1.Apriori算法
如果一个事务中有X,则该事务中则很有可能有Y,写成关联规则
{X}→{Y}
将这种找出项目之间联系的方法叫做关联分析。关联分析中最有名的问题是购物蓝问题,在超市购物时,有一个奇特的现象――顾客在买完尿布之后通常会买啤酒,即{尿布}→{啤酒}。原来,妻子嘱咐丈夫回家的时候记得给孩子买尿布,丈夫买完尿布后通常会买自己喜欢的啤酒。
考虑到规则的合理性,引入了两个度量:支持度(support)、置信度(confidence),定义如下
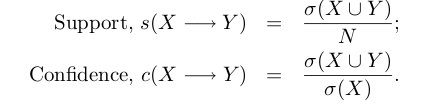
支持度保证项集(X, Y)在数据集出现的频繁程度,置信度确定Y在包含X中出现的频繁程度。
对于包含有d个项的数据集,可能的规则数为
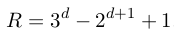
如果用brute-force的方法,计算代价太大了。为此,R. Agrawal与R. Srikant提出了Apriori算法。同大部分的关联分析算法一样,Apriori算法分为两步:
- 生成频繁项集,即满足最小支持度阈值的所有项集;
- 生成关联规则,从上一步中找出的频繁项集中找出搞置信度的规则,即满足最小置信度阈值。
class associationRule: def __init__(self,dataSet): self.sentences=map(set,dataSet) self.minSupport=0.5 self.minConf=0.98 self.numSents=float(len(self.sentences)) self.supportData={} self.L=[] self.ruleList=[] def createC1(self): """create candidate itemsets of size 1 C1""" C1=[] for sentence in self.sentences: for word in sentence: if not [word] in C1: C1.append([word]) C1.sort() return map(frozenset,C1) def scan(self,Ck): """generate frequent itemsets Lk from candidate itemsets Ck""" wscnt={} retList=[] #calculate support for every itemset in Ck for words in Ck: for sentence in self.sentences: if words.issubset(sentence): if not wscnt.has_key(words): wscnt[words]=1 else: wscnt[words]+=1 for key in wscnt: support=wscnt[key]/self.numSents if support>=self.minSupport: retList.append(key) self.supportData[key]=support self.L.append(retList) def aprioriGen(self,Lk,k): """the candidate generation: merge a pair of frequent (k ? 1)-itemsets only if their first k ? 2 items are identical """ retList=[] lenLk=len(Lk) for i in range(lenLk): for j in range(i+1,lenLk): L1=list(Lk[i])[:k-2]; L2=list(Lk[j])[:k-2] L1.sort(); L2.sort() if L1==L2: retList.append(Lk[i]|Lk[j]) return retList def apriori(self): """generate a list of frequent itemsets""" C1=self.createC1() self.scan(C1) k=2 while(k<=3): Ck=self.aprioriGen(self.L[k-2],k) self.scan(Ck) k+=1 def generateRules(self): """generate a list of rules""" for i in range(1,len(self.L)): #get only sets with two or more items for freqSet in self.L[i]: H1=[frozenset([word]) for word in freqSet] if(i>1): self.rulesFromConseq(freqSet,H1) else: self.calcConf(freqSet,H1) #set with two items def calcConf(self,freqSet,H): """calculate confidence, eliminate some rules by confidence-based pruning""" prunedH=[] for conseq in H: conf=self.supportData[freqSet]/self.supportData[freqSet-conseq] if conf>=self.minConf: print "%s --> %s, conf=%.3f"%(map(str,freqSet-conseq), map(str,conseq), conf) self.ruleList.append((freqSet-conseq,conseq,conf)) prunedH.append(conseq) return prunedH def rulesFromConseq(self,freqSet,H): """generate more association rules from freqSet+H""" m=len(H[0]) if len(freqSet)>m+1: #try further merging Hmp1=self.aprioriGen(H,m+1) #create new candidate Hm+1 hmp1=self.calcConf(freqSet,Hmp1) if len(Hmp1)>1: self.rulesFromConseq(freqSet,Hmp1)读取mushroom.dat数据集
def read_file(raw_file): """read file""" return [sorted(list(set(e.split()))) for e in open(raw_file).read().strip().split('\n')]def main(): sentences=read_file('test.txt') assrules=associationRule(sentences) assrules.apriori() assrules.generateRules()if __name__=="__main__": main()['76'] --> ['34'], conf=1.000
['34'] --> ['85'], conf=1.000
['36'] --> ['85'], conf=1.000
['24'] --> ['85'], conf=1.000
['53'] --> ['90'], conf=1.000
['53'] --> ['34'], conf=1.000
['2'] --> ['85'], conf=1.000
['76'] --> ['85'], conf=1.000
['67'] --> ['86'], conf=1.000
['76'] --> ['86'], conf=1.000
['67'] --> ['34'], conf=1.000
['67'] --> ['85'], conf=1.000
['90'] --> ['85'], conf=1.000
['86'] --> ['85'], conf=1.000
['53'] --> ['85'], conf=1.000
['53'] --> ['86'], conf=1.000
['39'] --> ['85'], conf=1.000
['34'] --> ['86'], conf=0.999
['86'] --> ['34'], conf=0.998
['63'] --> ['85'], conf=1.000
['59'] --> ['85'], conf=1.000
['53'] --> ['86', '85'], conf=1.000
['76'] --> ['34', '85'], conf=1.000
['53'] --> ['90', '34'], conf=1.000
['76'] --> ['86', '85'], conf=1.000
['53'] --> ['34', '85'], conf=1.000
['67'] --> ['34', '85'], conf=1.000
['76'] --> ['86', '34'], conf=1.000
['53'] --> ['86', '34'], conf=1.000
['67'] --> ['86', '34'], conf=1.000
['53'] --> ['90', '85'], conf=1.000
['67'] --> ['86', '85'], conf=1.000
['53'] --> ['90', '86'], conf=1.000
['86'] --> ['85', '34'], conf=0.998
['34'] --> ['86', '85'], conf=0.999
源代码在有些数据集上跑得很慢,还需要做一些优化。这里有一些用作关联分析测试的数据集。
2. Referrence
[1] Peter Harrington, machine learning in action.
[2] Tan, et al., Introduction to data minging.