数据科学家需要具备专业领域知识并研究相应的算法以分析对应的问题,而数据挖掘是其必须掌握的重要技术。以帮助创建推动业务发展的相应大数据产品和大数据解决方案。EMC最近的一项调查也证实了这点。调查结果显示83%的人认为大数据浪潮所催生的新技术增加了数据科学家的需求。本文将为您展示如何基于一个简单的公式查找相关的项目。请注意,此项技术适用于所有的网站(如亚马逊),以个性化用户体验、提高转换效率。
查找相关项问题
要想为一个特定的项目查找相关项,就必须首先为这两个项目定义相关之处。而这些也正是你要解决的问题:
- 在博客上,你可能想以标签的形式分享文章,或者对比查看同一个人阅读过的文章
- 亚马逊站点被称为“购买此商品的客户还购买了”的部分
- 一个类似于IMDB(Internet Movie Database)的服务,可以根据用户的评级,给出观影指南建议
不论是标签、购买的商品还是观看的电影,我们都要对其进行分门别类。这里我们将采用标签的形式,因为它很简单,而且其公式也适用于更复杂的情形。
以几何关系重定义问题
现在以我的博客为例,来列举一些标签:
- ["API",?"Algorithms",?"Amazon",?"Android",?"Books",?"Browser"]??
好,我们来看看在欧式空间几何学中如何表示这些标签。
我们要排序或比较的每个项目在空间中以点表示,坐标值(代表一个标签)为1(标记)或者0(未标记)。
因此,如果我们已经获取了一篇标签为“API”和“Browser”的文章,那么其关联点是:
- [?1,?0,?0,?0,?0,?1?]?
现在这些坐标可以表示其它含义。例如,他们可以代表用户。如果在你的系统中有6个用户,其中2个用户对一篇文章分别评了3星和5星,那么你就可以针对此文章查看相关联的点(请注意顺序):
- [?0,?3,?0,?0,?5,?0?]?
现在我们可以计算出相关矢量之间的夹角,以及这些点之间的距离。下面是它们在二维空间中的图像:
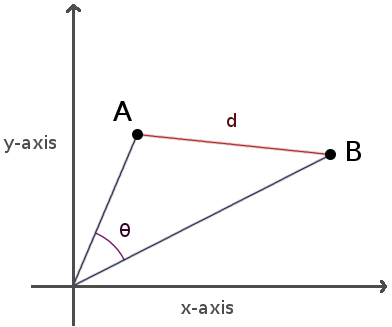
欧式几何空间距离
计算欧式几何空间两点之间距离的数学公式非常简单。考虑相关两点A、B之间的距离:
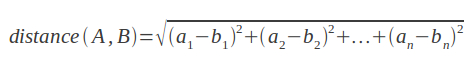
两点之间的距离越近,它们的相关性越大。下面是Ruby代码:
- #?Returns?the?Euclidean?distance?between?2?points ?
- # ?
- #?Params: ?
- #??-?a,?b:?list?of?coordinates?(float?or?integer) ?
- # ?
- def?euclidean_distance(a,?b) ?
- ??sq?=?a.zip(b).map{|a,b|?(a?-?b)?**?2} ?
- ??Math.sqrt(sq.inject(0)?{|s,c|?s?+?c}) ?
- end?
- #?Returns?the?associated?point?of?our?tags_set,?relative?to?our ?
- #?tags_space. ?
- # ?
- #?Params: ?
- #??-?tags_set:?list?of?tags ?
- #??-?tags_space:?_ordered_?list?of?tags ?
- def?tags_to_point(tags_set,?tags_space) ?
- ??tags_space.map{|c|?tags_set.member?(c)???1?:?0} ?
- end?
- #?Returns?other_items?sorted?by?similarity?to?this_item? ?
- #?(most?relevant?are?first?in?the?returned?list) ?
- # ?
- #?Params: ?
- #??-?items:?list?of?hashes?that?have?[:tags] ?
- #??-?by_these_tags:?list?of?tags?to?compare?with ?
- def?sort_by_similarity(items,?by_these_tags) ?
- ??tags_space?=?by_these_tags?+?items.map{|x|?x[:tags]}?? ?
- ??tags_space.flatten!.sort!.uniq! ?
- ??this_point?=?tags_to_point(by_these_tags,?tags_space) ?
- ??other_points?=?items.map{|i|? ?
- ????[i,?tags_to_point(i[:tags],?tags_space)] ?
- ??} ?
- ?
- ??similarities?=?other_points.map{|item,?that_point| ?
