我们很多人都知道Encoding.Unicode这个东东,它是用于获取字符串的Unicode字节流包括把Unicode字节流转换成.NET上的一个通用字符串String,但是有很多人却不知道它内部是如何实现的,当年我是通过MultiByteToWideChar
与WideCharToMultiByte实现的,但是我并不知道内部的实现方式。
首先我们需要理解Unicode字符串在内存中是怎么存储的,Unicode规定一个字符占用两个字节与wchar_t的长度一致
我为什要提这个是因为若你不知道有有多长你很难编写代码下去 除非你Ctrl + C && Ctrl + V
在内存中一个字符串假设为 “中” 它的对应short int value为20013那么在内存中它会是这样存储
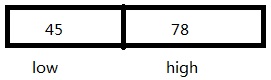
X
low: 0010 1101
high: 0100 1110
√
low: 1011 0100
high: 0111 0010
左边为低位,右边为高位。高位是低位的一次幂,一个byte拥有8/bit二进制
形式:1111 1111 如果计算为十进制介质范围在0~255及256次
那么我们可以通过上述内容 可以得到 公式: (low * 256 ^ 0) + (high * 256 ^ 1)

示例代码:
private void Form1_Load(object sender, EventArgs e) { byte[] bfx = GetUniocdeBytes("中国"); byte[] bfy = Encoding.Unicode.GetBytes("中国"); string str = GetUnicodeString(bfx); } private byte[] GetUniocdeBytes(string str) { int size = 0; if(str != null && (size = str.Length) > 0) { byte[] buffer = new byte[size * 2]; for (int i = 0; i < size; i++) { char chr = str[i]; buffer[i * 2] = (byte)(chr & 0xff); buffer[i * 2 + 1] = (byte)(chr >> 8); } return buffer; } return new byte[size]; } private string GetUnicodeString(byte[] buffer) { int size = 0; if (buffer != null && (size = buffer.Length) >= 2) { size -= size % 2; // sizeof(wchar_t) char[] value = new char[size / 2]; for (int i = 0; i < size; i += 2) value[i / 2] = (char)((buffer[i + 1] << 8) + buffer[i]); return new string(value); } return string.Empty; }