k-������㷨�ǻ���ʵ����ѧϰ������������ģ��Ƚ��ܻ���ʵ��ѧϰ����ظ��
����ʵ����ѧϰ
- ��֪һϵ�е�ѵ���������ܶ�ѧϰ����ΪĿ�꺯����������ȷ��һ�㻯����������˲�ͬ������ʵ����ѧϰ����ֻ�Ǽذ�ѵ�������洢������
����Щʵ���з����Ĺ������Ƴٵ���������µ�ʵ��ʱ��ÿ��ѧϰ������һ���µIJ�ѯʵ���������������ʵ������ǰ�洢��ʵ���Ĺ�ϵ�����ݴ˰�һ��Ŀ�꺯��ֵ������ʵ���� - ����ʵ���ķ�������Ϊ��ͬ�Ĵ������ѯʵ��������ͬ��Ŀ�꺯���ƽ�����ʵ�ϣ��ܶ༼��ֻ����Ŀ�꺯���ľֲ��ƽ�������Ӧ�������²�ѯʵ���ڽ���ʵ�������� ������������ʵ���ռ��϶��������õıƽ�����Ŀ�꺯���ܸ��ӣ��������ò�̫���ӵľֲ��ƽ�����ʱ�������������������ơ�
- ����ʵ�������IJ���
- ������ʵ���Ŀ������ܴܺ�������Ϊ�������еļ��㶼�����ڷ���ʱ���������ڵ�һ������ѵ������ʱ�����ԣ������Ч������ѵ���������Լ��ٲ�ѯʱ���������һ����Ҫ��ʵ�����⡣
- ���Ӵ洢���м������Ƶ�ѵ������ʱ������һ�㿼��ʵ�����������ԡ����Ŀ�����������ںܶ������еļ���ʱ����ô��������ơ���ʵ��֮��ܿ��������Զ��
k-����ڷ�
�㷨����
K�����(K-Nearest Neighbor,KNN)�㷨����������ģʽʶ��ͳ��ѧ�������ڻ���ѧϰ�����㷨��ռ���൱��ĵ�λ������һ�������ϱȽϳ���ķ�����������Ļ���ѧϰ�㷨֮һ��Ҳ�ǻ���ʵ����ѧϰ������������ģ�������õ��ı������㷨֮һ��
����˼��
���һ��ʵ���������ռ��е�K�������ƣ��������ռ�������ڣ���ʵ���еĴ��������ijһ��������ʵ��Ҳ������������ѡ����ھӶ����Ѿ���ȷ�����ʵ����
���㷨�ٶ����е�ʵ����Ӧ��Nάŷʽ�ռ�
���㷨�漰3����Ҫ���أ�ʵ��������������Ƶĺ�����k�Ĵ�С��
һ��ʵ����������Ǹ��ݱ�ŷ�Ͼ��붨��ġ�����ȷ�ؽ����������ʵ��
<a1(x)��a2(x)��...��an(x)>
����
�й�KNN�㷨�ļ���˵����
- �������ѧϰ�У�Ŀ�꺯��ֵ����Ϊ��ɢֵҲ����Ϊʵֵ��
- �����ȿ���ѧϰ������ʽ����ɢĿ�꺯��������V��������{
v1,...,vs }���±������˱ƽ���ɢĿ�꺯����k-�����㷨�� - �����±�����ָ���ģ�����㷨�ķ���ֵ
f��(xq) Ϊ��f(xq) �Ĺ��ƣ������Ǿ���xq �����k��ѵ�����������ձ��fֵ�� - �������ѡ��k=1����ô��1-�����㷨���Ͱ�
f(xi) ����(xq) ������xi �����xq ��ѵ��ʵ�������ڽϴ��kֵ������㷨����ǰk�������ѵ��ʵ�������ձ��f ֵ��
�ƽ���ɢֵ����
f:?n?V ��k-�����㷨
ѵ���㷨��
����ÿ��ѵ������<x,f(x)> ����������������б�training_examples
�����㷨��
����һ��Ҫ����IJ�ѯʵ��xq
��training_examples��ѡ�����xq ��k��ʵ��������x1,....,xk ��ʾ
����
�������a=b ��ôd(a,b)=1 ������d(a,b)=0

����˵��KNN���Կ��ɣ�����ôһ�����Ѿ�֪����������ݣ�Ȼ��һ�������ݽ����ʱ�Ϳ�ʼ��ѵ���������ÿ��������룬Ȼ���������ѵ�����������K���㿴���⼸��������ʲô���ͣ�Ȼ�����������Ӷ�����ԭ�������ݹ��ࡣ
KNN�㷨�ľ��߹���
��ͼ�����������͵��������ݣ�һ������ɫ�������Σ���һ���Ǻ�ɫ�������Σ��м��Ǹ���ɫ��Բ���Ǵ��������ݣ�
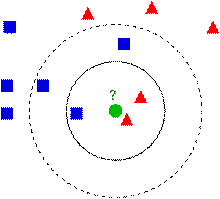
���K=3����ô����ɫ���������2����ɫ�������κ�1����ɫ�������Σ������������ͶƱ��������ɫ�Ĵ����������ں�ɫ�������Ρ������K=5����ô����ɫ���������2����ɫ�������κ�3����ɫ�������Σ�����������ͶƱ��������ɫ�Ĵ�������������ɫ�������Ρ�
��ͼ��ͼ����һ�ּ�����µ�k-������㷨��������ʵ���Ƕ�ά�ռ��еĵ㣬Ŀ�꺯�����в���ֵ������ѵ�������á�+���͡�-���ֱ��ʾ��ͼ��Ҳ������һ����ѯ��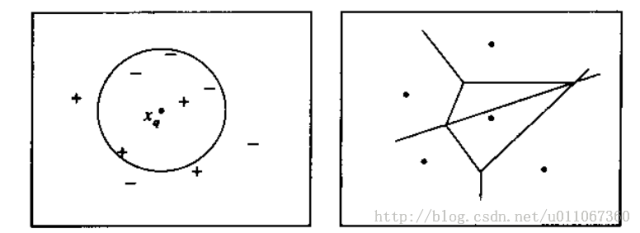
ͼ��˵������ͼ������һϵ�е�����ѵ��������һ��Ҫ����IJ�ѯʵ��
��ͼ�Ƕ���һ�����͵�ѵ����������1-�����㷨���µľ����档Χ��ÿ��ѵ������������α�ʾ���������ʵ���ռ䣨������ռ��е�ʵ���ᱻ1-�����㷨�����ѵ�����������ķ��ࣩ��
��ǰ���k-�����㷨�����ĺ����Ϳɱ����ڱƽ�����ֵ��Ŀ�꺯����Ϊ��ʵ����һ�㣬�������㷨����k����ӽ�������ƽ��ֵ�������Ǽ������е����ձ��ֵ������ȷ�ؽ���Ϊ�˱ƽ�һ��ʵֵĿ�꺯��
��Դ�ͳKNN�㷨�ĸĽ�
- ����KNN�㷨���ο�FKNN�������ף�ʵ��Ӧ���н��lucene��
- ��Ȩŷ�Ͼ��빫ʽ���ڴ�ͳ��ŷ�Ͼ�����,��������Ȩ����ͬ,Ҳ�����϶������������ڷ���Ĺ�������ͬ��,��Ȼ���Dz�����ʵ������ġ�ͬ�ȵ�Ȩ��ʹ����������֮�����ƶȼ��㲻��ȷ, ����Ӱ����ྫ�ȡ���Ȩŷ�Ͼ��빫ʽ,����Ȩ��ͨ�������ȷ�����ã�����ҵ���������������ؼ��ּ�Ȩ�����Լ�Ȩ�ȣ�
�����Ȩ������㷨
��k-������㷨��һ���Զ����ĸĽ��Ƕ�k�����ڵĹ���Ȩ������������Բ�ѯ��xq�ľ��룬���ϴ��Ȩֵ�����Ͻ��Ľ��ڡ�
���磬���ϱ��ƽ���ɢĿ�꺯�����㷨�У����ǿ��Ը���ÿ��������xq�ľ���ƽ���ĵ�����Ȩ������ڵġ�ѡ��Ȩ����
������ͨ������ʽȡ���ϱ��㷨�еĹ�ʽ��ʵ�֣�
����
Ϊ�˴�����ѯ��
����Ҳ���������Ƶķ�ʽ��ʵֵĿ�꺯�����о����Ȩ��ֻҪ����ʽ�滻�ϱ��Ĺ�ʽ��
����
ע�������ʽ�еķ�ĸ��һ��������������ͬȨֵ�Ĺ���һ�������磬����֤��������е�ѵ������
ע������k-�����㷨�����б��嶼ֻ����k�������Է����ѯ�㡣���ʹ�ð������Ȩ����ô�������е�ѵ������Ӱ��
�ġ�KNN����ȱ��
��1���ŵ�
�ټ��������⣬����ʵ�֣�����������ƣ�����ѵ��;
�ھ��ȸߣ����쳣ֵ�����У������������ݶԽ����Ӱ�첻�Ǻܴ�;
���ʺ϶�ϡ���¼����з���;
���ر��ʺ��ڶ��������(multi-modal,������ж������ǩ)��KNNҪ��SVM����Ҫ��.
��2��ȱ��
�ٶԲ�����������ʱ�ļ������ռ俪������Ϊ��ÿһ����������ı���Ҫ��������ȫ����֪�����ľ��룬�����������K������ڵ㡣Ŀǰ���õĽ�����������ȶ���֪��������м���������ȥ���Է������ò��������;
�ڿɽ����Բ�����������������Ĺ���;
������ȱ���ǵ�������ƽ��ʱ����һ��������������ܴ�����������������Сʱ���п��ܵ��µ�����һ��������ʱ����������K���ھ��д������������ռ���������㷨ֻ���㡰����ġ��ھ�������ijһ������������ܴ���ô�����������������ӽ�Ŀ���������������������ܿ���Ŀ����������������������������Ӱ�����н�������Բ���Ȩֵ�ķ���������������С���ھ�Ȩֵ�����Ľ�;