- ????[item,?euclidean_distance(this_point,?that_point)] ?
- ??} ?
- ??sorted?=?similarities.sort?{|a,b|?a[1]?<=>?b[1]} ?
- ??return?sorted.map{|point,s|?point} ?
- End?
这是一些示例代码,你可以直接复制运行:
- #?SAMPLE?DATA ?
- ?
- all_articles?=?[ ?
- ??{ ?
- ???:article?=>?"Data?Mining:?Finding?Similar?Items",? ?
- ???:tags?=>?["Algorithms",?"Programming",?"Mining",? ?
- ?????"Python",?"Ruby"] ?
- ??},? ?
- ??{ ?
- ???:article?=>?"Blogging?Platform?for?Hackers",?? ?
- ???:tags?=>?["Publishing",?"Server",?"Cloud",?"Heroku",? ?
- ?????"Jekyll",?"GAE"] ?
- ??},? ?
- ??{ ?
- ???:article?=>?"UX?Tip:?Don't?Hurt?Me?On?Sign-Up",? ?
- ???:tags?=>?["Web",?"Design",?"UX"] ?
- ??},? ?
- ??{ ?
- ???:article?=>?"Crawling?the?Android?Marketplace",? ?
- ???:tags?=>?["Python",?"Android",?"Mining",? ?
- ?????"Web",?"API"] ?
- ??} ?
- ] ?
- ?
- #?SORTING?these?articles?by?similarity?with?an?article? ?
- #?tagged?with?Publishing?+?Web?+?API ?
- # ?
- # ?
- #?The?list?is?returned?in?this?order: ?
- # ?
- #?1.?article:?Crawling?the?Android?Marketplace ?
- #????similarity:?2.0 ?
- # ?
- #?2.?article:?"UX?Tip:?Don't?Hurt?Me?On?Sign-Up" ?
- #????similarity:?2.0 ?
- # ?
- #?3.?article:?Blogging?Platform?for?Hackers ?
- #????similarity:?2.645751 ?
- # ?
- #?4.?article:?"Data?Mining:?Finding?Similar?Items" ?
- #????similarity:?2.828427 ?
- # ?
- ?
- sorted?=?sort_by_similarity( ?
- ????all_articles,?['Publishing',?'Web',?'API']) ?
- ?
- require?'yaml'?
- puts?YAML.dump(sorted)?
你是否留意到我们之前选择的数据存在一个缺陷?前两篇文章对于标签“["Publishing",?"Web",?"API"]”有着相同的欧氏几何空间距离。
为了更加形象化,我们来看看计算第一篇文章所用到的点:
- [1,?0,?0,?0,?0,?0,?0,?0,?0,?0,?1,?0,?0,?0,?0,?1] ?
- [1,?0,?1,?0,?0,?0,?0,?0,?1,?0,?0,?1,?0,?0,?0,?1]?
只有四个坐标值不同,我们再来看看第二篇文章所用到的点:
- [1,?0,?0,?0,?0,?0,?0,?0,?0,?0,?1,?0,?0,?0,?0,?1] ?
- [0,?0,?0,?0,?1,?0,?0,?0,?0,?0,?0,?0,?0,?0,?1,?1]?
与第一篇文章相同,也只有4个坐标值不同。欧氏空间距离的度量取决于点之间的差异。这也许不太好,因为相对平均值而言,有更多或更少标签的文章会处于不利地位。
余弦相似度
这种方法与之前的方法类似,但更关注相似性。下面是公式:
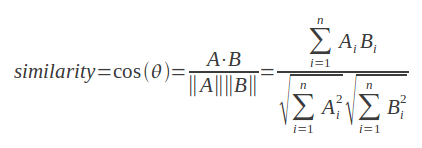
下面是Ruby代码:
- def?dot_product(a,?b) ?
- ??products?=?a.zip(b).map{|a,?b|?a?*?b} ?
- ??products.inject(0)?{|s,p|?s?+?p} ?
- end?
- ?
- def?magnitude(point) ?
- ??squares?=?point.map{|x|?x?**?2} ?
- ??Math.sqrt(squares.inject(0)?{|s,?c|?s?+?c}) ?
- end?
- ?
- #?Returns?the?cosine?of?the?angle?between?the?vectors? ?
- #associated?with?2?points ?
- # ?
- #?Params: ?
- #??-?a,?b:?list?of?coordinates?(float?or?integer) ?
- # ?
- def?cosine_similarity(a,?b) ?
- ??dot_product(a,?b)?/?(magnitude(a)?*?magnitude(b)) ?
