一、前言
今天又是周六了,闲来无事,只能写文章了呀,今天我们继续来看逆向的相关知识,我们今天来介绍一下Android中的AndroidManifest文件格式的内容,有的同学可能好奇了,AndroidManifest文件格式有啥好说的呢?不会是介绍那些标签和属性是怎么用的吧?那肯定不会,介绍那些知识有点无聊了,而且和我们的逆向也没关系,我们今天要介绍的是Android中编译之后的AndroidManifest文件的格式,首先来脑补一个知识点,Android中的Apk程序其实就是一个压缩包,我们可以用压缩软件进行解压的:

二、技术介绍
我们可以看到这里有三个文件我们后续都会做详细的解读的:AndroidManifest.xml,classes.dex,resources.arsc
其实说到这里只要反编译过apk的同学都知道一个工具apktool,那么其实他的工作原理就是解析这三个文件格式,因为本身Android在编译成apk之后,这个文件有自己的格式,用普通文本格式打开的话是乱码的,看不懂的,所以需要解析他们成我们能看懂的东东,所以从这篇文章开始,陆续介绍这三个文件的格式解析,这样我们在后面反编译apk的时候,遇到错误能够精确的定位到问题。
今天我们先来看一下AndroidManifest.xml格式:

如果我们这里显示全是16进制的内容,所以我们需要解析,就像我之前解析so文件一样:
http://blog.csdn.net/jiangwei0910410003/article/details/49336613
任何一个文件都一定有他自己的格式,既然编译成apk之后,变成这样了,那么google就是给AndroidManifest定义了一种文件格式,我们只需要知道这种格式的话,就可以详细的解析出来文件了:

看到此图是不是又很激动呢?这又是一张神图,详细的解析了AndroidManifest.xml文件的格式,但是光看这张图我们可以看不出来啥,所以要结合一个案例来解析一个文件,这样才能理解透彻,但是这样图是根基,下面我们就用一个案例来解析一下吧:
案例到处都是,谁便搞一个简单的apk,用压缩文件打开,解压出AndroidManifest.xml就可以了,然后就开始读取内容进行解析:
三、格式解析
第一、头部信息
任何一个文件格式,都会有头部信息的,而且头部信息也很重要,同时,头部一般都是固定格式的。

这里的头部信息还有这些字段信息:
1、文件魔数:四个字节
2、文件大小:四个字节
下面就开始解析所有的Chunk内容了,其实每个Chunk的内容都有一个相似点,就是头部信息:
ChunkType(四个字节)和ChunkSize(四个字节)
第二、String Chunk内容
这个Chunk主要存放的是AndroidManifest文件中所有的字符串信息
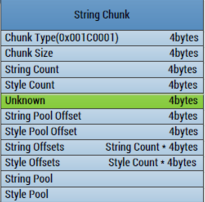
1、ChunkType:StringChunk的类型,固定四个字节:0x001C0001
2、ChunkSize:StringChunk的大小,四个字节
3、StringCount:StringChunk中字符串的个数,四个字节
4、StyleCount:StringChunk中样式的个数,四个字节,但是在实际解析过程中,这个值一直是0x00000000
5、Unknown:位置区域,四个字节,在解析的过程中,这里需要略过四个字节
6、StringPoolOffset:字符串池的偏移值,四个字节,这个偏移值是相对于StringChunk的头部位置
7、StylePoolOffset:样式池的偏移值,四个字节,这里没有Style,所以这个字段可忽略
8、StringOffsets:每个字符串的偏移值,所以他的大小应该是:StringCount*4个字节
9、SytleOffsets:每个样式的偏移值,所以他的大小应该是SytleCount*4个字节
后面就开始是字符串内容和样式内容了。

