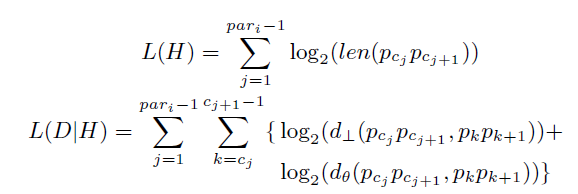
L(D|H)中没有包含水平距离是因为对于闭合的两条线段,其水平距离为零。
例如: 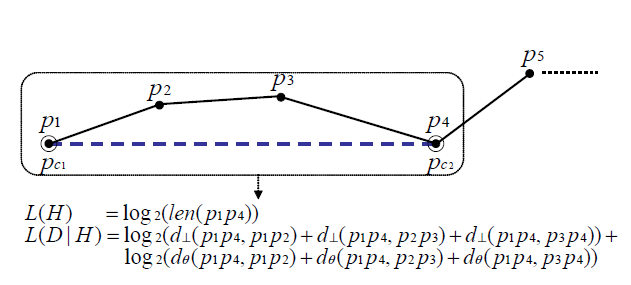
3.2 算法描述
完整的算法描述如下: 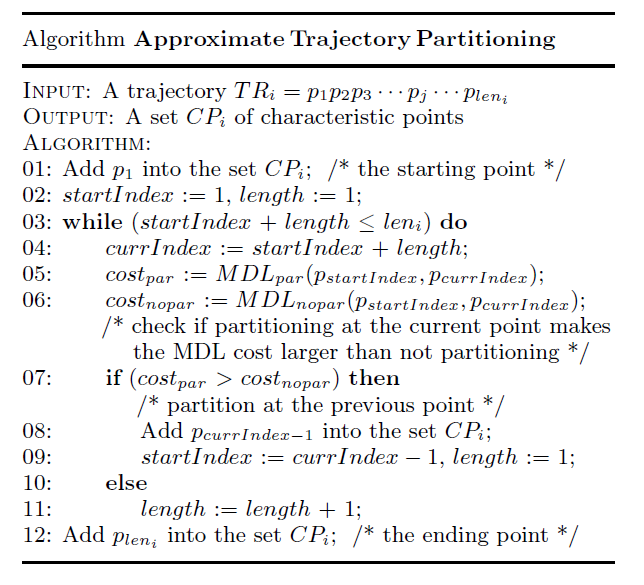
其中
Reference:
Trajectory Clustering: A Partition-and-Group Framework,Jae-Gil Lee, Jiawei Han,Kyu-Young Whang