������ѧϰ������
�塢��k-�����㷨��˵��
�������Ȩ��k-�����㷨��һ�ַdz���Ч�Ĺ�����������������ѵ�������е������кܺõ�³���ԣ����ҵ������㹻���ѵ������ʱ��Ҳ�dz���Ч��ע��ͨ��ȡk�����ڵļ�Ȩƽ����������������������������Ӱ�졣
����һ�����ڼ�ľ���ᱻ�����IJ����������֧�䡣
Ӧ��k-�����㷨��һ��ʵ�������ǣ�ʵ����ľ����Ǹ���ʵ�����������ԣ�Ҳ���ǰ���ʵ����ŷ�Ͽռ�����������ᣩ����ġ�������Щֻѡ��ȫ��ʵ�����Ե�һ���Ӽ��ķ�����ͬ�����������ѧϰϵͳ��
��������һ�����⣺ÿ��ʵ����20������������������Щ�����н���2�������ķ������йء�����������£�������������Ե�ֵһ�µ�ʵ�����������20ά��ʵ���ռ�������Զ�������������20�����Ե������Զ�������k-�����㷨�ķ��ࡣ���ڼ�ľ���ᱻ�����IJ����������֧�䡣�������ڴ��ںܶ������������µ����⣬��ʱ����Ϊά�����ѣ�curse of dimensionality��������ڷ�������������ر����С�
�������������������ʵ����ľ���ʱ��ÿ�����Լ�Ȩ��
���൱�ڰ���������ŷ�Ͽռ��е������ᣬ���̶�Ӧ�ڲ�̫������Ե������ᣬ������Ӧ�ڸ���ص����Ե������ᡣÿ��������Ӧ��չ����������ͨ��������֤�ķ����Զ�������
�������Ӧ��k-�����㷨������һ��ʵ����������ν�����Ч����������Ϊ����㷨�Ƴ����еĴ�����ֱ�����յ�һ���µIJ�ѯ�����Դ���ÿ���²�ѯ������Ҫ�����ļ��㡣
���������Ŀǰ�Ѿ������˺ܶ�������Դ洢��ѵ�����������������Ա�������һ���洢��������¸���Ч��ȷ������ڡ�һ������������kd-tree��Bentley 1975��Friedman et al. 1977��������ʵ���洢������Ҷ����ڣ��ڽ���ʵ���洢��ͬһ�����Ľ���ڡ�ͨ�������²�ѯxq��ѡ�����ԣ������ڲ����Ѳ�ѯxq���е���ص�Ҷ��㡣
Pythonʵ��KNN�㷨
����ʵ��һ����дʶ���㷨������ֻ��ʶ��0~9���֡�
���룺ÿ����д�����Ѿ����ȴ�����32*32�Ķ������ı����洢Ϊtxt�ļ���ÿ�����ִ�Լ��200��������ÿ������������һ��txt�ļ��С���д��ͼ�����Ĵ�С��32x32�Ķ�ֵͼ��ת����txt�ļ����������Ҳ��32x32�����֣�����ͼ��ʾ��Ŀ¼trainingDigits��ŵ��Ǵ�Լ2000��ѵ�����ݣ�testDigits��Ŵ�Լ900���������ݡ�
- ����img2vector���������ɽ�ÿ��������txt�ļ�ת��Ϊ��Ӧ��һ������
# convert image to vector def img2vector(filename): rows = 32 cols = 32 imgVector = zeros((1, rows * cols)) fileIn = open(filename) for row in xrange(rows): lineStr = fileIn.readline() for col in xrange(cols): imgVector[0, row * 32 + col] = int(lineStr[col]) return imgVector- ����loadDDataSet�������������ݿ�
# load dataSet def loadDataSet(): ## step 1: Getting training set print "---Getting training set..." dataSetDir = './' trainingFileList = os.listdir(dataSetDir + 