下面我们就开始来看代码了,由于代码的篇幅有点长,所以这里就分段说明,代码的整个工程,后面我会给出下载地址的,
1、首先我们需要把AndroidManifest.xml文件读入到一个byte数组中:
byte[] byteSrc = null;FileInputStream fis = null;ByteArrayOutputStream bos = null;try{ fis = new FileInputStream("xmltest/AndroidManifest1.xml"); bos = new ByteArrayOutputStream(); byte[] buffer = new byte[1024]; int len = 0; while((len=fis.read(buffer)) != -1){ bos.write(buffer, 0, len); } byteSrc = bos.toByteArray();}catch(Exception e){ System.out.println("parse xml error:"+e.toString());}finally{ try{ fis.close(); bos.close(); }catch(Exception e){ }}2、下面我们就来看看解析头部信息:
/** * 解析xml的头部信息 * @param byteSrc */public static void parseXmlHeader(byte[] byteSrc){ byte[] xmlMagic = Utils.copyByte(byteSrc, 0, 4); System.out.println("magic number:"+Utils.bytesToHexString(xmlMagic)); byte[] xmlSize = Utils.copyByte(byteSrc, 4, 4); System.out.println("xml size:"+Utils.bytesToHexString(xmlSize)); xmlSb.append("<?xml version=\"1.0\" encoding=\"utf-8\"?>"); xmlSb.append("\n");}这里没什么说的,按照上面我们说的那个格式解析即可
3、解析StringChunk信息
/** * 解析StringChunk * @param byteSrc */public static void parseStringChunk(byte[] byteSrc){ //String Chunk的标示 byte[] chunkTagByte = Utils.copyByte(byteSrc, stringChunkOffset, 4); System.out.println("string chunktag:"+Utils.bytesToHexString(chunkTagByte)); //String Size byte[] chunkSizeByte = Utils.copyByte(byteSrc, 12, 4); //System.out.println(Utils.bytesToHexString(chunkSizeByte)); int chunkSize = Utils.byte2int(chunkSizeByte); System.out.println("chunk size:"+chunkSize); //String Count byte[] chunkStringCountByte = Utils.copyByte(byteSrc, 16, 4); int chunkStringCount = Utils.byte2int(chunkStringCountByte); System.out.println("count:"+chunkStringCount); stringContentList = new ArrayList<String>(chunkStringCount); //这里需要注意的是,后面的四个字节是Style的内容,然后紧接着的四个字节始终是0,所以我们需要直接过滤这8个字节 //String Offset 相对于String Chunk的起始位置0x00000008 byte[] chunkStringOffsetByte = Utils.copyByte(byteSrc, 28, 4); int stringContentStart = 8 + Utils.byte2int(chunkStringOffsetByte); System.out.println("start:"+stringContentStart); //String Content byte[] chunkStringContentByte = Utils.copyByte(byteSrc, stringContentStart, chunkSize); /** * 在解析字符串的时候有个问题,就是编码:UTF-8和UTF-16,如果是UTF-8的话是以00结尾的,如果是UTF-16的话以00 00结尾的 */ /** * 此处代码是用来解析AndroidManifest.xml文件的 */ //这里的格式是:偏移值开始的两个字节是字符串的长度,接着是字符串的内容,后面跟着两个字符串的结束符00 byte[] firstStringSizeByte = Utils.copyByte(chunkStringContentByte, 0, 2); //一个字符对应两个字节 int firstStringSize = Utils.byte2Short(firstStringSizeByte)*2; System.out.println("size:"+firstStringSize); byte[] firstStringContentByte = Utils.copyByte(chunkStringContentByte, 2, firstStringSize+2); String firstStringContent = new String(firstStringContentByte); stringContentList.add(Utils.filterStringNull(firstStringContent)); System.out.println("first string:"+Utils.filterStringNull(firstStringContent)); //将字符串都放到ArrayList中 int endStringIndex = 2+firstStringSize+2; while(stringContentList.size() < chunkStringCount){ //一个字符对应两个字节,所以要乘以2 int stringSize = Utils.byte2Short(Utils.copyByte(chunkStringContentByte, endStringIndex, 2))*2; String str = new String(Utils.copyByte(chunkStringContentByte, endStringIndex+2, stringSize+2)); System.out.println("str:"+Utils.filterStringNull(str)); stringContentList.add(Utils.filterStringNull(str)); endStringIndex += (2+stringSize+2); } /** * 此处的代码是用来解析资源文件xml的 */ /*int stringStart = 0; int index = 0; while(index < chunkStringCount){ byte[] stringSizeByte = Utils.copyByte(chunkStringContentByte, stringStart, 2); int stringSize = (stringSizeByte[1] & 0x7F); System.out.println("string size:"+Utils.bytesToHexString(Utils.int2Byte(stringSize))); if(stringSize != 0){ //这里注意是UTF-8编码的 String val = ""; try{ val = new String(Utils.copyByte(chunkStringContentByte, stringStart+2, stringSize), "utf-8"); }catch(Exception e){ System.out.println("string encode error:"+e.toString()); } stringContentList.add(val); }else{ stringContentList.add(""); } stringStart += (stringSize+3); index++; } for(String str : stringContentList){ System.out.println("str:"+str); }*/ resourceChunkOffset = stringChunkOffset + Utils.byte2int(chunkSizeByte);}这里我们需要解释的几个点:1、在上面的格式说明中,我们需要注意,有一个Unknow字段,四个字节,所以我们需要略过
2、在解析字符串内容的时候,字符串内容的结束符是:0x0000
3、每个字符串开始的前两个字节是字符串的长度
所以我们有了每个字符串的偏移值和大小,那么解析字符串内容就简单了:

这里我们看到0x000B(高位和低位相反)就是字符串的大小,结尾是0x0000

一个字符对应的是两个字节,而且这里有一个方法:Utils.filterStringNull(firstStringContent):
public static String filterStringNull(String str){ if(str == null || str.length() == 0){ return str; } byte[] strByte = str.getBytes(); ArrayList<Byte> newByte = new ArrayList<Byte>(); for(int i=0;i<strByte.length;i++){ if(strByte[i] != 0){ newByte.add(strByte[i]); } } byte[] newByteAry = new byte[newByte.size()]; for(int i=0;i<newByteAry.length;i++){ newByteAry[i] = newByte.get(i); } return new String(newByteAry);}其实逻辑很简单,就是过滤空字符串:在C语言中是NULL,在Java中就是00,如果不过滤的话,会出现下面的这种情况:
每个字符是宽字符,很难看,其实愿意就是每个字符后面多了一个00,所以过滤之后就可以了

这样就好看多了。
上面我们就解析了AndroidManifest.xml中所有的字符串内容。这里我们需要用一个全局的字符列表,用来存储这些字符串的值,后面会用索引来获取这些字符串的值。
第三、解析ResourceIdChunk
这个Chunk主要是存放的是AndroidManifest中用到的系统属性值对应的资源Id,比如android:versionCode中的versionCode属性,android是前缀,后面会说道

1、ChunkType:ResourceIdChunk的类型,固定四个字节:0x00080108
2、ChunkSize:ResourceChunk的大小,四个字节
3、ResourceIds:ResourceId的内容,这里大小是ResourceChunk大小除以4,减去头部的大小8个字节(ChunkType和ChunkSize)

/** * 解析Resource Chunk * @param byteSrc */public static void parseResourceChunk(byte[] byteSrc){ byte[] chunkTagByte = Utils.copyByte(byteSrc, resourceChunkOffset, 4); System.out.println(Utils.bytesToHexString(chunkTagByte)); byte[] chunkSizeByte = Utils.copyByte(byteSrc, resourceChunkOffset+4, 4); int chunkSize = Utils.byte2int(chunkSizeByte); System.out.println("chunk size:"+chunkSize); //这里需要注意的是chunkSize是包含了chunkTag和chunkSize这两个字节的,所以需要剔除 byte[] resourceIdByte = Utils.copyByte(byteSrc, resourceChunkOffset+8, chunkSize-8); ArrayList<Integer> resourceIdList = new ArrayList<Integer>(resourceIdByte.length/4); for(int i=0;i<resourceIdByte.length;i+=4){ int resId = Utils.byte2int(Utils.copyByte(resourceIdByte, i, 4)); System.out.println("id:"+resId+",hex:"+Utils.bytesToHexString(Utils.copyByte(resourceIdByte, i, 4))); resourceIdList.add(resId); } nextChunkOffset = (resourceChunkOffset+chunkSize);}解析结果: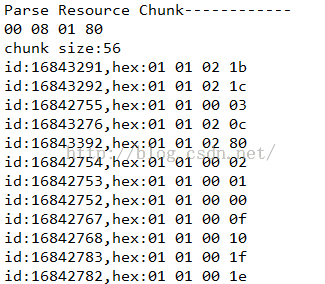
我们看到这里解析出来的id到底是什么呢?
这里需要脑补一个知识点了:
我们在写Android程序的时候,都会发现有一个R文件,那里面就是存放着每个资源对应的Id,那么这些id值是怎么得到的呢?
Package ID相当于是一个命名空间,限定资源的来源。Android系统当前定义了两个资源命令空间,其中一个系统资源命令空间,它的Package ID等于0x01,另外一个是应用程序资源命令空间,它的Package ID等于0x7f。所有位于[0x01, 0x7f]之间的Package ID都是合法的,而在这个范围之外的都是非法的Package ID。前面提到的系统资源包package-export.apk的Package ID就等于0x01,而我们在应用程序中定义的资源的Package ID的值都等于0x7f,这一点可以通过生成的R.java文件来验证。
Type ID是指资源的类型ID。资源的类型有animator、anim、color、drawable、layout、menu、raw、string和xml等等若干种,每一种都会被赋予一个ID。
Entry ID是指每一个资源在其所属的资源类型中所出现的次序。注意,不同类型的资源的Entry ID有可能是相同的,但是由于它们的类型不同,我们仍然可以通过其资源ID来区别开来。
关于资源ID的更多描述,以及资源的引用关系,可以参考frameworks/base/libs/utils目录下的README文件
我们可以得知系统资源对应id的xml文件是在哪里:frameworks\base\core\res\res\values\public.xml
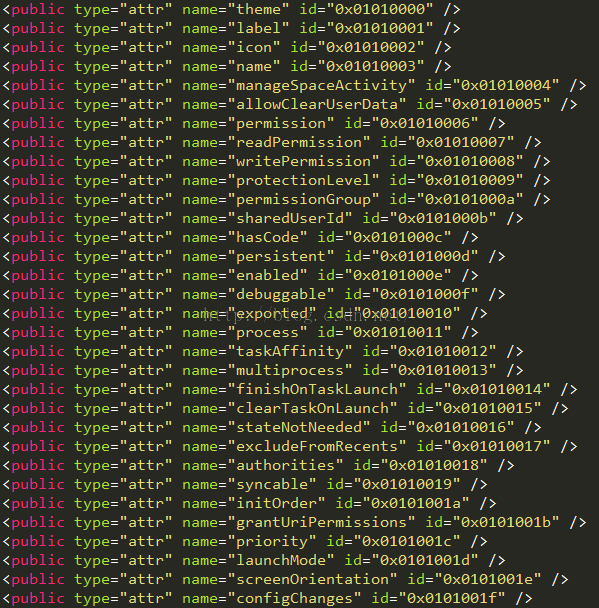
那么我们用上面解析到的id,去public.xml文件中查询一下:
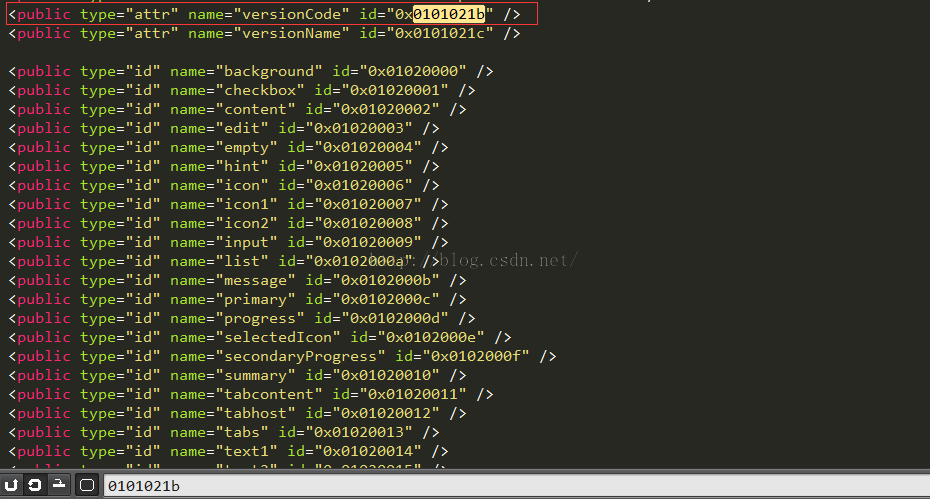
查到了,是versionCode,对于这个系统资源id存放文件public.xml还是很重要的,后面在讲解resource.arsc文件格式的时候还会继续用到。
第四、解析StartNamespaceChunk
这个Chunk主要包含一个AndroidManifest文件中的命令空间的内容,Android中的xml都是采用Schema格式的,所以肯定有Prefix和Uri的。
这里在脑补一个知识点:xml格式有两种:DTD和Schema,不了解的同学可以阅读这篇文章
http://blog.csdn.net/jiangwei0910410003/article/details/19340975
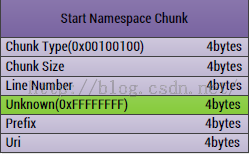
1、ChunkType:Chunk的类型,固定四个字节:0x00100100
2、ChunkSize:Chunk的大小,四个字节
3、LineNumber:在AndroidManifest文件中的行号,四个字节
4、Unknown:未知区域,四个字节
5、Prefix:命名空间的前缀(在字符串中的索引值),比如:android
6、Uri:命名空间的uri(在字符串中的索引值):比如:http://schemas.android.com/apk/res/android

