Titanic是kaggle上的一道just for fun的题,没有奖金,但是数据整洁,拿来练手最好不过。
本文以 Titanic 的数据,使用较为简单的决策树,介绍处理数据大致过程、步骤
注意,本文的目的,在于帮助你入门数据挖掘,熟悉处理数据步骤、流程
决策树模型是一种简单易用的非参数分类器。它不需要对数据有任何的先验假设,计算速度较快,结果容易解释,而且稳健性强,对噪声数据和缺失数据不敏感。下面示范用kaggle竞赛titanic中的数据集为做决策树分类,目标变量为survive
读取数据
import numpy as npimport pandas as pddf = pd.read_csv('train.csv', header=0)数据整理
- 只取出三个自变量
- 将Age(年龄)缺失的数据补全
- 将Pclass变量转变为三个 Summy 变量
- 将sex转为0-1变量
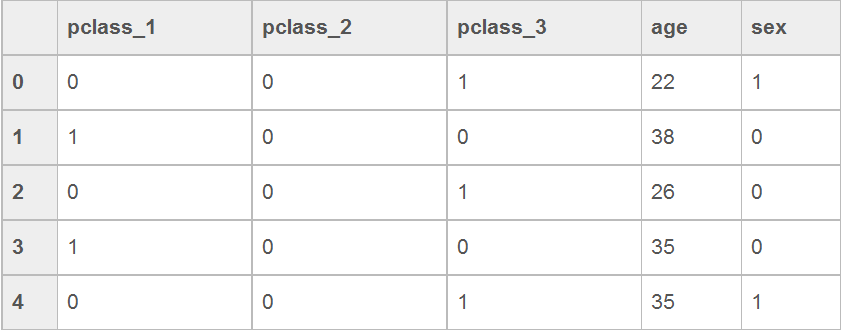
subdf = df[['Pclass','Sex','Age']]y = df.Survived# sklearn中的Imputer也可以age = subdf['Age'].fillna(value=subdf.Age.mean())# sklearn OneHotEncoder也可以pclass = pd.get_dummies(subdf['Pclass'],prefix='Pclass')sex = (subdf['Sex']=='male').astype('int')X = pd.concat([pclass,age,sex],axis=1)X.head()输出下图结果
建立模型
- 将数据切分为 train 和 test
from sklearn.cross_validation import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=33)- 在测试集(test)上观察决策树表现
from sklearn import treeclf = tree.DecisionTreeClassifier(criterion='entropy', max_depth=3,min_samples_leaf=5)clf = clf.fit(X_train,y_train)print("准确率为:{:.2f}".format(clf.score(X_test,y_test)))输出结果如下
准确率为:0.83- 观察各变量的重要性
clf.feature_importances_输出如下
array([ 0.08398076, 0. , 0.23320717, 0.10534824, 0.57746383])- 生成特征图
import matplotlib.pyplot as pltfeature_importance = clf.feature_importances_important_features = X_train.columns.values[0::]feature_importance = 100.0 * (feature_importance / feature_importance.max())sorted_idx = np.argsort(feature_importance)[::-1]pos = np.arange(sorted_idx.shape[0]) + .5plt.title('Feature Importance')plt.barh(pos, feature_importance[sorted_idx[::-1]], color='r',align='center')plt.yticks(pos, important_features)plt.xlabel('Relative Importance')plt.draw()plt.show()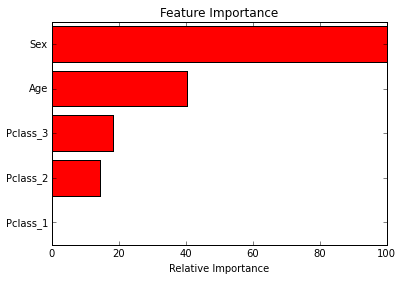
对于随机森林如何得到变量的重要性,可以看scikit-learn官方文档
当然在得到重要的特征后,我们就可以把不重要的特征去掉了,以提高模型的训练速度
最后是
- 使用交叉验证来评估模型
from sklearn import cross_validationscores1 = cross_validation.cross_val_score(clf, X, y, cv=10)scores1输出结果如下:
array([ 0.82222222, 0.82222222, 0.7752809 , 0.87640449, 0.82022472, 0.76404494, 0.7752809 , 0.76404494, 0.83146067, 0.78409091])- 使用更多指标来评估模型
from sklearn import metricsdef measure_performance(X,y,clf, show_accuracy=True, show_classification_report=True, show_confusion_matrix=True): y_pred=clf.predict(X) if show_accuracy: print("Accuracy:{0:.3f}".format(metrics.accuracy_score(y,y_pred)),"\n") if show_classification_report: print("Classification report") print(metrics.classification_report(y,y_pred),"\n") if show_confusion_matrix: print("Confusion matrix") print(metrics.confusion_matrix(y,y_pred),"\n")measure_performance(X_test,y_test,clf, show_classification_report=True, show_confusion_matrix=True)输出结果如下,可以看到 precision(精确度)recall(召回率)等更多特征
Accuracy:0.834 Classification report precision recall f1-score support 0 0.85 0.88 0.86 134 1 0.81 0.76 0.79 89avg / total 0.83 0.83 0.83 223Confusion matrix[[118 16] [ 21 68]] 与随机森林进行比较
from sklearn.ensemble import RandomForestClassifierclf2 = RandomForestClassifier(n_estimators=1000,random_state=33)clf2 = clf2.fit(X_train,y_train)scores2 = cross_validation.cross_val_score(clf2,X, y, cv=10)clf2.feature_importances_scores2.mean(), scores1.mean()准确率输出(这里用的是10折交叉验证后的平均值)
(0.81262938372488946, 0.80352769265690616)可以看到随机森林的准确要比决策树高0.1左右
总结
经过上面介绍分析,我们走过了一个数据科学家在拿到数据到得出结论的所有步骤
- 读入数据
- 数据清理
- 特征工程
- 构建模型
- 模型评估
- 参数调整
- 模型比较
这篇文章重要的不是结果,而是帮助你了解处理数据大致过程、步骤
剩下的细节,就是你发挥自己的想象力,进行改进、创新了
参考链接
python的决策树和随机森林
版权声明:本文为博主原创文章,未经博主允许不得转载。