'trainingDigits') # load the training set numSamples = len(trainingFileList) train_x = zeros((numSamples, 1024)) train_y = [] for i in xrange(numSamples): filename = trainingFileList[i] # get train_x train_x[i, :] = img2vector(dataSetDir + 'trainingDigits/%s' % filename) # get label from file name such as "1_18.txt" label = int(filename.split('_')[0]) # return 1 train_y.append(label) ## step 2: Getting testing set print "---Getting testing set..." testingFileList = os.listdir(dataSetDir + 'testDigits') # load the testing set numSamples = len(testingFileList) test_x = zeros((numSamples, 1024)) test_y = [] for i in xrange(numSamples): filename = testingFileList[i] # get train_x test_x[i, :] = img2vector(dataSetDir + 'testDigits/%s' % filename) # get label from file name such as "1_18.txt" label = int(filename.split('_')[0]) # return 1 test_y.append(label) return train_x, train_y, test_x, test_y - ����kNNClassify:ʵ��kNN�����㷨
# classify using kNN def kNNClassify(newInput, dataSet, labels, k): numSamples = dataSet.shape[0] # shape[0] stands for the num of row ## step 1: calculate Euclidean distance # tile(A, reps): Construct an array by repeating A reps times # the following copy numSamples rows for dataSet diff = tile(newInput, (numSamples, 1)) - dataSet # Subtract element-wise squaredDiff = diff ** 2 # squared for the subtract squaredDist = sum(squaredDiff, axis = 1) # sum is performed by row distance = squaredDist ** 0.5 ## step 2: sort the distance # argsort() returns the indices that would sort an array in a ascending order sortedDistIndices = argsort(distance) classCount = {} # define a dictionary (can be append element) for i in xrange(k): ## step 3: choose the min k distance voteLabel = labels[sortedDistIndices[i]] ## step 4: count the times labels occur # when the key voteLabel is not in dictionary classCount, get() # will return 0 classCount[voteLabel] = classCount.get(voteLabel, 0) + 1 ## step 5: the max voted class will return maxCount = 0 for key, value in classCount.items(): if value > maxCount: maxCount = value maxIndex = key return maxIndex - ����testHandWritingClass:���Ժ���
# test hand writing class def testHandWritingClass(): ## step 1: load data print "step 1: load data..." train_x, train_y, test_x, test_y = loadDataSet() ## step 2: training... print "step 2: training..." pass ## step 3: testing print "step 3: testing..." numTestSamples = test_x.shape[0] matchCount = 0 for i in xrange(numTestSamples): predict = kNNClassify(test_x[i], train_x, train_y, 3) if predict == test_y[i]: matchCount += 1 accuracy = float(matchCount) / numTestSamples ## step 4: show the result print "step 4: show the result..." print 'The classify accuracy is: %.2f%%' % (accuracy * 100) �����Զ���
������һ���ÿռ���������ľ���������������Խ��ʾ����Խ�����ơ�
��Ϊ�����Զ����ľ��뺯��һ��������������:
- d(X,Y)=d(Y,X);
- d(X,Y)�Qd(X,Z)+d(Z,Y);
- d(X,Y)�R0;
- d(X,Y)=0,���ҽ���X=Y;
���X,Y��Z�Ƕ�Ӧ�����ռ��е������㡣
����X,Y�ֱ���Nά�����ռ��е�һ���㣬����X=
�����ѡ���кܶ��֣����õľ��뺯�����£�
1. ����˹��(Minkowsky)����
������(Manhattan)����
d(X,Y)=��i=1n�Oxi?yi�O����������Minkowsky��������=1ʱ��һ������ Cityblock����
d(X,Y)=��i=1nwi�Oxi?yi�O����������Manhattan��������Ȩ����������wi,i=1,2,...,n��Ȩ������ ŷ�����(Euclidean)���루ŷʽ���룩
d(X,Y)=[��i=1n�Oxi?yi�O2]12=(X?Y)(X?Y)T??????????????������Minkowsky��������=2ʱ������ Canberra����
d(X,Y)=��i=1nxi?yixi+yi
(6)Mahalanobis����(��ʽ����)
d(X,M)�����������ռ��еĵ�X��M֮���һ�־����ȣ�����MΪijһ��ģʽ���ľ�ֵ��������Ϊ��Ӧģʽ����Э�������
�þ����ȿ�������MΪ������ģʽ����������ռ��е�����ֲ�,�ܹ������������Ե�������ϴ����ľ���ʧ�档������M����ʽ����Ϊ�����ĵ���������ռ��е�һ���������档
�б�ѩ��(Chebyshev)����
d(X,Y)=maxi(�Oxi?yi�O) L��=limk����(��i=1k�Oxi?yi�Ok)1k
�б�ѩ��������L�� �����������ռ��е�һ�ֶ�����������֮��ľ��붨��Ϊ���������ֵ������ֵ���ڶ�ά�ռ��С���(x1,y1) ��(x2,y2) ����Ϊ�������б�ѩ�����Ϊd=max(�Ox2?x1�O,�Oy2?y1�O) �б�ѩ��������L�����������ռ��е�һ�ֶ�����������֮��ľ��붨��Ϊ���������ֵ������ֵ���ڶ�ά�ռ��С���(x1,y1)��(x2,y2)����Ϊ�������б�ѩ�����Ϊ
d=max(|x2?x1|,|y2?y1|) ƽ������
daverage=[1n��i=1n(xi?yi)2]12
����ѧϰ�����ѧϰ
- ����ѧϰ(Eager Learning)
����ѧϰ��ʽ��ָ�ڽ���ij���жϣ����磬ȷ��һ����ķ�����ع���ȷ��ij�����Ӧ�ĺ���ֵ��֮ǰ��������ѵ�����ݽ���ѵ���õ�һ��Ŀ�꺯��������Ҫʱ��ֻ����ѵ���õĺ������о��ߣ���Ȼ����һ��һ�����ݵķ�����SVM����������ѧϰ��ʽ�� - ����ѧϰ(Lazy Learning)