解析代码:
/** * 解析StartNamespace Chunk * @param byteSrc */public static void parseStartNamespaceChunk(byte[] byteSrc){ //获取ChunkTag byte[] chunkTagByte = Utils.copyByte(byteSrc, 0, 4); System.out.println(Utils.bytesToHexString(chunkTagByte)); //获取ChunkSize byte[] chunkSizeByte = Utils.copyByte(byteSrc, 4, 4); int chunkSize = Utils.byte2int(chunkSizeByte); System.out.println("chunk size:"+chunkSize); //解析行号 byte[] lineNumberByte = Utils.copyByte(byteSrc, 8, 4); int lineNumber = Utils.byte2int(lineNumberByte); System.out.println("line number:"+lineNumber); //解析prefix(这里需要注意的是行号后面的四个字节为FFFF,过滤) byte[] prefixByte = Utils.copyByte(byteSrc, 16, 4); int prefixIndex = Utils.byte2int(prefixByte); String prefix = stringContentList.get(prefixIndex); System.out.println("prefix:"+prefixIndex); System.out.println("prefix str:"+prefix); //解析Uri byte[] uriByte = Utils.copyByte(byteSrc, 20, 4); int uriIndex = Utils.byte2int(uriByte); String uri = stringContentList.get(uriIndex); System.out.println("uri:"+uriIndex); System.out.println("uri str:"+uri); uriPrefixMap.put(uri, prefix); prefixUriMap.put(prefix, uri);}解析的结果如下:
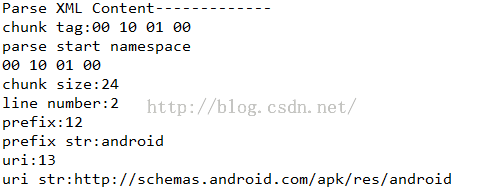
这里的内容就是上面我们解析完String之后的对应的字符串索引值,这里我们需要注意的是,一个xml中可能会有多个命名空间,所以这里我们用Map存储Prefix和Uri对应的关系,后面在解析节点内容的时候会用到。
第五、StratTagChunk
这个Chunk主要是存放了AndroidManifest.xml中的标签信息了,也是最核心的内容,当然也是最复杂的内容
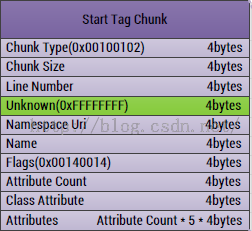
1、ChunkType:Chunk的类型,固定四个字节:0x00100102
2、ChunkSize:Chunk的大小,固定四个字节
3、LineNumber:对应于AndroidManifest中的行号,四个字节
4、Unknown:未知领域,四个字节
5、NamespaceUri:这个标签用到的命名空间的Uri,比如用到了android这个前缀,那么就需要用http://schemas.android.com/apk/res/android这个Uri去获取,四个字节
6、Name:标签名称(在字符串中的索引值),四个字节
7、Flags:标签的类型,四个字节,比如是开始标签还是结束标签等
8、AttributeCount:标签包含的属性个数,四个字节
9、ClassAtrribute:标签包含的类属性,四个字节
10,Atrributes:属性内容,每个属性算是一个Entry,这个Entry固定大小是大小为5的字节数组:
[Namespace,Uri,Name,ValueString,Data],我们在解析的时候需要注意第四个值,要做一次处理:需要右移24位。所以这个字段的大小是:属性个数*5*4个字节