- end?
对于以上示例,我们对文章进行分类得到:
- -?article:?Crawling?the?Android?Marketplace ?
- ??similarity:?0.5163977794943222 ?
- -?article:?"UX?Tip:?Don't?Hurt?Me?On?Sign-Up"?
- ??similarity:?0.33333333333333337 ?
- -?article:?Blogging?Platform?for?Hackers ?
- ??similarity:?0.23570226039551587 ?
- -?article:?"Data?Mining:?Finding?Similar?Items"?
- ??similarity:?0.0?
这种方法有了很大改善,我们的代码可以很好地运行,但它依然存在问题。
示例中的问题:Tf-ldf权重
我们的数据很简单,可以轻松地计算并作为衡量的依据。如果不采用余弦相似度,很可能会出现相同的结果。
Tf-ldf权重是一种解决方案。Tf-ldf是一个静态统计量,用于权衡文本集合中的一个词在一个文档中的重要性。
根据Tf-ldff,我们可以为坐标值赋予独特的值,而并非局限于0和1.
对于我们刚才示例中的简单数据集,也许更简单的度量方法更适合,比如Jaccard index也许会更好。
皮尔逊相关系数(Pearson?Correlation?Coefficient)
使用皮尔逊相关系数(Pearson?Correlation?Coefficient)寻找两个项目之间的相似性略显复杂,也并不是非常适用于我们的数据集合。
例如,我们在IMDB中有2个用户。其中一个用户名为John,对五部电影做了评级:[1,2,3,4,5]。另一个用户名为Mary,对这五部电影也给出了评级:[4,?5,?6,?7,?8]。这两个用户非常相似,他们之间有一个完美的线性关系,Mary的评级都是在John的基础上加3。
计算公式如下:
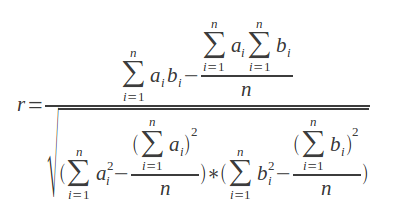
?代码如下:
- def?pearson_score(a,?b) ?
- ??n?=?a.length ?
- ??return?0?unless?n?>?0 ?
- ??#?summing?the?preferences ?
- ??sum1?=?a.inject(0)?{|sum,?c|?sum?+?c} ?
- ??sum2?=?b.inject(0)?{|sum,?c|?sum?+?c} ?
- ??#?summing?up?the?squares ?
- ??sum1_sq?=?a.inject(0)?{|sum,?c|?sum?+?c?**?2} ?
- ??sum2_sq?=?b.inject(0)?{|sum,?c|?sum?+?c?**?2} ?
- ??#?summing?up?the?product ?
- ??prod_sum?=?a.zip(b).inject(0)?{|sum,?ab|?sum?+?ab[0]?*?ab[1]} ?
- ??#?calculating?the?Pearson?score ?
- ??num?=?prod_sum?-?(sum1?*sum2?/?n)?? ?
- ??den?=?Math.sqrt((sum1_sq?-?(sum1?**?2)?/?n)?*?(sum2_sq?-?(sum2?**?2)?/?n)) ?
- ??return?0?if?den?==?0 ?
- ??return?num?/?den?? ?
- end?
- puts?pearson_score([1,2,3,4,5],?[4,5,6,7,8]) ?
- #?=>?1.0 ?
- puts?pearson_score([1,2,3,4,5],?[4,5,0,7,8]) ?
- #?=>?0.5063696835418333 ?
- puts?pearson_score([1,2,3,4,5],?[4,5,0,7,7]) ?
- #?=>?0.4338609156373132 ?
- puts?pearson_score([1,2,3,4,5],?[8,7,6,5,4]) ?
- #?=>?-1?
曼哈顿距离算法
没有放之四海而皆准的真理,我们所使用的公式取决于要处理的数据。下面我们简要介绍一下曼哈顿距离算法。
曼哈顿距离算法计算两点之间的网格距离,维基百科中的图形完美诠释了它与欧氏几何距离的不同:
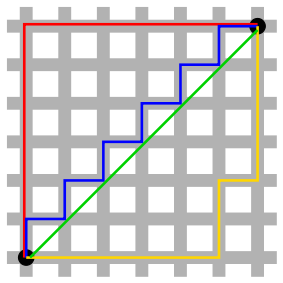
红线、黄线和蓝线是具有相同长度的曼哈顿距离,绿线代表欧氏几何空间距离