����ѧϰ��ʽָ���Ǹ�����������һ�㻯��Ŀ�꺯����ȷ������������Ǽذ�ѵ�������洢������ֱ����Ҫ�����µ�ʵ��ʱ�ŷ����������洢�����Ĺ�ϵ���ݴ�ȷ����ʵ����Ŀ�꺯��ֵ��Ҳ����˵����ѧϰ��ʽֻ�е�����Ҫ����ʱ�Ż������������ݽ��о��ߣ�������֮ǰ���ᾭ�� Eager Learning��ӵ�е�ѵ�����̡�KNN����������ѧϰ��ʽ�� �Ƚ�
- Eager Learning���ǵ�������ѵ��������˵������һ��ȫ�ֵĽ��ƣ���Ȼ����Ҫ�ķ�ѵ��ʱ�䣬�����ľ���ʱ�����Ϊ0.
- Lazy Learning�ھ���ʱ��Ȼ��Ҫ���������������ѯ��ľ��룬����������������ʱȴֻ���˾ֲ��ļ���ѵ�����ݣ���������һ���ֲ��Ľ��ƣ�Ȼ����Ȼ����Ҫѵ�������ĸ��ӶȻ�����Ҫ O(n),n ��ѵ�������ĸ���������ÿ�ξ��߶���Ҫ��ÿһ��ѵ����������룬��������Lazy Learning��ȱ�㣺(1)��Ҫ�Ĵ洢�ռ�Ƚϴ� (2)���߹��̱Ƚ�����
�����㷨
- ����ѧϰ����:SVM;Find-S�㷨;��ѡ�����㷨;������;�˹�������;��Ҷ˹����;
- ����ѧϰ����:KNN;�ֲ���Ȩ�ع�;���ڰ���������;
��������
[1] Trevor Hastie & Rolbert Tibshirani. Discriminant Adaptive Nearest Neighbor Classification. IEEE TRANSACTIONS ON PAITERN ANALYSIS AND MACHINE INTELLIGENCE,1996.
[2] R. Short & K. Fukanaga. A New Nearest Neighbor Distance Measure,Pro. Fifth IEEE Int��l Conf.Pattern Recognition,pp.81-86,1980.
[3] T.M Cover. Nearest Neighbor Pattern Classification,Pro. IEEE Trans,Infomation Theory,1967.
[4] C.J.Stone. Consistent Nonparametric Regression ,Ann.Stat.,vol.3,No.4,pp.595-645,1977.
[5] W Cleveland. Robust Locally-Weighted Regression and Smoothing Scatterplots,J.Am.Statistical.,vol.74,pp.829-836,1979.
[6] T.A.Brown & J.Koplowitz. The Weighted Nearest Neighbor Rule for Class Dependent Sample Sizes,IEEE Tran. Inform.Theory,vol.IT-25,pp.617-619,Sept.1979.
[7] J.P.Myles & D.J.Hand. The Multi-Class Metric Problem in Nearest Neighbor Discrimination Rules,Pattern Recognition,1990.
[8] N.S.Altman. An Introduction to Kernel and Nearest Neighbor Nonparametric Regression,1992.
[9]Min-Ling Zhang & Zhi-Hua Zhou. M1-KNN:A Lazy Learning Approach to Multi-Label Learning,2007.
[10]Peter Hall,Byeong U.Park & Richard J. Samworth. Choice of Neighbor Order In Nearest Neighbor Classification,2008.
[11] Jia Pan & Dinesh Manocha. Bi-Level Locality Sensitive Hashing for K-Nearest Neighbor Computation,2012.
��Ȩ����������Ϊ����ԭ�����£�δ��������������ת�ء