解析代码:
/** * 解析StartTag Chunk * @param byteSrc */public static void parseStartTagChunk(byte[] byteSrc){ //解析ChunkTag byte[] chunkTagByte = Utils.copyByte(byteSrc, 0, 4); System.out.println(Utils.bytesToHexString(chunkTagByte)); //解析ChunkSize byte[] chunkSizeByte = Utils.copyByte(byteSrc, 4, 4); int chunkSize = Utils.byte2int(chunkSizeByte); System.out.println("chunk size:"+chunkSize); //解析行号 byte[] lineNumberByte = Utils.copyByte(byteSrc, 8, 4); int lineNumber = Utils.byte2int(lineNumberByte); System.out.println("line number:"+lineNumber); //解析prefix byte[] prefixByte = Utils.copyByte(byteSrc, 8, 4); int prefixIndex = Utils.byte2int(prefixByte); //这里可能会返回-1,如果返回-1的话,那就是说没有prefix if(prefixIndex != -1 && prefixIndex<stringContentList.size()){ System.out.println("prefix:"+prefixIndex); System.out.println("prefix str:"+stringContentList.get(prefixIndex)); }else{ System.out.println("prefix null"); } //解析Uri byte[] uriByte = Utils.copyByte(byteSrc, 16, 4); int uriIndex = Utils.byte2int(uriByte); if(uriIndex != -1 && prefixIndex<stringContentList.size()){ System.out.println("uri:"+uriIndex); System.out.println("uri str:"+stringContentList.get(uriIndex)); }else{ System.out.println("uri null"); } //解析TagName byte[] tagNameByte = Utils.copyByte(byteSrc, 20, 4); System.out.println(Utils.bytesToHexString(tagNameByte)); int tagNameIndex = Utils.byte2int(tagNameByte); String tagName = stringContentList.get(tagNameIndex); if(tagNameIndex != -1){ System.out.println("tag name index:"+tagNameIndex); System.out.println("tag name str:"+tagName); }else{ System.out.println("tag name null"); } //解析属性个数(这里需要过滤四个字节:14001400) byte[] attrCountByte = Utils.copyByte(byteSrc, 28, 4); int attrCount = Utils.byte2int(attrCountByte); System.out.println("attr count:"+attrCount); //解析属性 //这里需要注意的是每个属性单元都是由五个元素组成,每个元素占用四个字节:namespaceuri, name, valuestring, type, data //在获取到type值的时候需要右移24位 ArrayList<AttributeData> attrList = new ArrayList<AttributeData>(attrCount); for(int i=0;i<attrCount;i++){ Integer[] values = new Integer[5]; AttributeData attrData = new AttributeData(); for(int j=0;j<5;j++){ int value = Utils.byte2int(Utils.copyByte(byteSrc, 36+i*20+j*4, 4)); switch(j){ case 0: attrData.nameSpaceUri = value; break; case 1: attrData.name = value; break; case 2: attrData.valueString = value; break; case 3: value = (value >> 24); attrData.type = value; break; case 4: attrData.data = value; break; } values[j] = value; } attrList.add(attrData); } for(int i=0;i<attrCount;i++){ if(attrList.get(i).nameSpaceUri != -1){ System.out.println("nameSpaceUri:"+stringContentList.get(attrList.get(i).nameSpaceUri)); }else{ System.out.println("nameSpaceUri == null"); } if(attrList.get(i).name != -1){ System.out.println("name:"+stringContentList.get(attrList.get(i).name)); }else{ System.out.println("name == null"); } if(attrList.get(i).valueString != -1){ System.out.println("valueString:"+stringContentList.get(attrList.get(i).valueString)); }else{ System.out.println("valueString == null"); } System.out.println("type:"+AttributeType.getAttrType(attrList.get(i).type)); System.out.println("data:"+AttributeType.getAttributeData(attrList.get(i))); } //这里开始构造xml结构 xmlSb.append(createStartTagXml(tagName, attrList));}代码有点长,我们来分析一下:解析属性:
//解析属性//这里需要注意的是每个属性单元都是由五个元素组成,每个元素占用四个字节:namespaceuri, name, valuestring, type, data//在获取到type值的时候需要右移24位ArrayList<AttributeData> attrList = new ArrayList<AttributeData>(attrCount);for(int i=0;i<attrCount;i++){ Integer[] values = new Integer[5]; AttributeData attrData = new AttributeData(); for(int j=0;j<5;j++){ int value = Utils.byte2int(Utils.copyByte(byteSrc, 36+i*20+j*4, 4)); switch(j){ case 0: attrData.nameSpaceUri = value; break; case 1: attrData.name = value; break; case 2: attrData.valueString = value; break; case 3: value = (value >> 24); attrData.type = value; break; case 4: attrData.data = value; break; } values[j] = value; } attrList.add(attrData);}看到第四个值的时候,需要额外的处理一下,就是需要右移24位。解析完属性之后,那么就可以得到一个标签的名称和属性名称和属性值了:
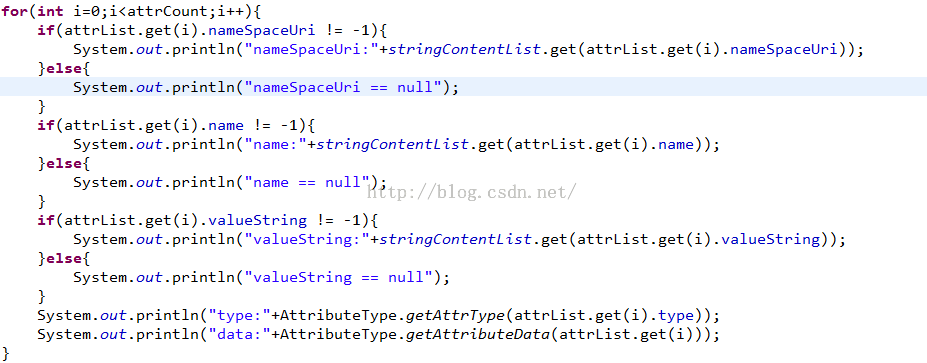
看解析的结果:

标签manifest包含的属性:

这里有几个问题需要解释一下:
1、为什么我们看到的是三个属性,但是解析打印的结果是5个?
因为系统在编译apk的时候,会添加两个属性:platformBuildVersionCode和platformBuildVersionName
这个是发布的到设备的版本号和版本名称

这个是解析之后的结果
2、当没有android这样的前缀的时候,NamespaceUri是null
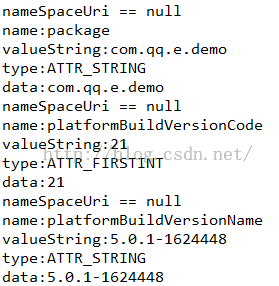
3、当dataType不同,对应的data值也是有不同的含义的:

这个方法就是用来转义的,后面在解析resource.arsc的时候也会用到这个方法。
4、每个属性理论上都会含有一个NamespaceUri的,这个也决定了属性的前缀Prefix,默认都是android,但是有时候我们会自定义一个控件的时候,这时候就需要导入NamespaceUri和Prefix了。所以一个xml中可能会有多个Namespace,每个属性都会包含NamespaceUri的。
其实到这里我们就算解析完了大部分的工作了,至于还有EndTagChunk,那个和StartTagChunk非常类似,这里就不在详解了:
/** * 解析EndTag Chunk * @param byteSrc */public static void parseEndTagChunk(byte[] byteSrc){ byte[] chunkTagByte = Utils.copyByte(byteSrc, 0, 4); System.out.println(Utils.bytesToHexString(chunkTagByte)); byte[] chunkSizeByte = Utils.copyByte(byteSrc, 4, 4); int chunkSize = Utils.byte2int(chunkSizeByte); System.out.println("chunk size:"+chunkSize); //解析行号 byte[] lineNumberByte = Utils.copyByte(byteSrc, 8, 4); int lineNumber = Utils.byte2int(lineNumberByte); System.out.println("line number:"+lineNumber); //解析prefix byte[] prefixByte = Utils.copyByte(byteSrc, 8, 4); int prefixIndex = Utils.byte2int(prefixByte); //这里可能会返回-1,如果返回-1的话,那就是说没有prefix if(prefixIndex != -1 && prefixIndex<stringContentList.size()){ System.out.println("prefix:"+prefixIndex); System.out.println("prefix str:"+stringContentList.get(prefixIndex)); }else{ System.out.println("prefix null"); } //解析Uri byte[] uriByte = Utils.copyByte(byteSrc, 16, 4); int uriIndex = Utils.byte2int(uriByte); if(uriIndex != -1 && prefixIndex<stringContentList.size()){ System.out.println("uri:"+uriIndex); System.out.println("uri str:"+stringContentList.get(uriIndex)); }else{ System.out.println("uri null"); } //解析TagName byte[] tagNameByte = Utils.copyByte(byteSrc, 20, 4); System.out.println(Utils.bytesToHexString(tagNameByte)); int tagNameIndex = Utils.byte2int(tagNameByte); String tagName = stringContentList.get(tagNameIndex); if(tagNameIndex != -1){ System.out.println("tag name index:"+tagNameIndex); System.out.println("tag name str:"+tagName); }else{ System.out.println("tag name null"); } xmlSb.append(createEndTagXml(tagName));}但是我们在解析的时候,我们需要做一个循环操作:

因为我们知道,Android中在解析Xml的时候提供了很多种方式,但是这里我们没有用任何一种方式,而是用纯代码编写的,所以用一个循环,来遍历解析Tag,其实这种方式类似于SAX解析XML,这时候上面说到的那个Flag字段就大有用途了。
这里我们还做了一个工作就是将解析之后的xml格式化一下:

难度不大,这里也就不继续解释了,这里有一个地方需要优化的就是,可以利用LineNumber属性来,精确到格式化行数,不过这个工作量有点大,这里就不想做了,有兴趣的同学可以考虑一下,格式化完之后的结果:
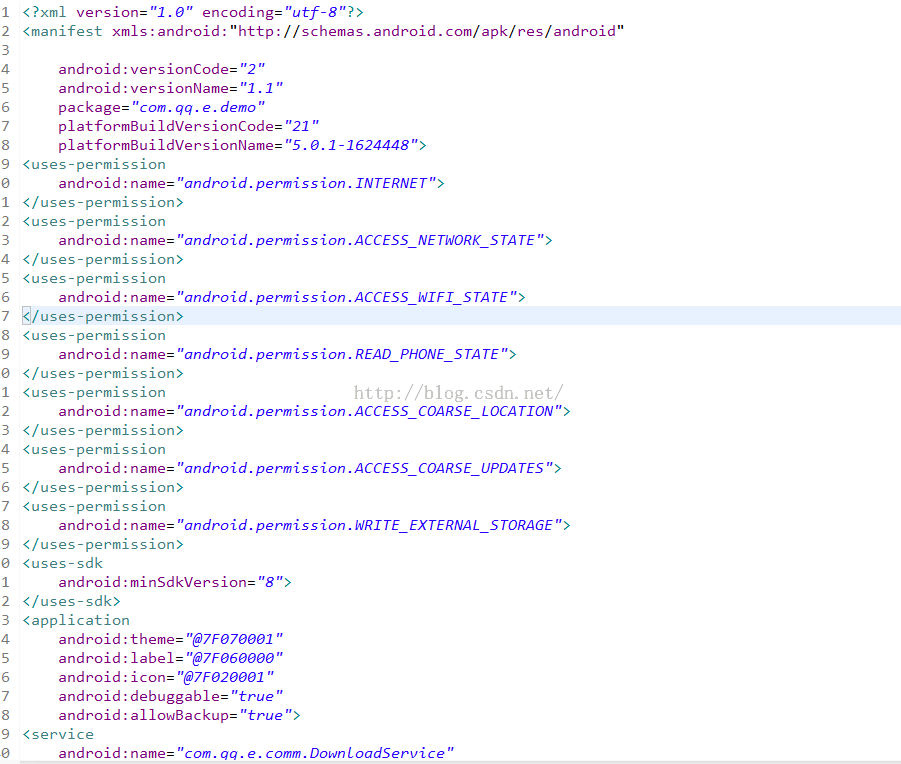
帅气不帅气,把手把手的将之前的16进制的内容解析出来了,吊吊的,成就感爆棚呀~~
这里有一个问题,就是我们看到这里还有很多@7F070001这类的东西,这个其实是资源Id,这个需要我们后面解析完resource.arsc文件之后,就可以对应上这个资源了,后面会在提到一下。这里就知道一下可以了。
这里其实还有一个问题,就是我们发现这个可以解析AndroidManifest文件了,那么同样也可以解析其他的xml文件:

擦,我们发现解析其他xml的时候,发现报错了,定位代码发现是在解析StringChunk的地方报错了,我们修改一下:
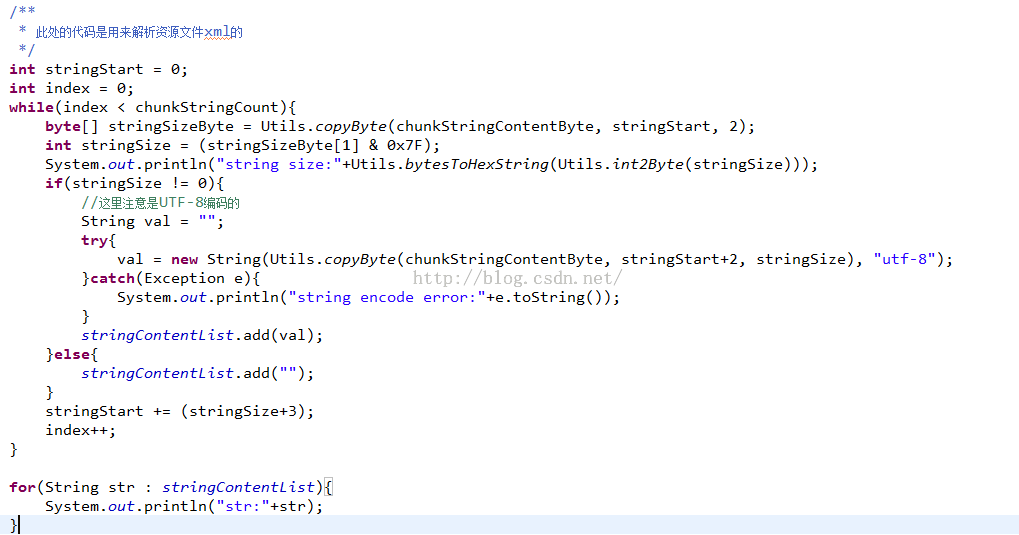
因为其他的xml中的字符串格式和AndroidManifest.xml中的不一样,所以这里需要单独解析一下:
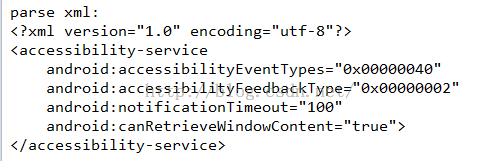
修改之后就可以了。
四、技术拓展
在反编译的时候,有时候我们只想反编译AndroidManifest内容,所以ApkTool工具就有点繁琐了,不过网上有个牛逼的大神已经写好了这个工具AXMLPrinter.jar,这个工具很好用的:java -jar AXMLPrinter.java xxx.xml >demo.xml
将xxx.xml解析之后输出到demo.xml中即可
工具下载下载地址:http://download.csdn.net/detail/jiangwei0910410003/9415323
不过这个大神和我一样有着开源的精神,源代码下载地址:
http://download.csdn.net/detail/jiangwei0910410003/9415342
从项目结构我们可以发现,他用的是Android中自带的Pull解析xml的,主函数是:
项目下载地址:http://download.csdn.net/detail/jiangwei0910410003/9415325
五、为什么要写这篇文章
那么现在我们也可以不用这个工具了,因为我们自己也写了一个工具解析,是不是很吊吊的呢?那么我们这篇文章仅仅是为了解析AndroidManifest吗?肯定不是,写这篇文章其实是另有目的的,为我们后面在反编译apk做准备,其实现在有很多同学都发现了,在使用apktool来反编译apk的时候经常报出一些异常信息,其实那些就是加固的人,用来对抗apktool工具的,他们专门找apktool的漏洞,然后进行加固,从而达到反编译失败的效果,所以我们有必要了解apktool的源码和解析原理,这样才能遇到反编译失败的错误的时候,能定位到问题,在修复apktool工具即可,那么apktool的工具解析原理其实很简单,就是解析AndroidManifest.xml,然后是解析resource.arsc到public.xml(这个文件一般是反编译之后存放在values文件夹下面的,是整个反编译之后的工程对应的Id列表),其次就是classes.dex。还有其他的布局,资源xml等,那么针对于这几个问题,我们这篇文章就讲解了:解析XML文件的问题。后面还会继续讲解如何解析resource.arsc和classes.dex文件的格式。当然后面我会介绍一篇关于如果通过修改AndroidManifest文件内容来达到加固的效果,以及如何我们做修复来破解这种加固。
六、总结
这篇文章到这里就算结束了,写的有点累了,解析代码已经有下载地址了,有不理解的同学可以联系我,加入公众号,留言问题,我会在适当的时间给予回复,谢谢,同时记得关注后面的两篇解析resource.arsc和classes.dex文件格式的文章。谢谢~~
PS: 关注微信,最新Android技术实时推送

- 2楼zhao_zepeng前天 17:29
- mark,周一再看
- 1楼infoworld前天 13:37
- 那么长的的内容解析的很耐心! 赞一个.
